Data Quality Is A Crucial Component Of Ethical AI

Laying the groundwork: Why AI needs data
It’s been just over ten years since the deep learning ‘revolution’ was launched by Krizhevsky et al.’s NeurIPS ImageNet paper. The ImageNet challenge was to classify an image into one of 1000 known classes, by training a model on hundreds of images per class. Previous winners were systems that had been meticulously constructed by connecting various components into pipelines combining image processing and classification. These components were themselves individual research areas focused on specific tasks such as feature descriptors (SIFT), detectors (HOG), and classifiers (SVM). They all shared the following characteristics:
- Expert human engineering was needed to select the components in the end-to-end pipeline from pixels to labels.
- The individual components didn’t have a huge number of parameters– there weren’t too many “knobs to turn”, and some adjustments had to be made by hand.
Typically, each year, the winners beat the previous winners by margins of 2% or 4%. Krizhhevsky’s system won by a margin of 8.7% (17.0% vs 25.7%, lower is better) with a single end-to-end system – a convolutional neural network, or CNN – that had 60 million parameters. That’s sixty million knobs to turn. And most importantly, the system automatically learned good values for all of those parameters.
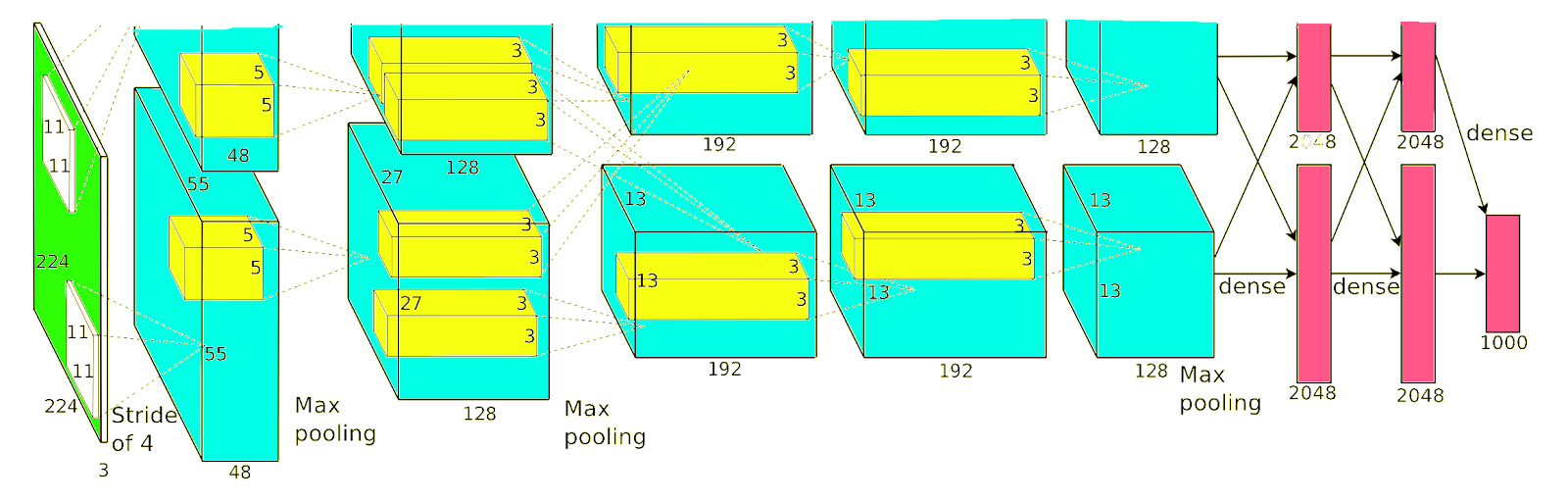 |
| Krizhevskey et al.’s CNN. Images enter the pipeline as an array of pixels in the green layer on the left; label confidences emerge at the right. |
How did they do it? Their approach included two features still current in AI research:
- Massive quantities of labeled data are used to train the network, via
- Heavy use of GPUs, whose highly-parallel architectures happen to be very efficient for the mathematical operations required to train the network.
