Big data analysis and visualization for NASA NEX

Authors – Aashish Chaudhary (PI), Petr Votava (NASA, CO-I), Chris Kotfila, Michael Grauer, Jonathan Beezley, Andrew Michaelis (NASA), Dr. Rama Nemani (NASA, Chief Scientist)
Background – NEX is a collaborative platform that brings together a state-of-the-art computing facility with large volumes (hundreds of terabytes) of NASA satellite and climate data as well as number of modeling and data analysis tools and services. In order to facilitate a broader community engagement, NEX has deployed a cloud component – OpenNEX, which provides access to a number of NASA datasets together with tools and services, hands-on tutorials and documentation.
Technical Objective – The goal of this project is to develop capabilities for an integrated collaborative petabyte-scale Earth science data analysis and visualization environment. We will deploy this environment within the NASA Earth Exchange (NEX) in order to enhance existing science data analysis capabilities in both high-performance computing (HPC) and cloud environments. This system will significantly enhance the ability of the scientific community to accelerate transformation of Earth science observational data from NASA missions, model outputs and other sources into science information and knowledge. We propose to develop a web-based system that seamlessly interfaces with both HPC and cloud environments, providing tools that enable science teams to develop and deploy large-scale data analysis and visualization pipelines and enable sharing results with the community. The HPC component will interface with the NASA Earth Exchange (NEX), a collaboration platform for the Earth science community that provides a mechanism for scientific collaboration, knowledge and data sharing together with direct access to over 1PB of Earth science data and 200,000-cores processing system.
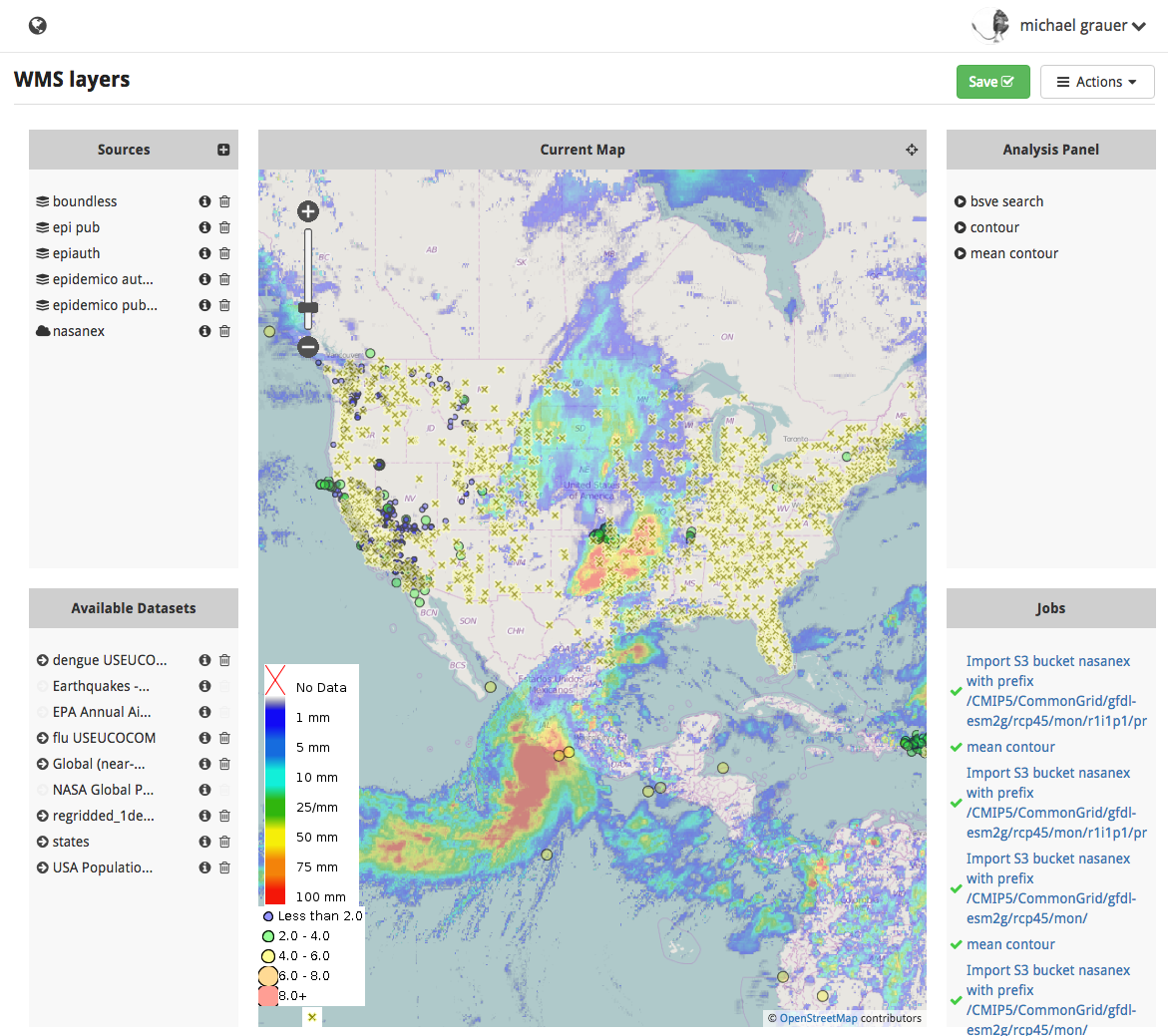
Figure 1: Minerva screenshort showing NASA’s global precipitation dataset and other layers in GeoJS
Architecture – NASA already maintains a wide array of data on Amazon’s S3 service (https://aws.amazon.com/nasa/nex/). This makes the AWS EC2 cloud infrastructure a natural choice for deploying custom clusters for batch and interactive data processing. Our approach provides a custom web-based interface leveraging a number of technologies in the [Resonant] (http://resonant.kitware.com/) stack. These include Girder for data management, Romanesco for asychronous workflow execution and most importaintly Minerva and GeoJS for visualization. This stack is deployed to an ‘always on’ cloud server that provides user authentication and persistent session based access to the geospatial analytic and visualization tools.
