Improved Parallel Rendering in ParaView

Proper parallel rendering of data is a complex problem. When transparency or volume rendering effects are added it becomes even more difficult to get the correct rendered image. This is because multiple processes can contribute to the proper color value for a pixel. In the past, ParaView would automatically redistribute data for unstructured grid volume rendering and surface rendering with transparency. This was a costly operation and got worse as the data set sizes as well as number of processes increased.
To improve this, Kitware collaborated with Sandia National Laboratories to allow ParaView to avoid data redistribution for image generation. This is done through the new Use Data Partitions option for render views and works for both unstructured grids and polydata. It does require that all visible data sets in the view have similar geometric data partitions. This often occurs when reading in an unstructured data set and then applying other filters on that data set (e.g. contours, slices, cuts, etc.). Since in general data sets will not have similar partitions in parallel, this option is disabled. An example use case is trying to examine a field variable along with the partitioning of the data set to see if any nefarious effects appear at the partition boundary.

By setting the Opacity of the data set and the Transform filter one can view both fields together. While this could be done before, now with using the Use Data Partitions option this can be done without costly data redistribution. The result along with the GUI option is shown in the figure below.
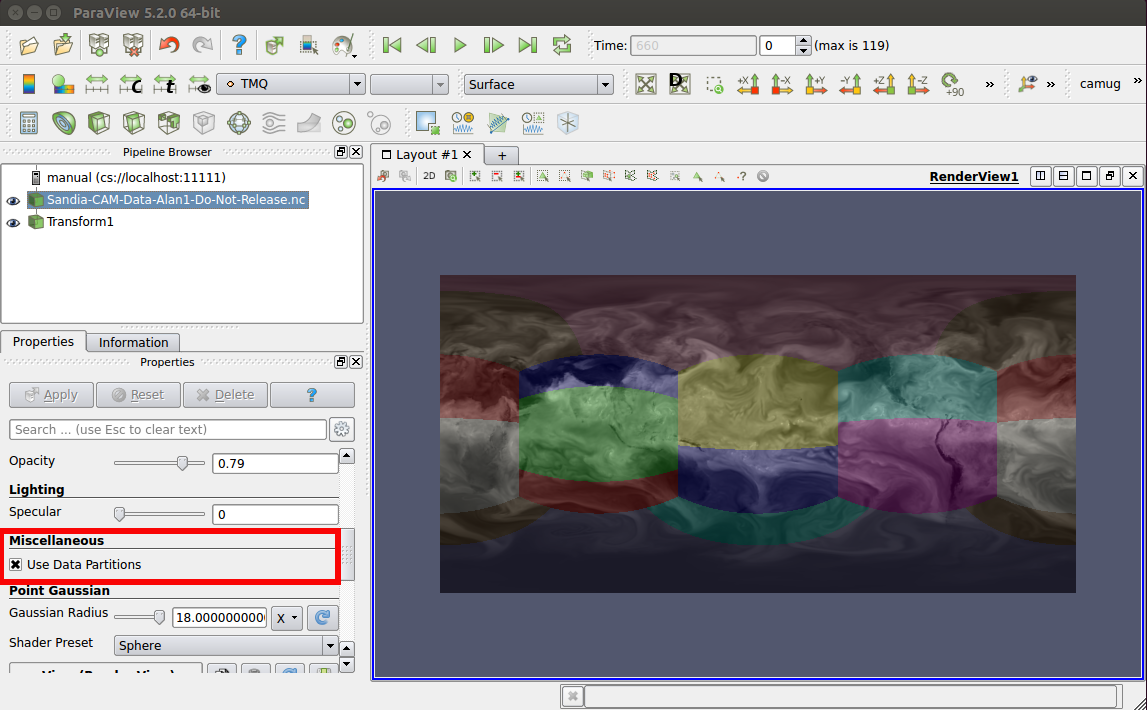
This improvement is available in the ParaView 5.2 release.