Their work dramatically shifted the direction of AI research– rather than designing, selecting, and combining discrete components with specific roles such as feature descriptors and classifiers, researchers focused instead on new CNN pipeline architectures.
After 2012, AI systems traded the superior generalizability of a system with tens of millions of parameters with the need for huge amounts of data to set those parameters in training. The “space” of what AI could accomplish– images that could be classified, voices that could be recognized, text that could be translated– had vastly increased, but at the cost of requiring much larger amounts of labeled data to train the systems to move in those expanded spaces.
Data impacts the quality and accuracy of AI
“Good data” is a crucial component of ethical AI. Even the DoD recognizes this fact in its five principles for ethical artificial intelligence, where at least one (“Equitable: The Department will take deliberate steps to minimize unintended bias in AI capabilities”) can be directly tied to dataset issues. Here’s why:
While modern AI systems are still pattern recognition systems, what sets them apart from their predecessors is their superior (sometimes seemingly magical) ability to generalize what they’ve seen to new inputs. If you train a system with a hundred images of a school bus, and it succeeds in labeling a new image as a school bus, that’s because the system has learned some form of abstraction present in those hundred training images– whatever is visually common across those hundred school buses has been incorporated into the settings of those millions of knobs.
But these are still computers, and the GIGO principle still applies; you need to make sure those hundred images are actually school buses. If something goes wrong in your labeling system and some of your school bus images are labeled “palm tree,” then a model trained on those images will sometimes misclassify a palm tree as a school bus.
Unfortunately, data errors are inevitable at the scale of modern datasets. Research has shown that common machine learning datasets have about a 3.6% error rate. And it doesn’t end there – data can be correctly labeled and still cause problems. For example, if all your training images are of school buses facing the right with a school building in the background, the system may not recognize school buses facing the left or located on the highway. Also, if the concept of “school bus” is too broad, and includes any vehicle used to transport students, the system may fail to distinguish traditional school buses from other vehicles, e.g., minivans or tour buses.
Bad data, biased AI, and unethical outcomes
A great example of how bad data can result in unethical AI outcomes is described in the 2016 New York Times article, “Artificial Intelligence’s White Guy Problem.” This article explores several instances of publicly deployed AI systems failing in ways that were offensive, perpetuated inequality, and, ultimately, damaged trust in AI and the reputations of the companies providing AI-based services. Although the specific causes of the cases in the article aren’t revealed for proprietary reasons, many of the issues involving the recognition of humans in photographs or video could have likely been addressed by increasing the diversity of the training data.
How does Kitware mitigate bias in our data?
Similar to the software engineering maxim that “security must be designed in at the start, rather than added on at the end,” the best time to address dataset bias is in the design stage. In the Intelligence Advanced Research Projects Activity (IARPA) DIVA and BRIAR programs, we collected videos of large numbers of human subjects (approximately 150 and 250, respectively). In both projects, our actors were supplied by a third-party vendor specializing in role players for various events. We proactively addressed potential demographic bias by working with the vendor to recruit actor pools matching the 2016 U.S. Census as closely as possible for age, gender, and ethnicity. In the DIVA program, which involved actors performing scripted and unscripted activities, we took additional care to ensure that activities of interest were performed by actors across demographic distributions. We also scheduled activities to rotate through geographic locations and times of day to avoid environmental bias.
For DIVA and the similar NIST ASAPS programs, we addressed dataset labeling bias by developing detailed activity definitions to reduce human-related errors caused by inconsistencies among the annotators.
Making AI more ethical
The adoption of AI and deep learning by general society makes it imperative that we try to prevent “bad” data from negatively impacting this technology. Especially when considering the ethical implications, it’s important to consider your data when using AI to prevent unintended bias. If you want to learn more about ethical AI and Kitware’s tools and best practices, request a meeting with our team.