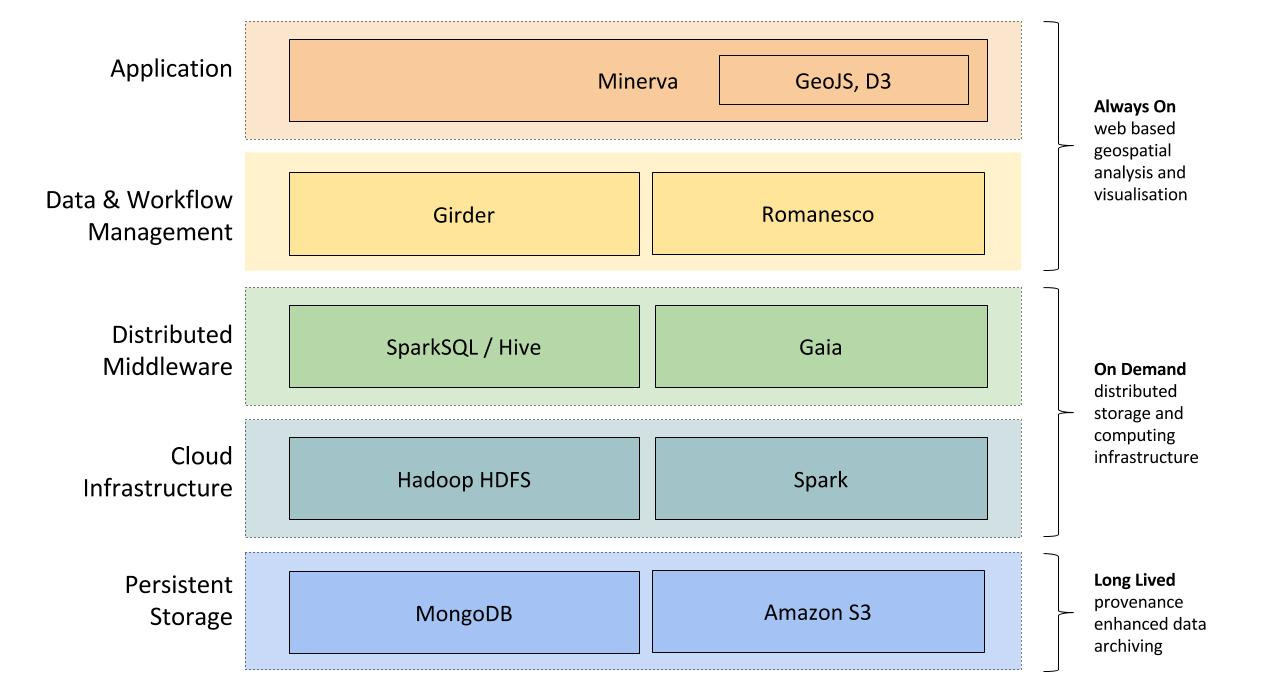 Figure 2: Minerva / Kitware-NEX open source tools stack and architecture.
Figure 2: Minerva / Kitware-NEX open source tools stack and architecture.
When large scale distributed data analysis pipelines are required, Minerva will provide management tools for interfacing with existing HPC resources as well as launching “On Demand” scalable preconfigured clusters that leverage Hadoop HDFS and Spark for distributed short-term storage and computing.
In the next few blogs, we will describe more of our work on Minerva application and big data use-cases that we are solving that involves running analysis on terabytes of datasets on cloud instances.
Acknowledgement – We are thankful to NASA’s Science Mission Directorate, NASA Headquarters for providing this opportunity.