KWIVER: An End-to-End Video Analytics Toolkit

A little over a year ago at Kitware, we released the Kitware Interactive Video Exploitation and Retrieval (KWIVER) toolkit [1]. The goal of our Computer Vision team in developing KWIVER is to create a complete end-to-end video exploitation toolkit. When fully realized, KWIVER will provide tools to ingest video, stabilize it, detect movers in it, and link those motion detections into tracks. KWIVER will also provide a framework for developing analytics based on those core capabilities, leveraging a wide variety of open-source computer vision and machine learning toolkits. Currently, KWIVER’s strength lies in offering the tools required to develop analytics for video from moving cameras such as those mounted on a pan/tilt gimbal or, even more challengingly, those mounted on moving platforms such as aerial drones.
For over seven years, our efforts have focused on developing analytics for video from moving cameras. Our primary customers for this time frame include clients associated with the U.S. Department of Defense. Until just a few years ago, the U.S. military primarily owned aerial video platforms. In the last few years, however, aerial video platforms went from the subject of congressional appropriations to a hot Christmas present. We believe that KWIVER can leverage these new, exciting, and inexpensive platforms to help develop leading-edge capabilities across a wide variety of domains including agriculture, wildlife management, surveying and mapping, traffic analysis, and many others.
KWIVER faces some unique challenges. While we are dedicated to the value and utility of open-source software, government customers are understandably careful about how the technologies they fund become available to the public at large. Although they are open and sympathetic to the idea of advancing the state-of-the-art by making the results of our research available as open source, they implement a formal process in doing so. The time required to work through this process can vary dramatically, and we found that patience and cooperation generally produce the desired results.
Due in part to the time and the work required to follow this process, the KWIVER project may have seemed quiet this year. With the exception of the Motion-imagery Aerial Photogrammetry Toolkit (MAP-Tk) [2], which had a number of releases and a tutorial at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), and the Social Multimedia Query Toolkit (SMQTK) [3], which is under heavy development, most of KWIVER remains as it stood when released—a largely read-only repository of interesting code with limited immediate utility.
Recently, we received permission to release a number of key pieces of KWIVER including the Video and Image-Based Retrieval and Analysis Toolkit (VIBRANT) [4], which is a detection and tracking library and framework, and the Kitware Analytics Toolkit (KWant) [5], which is an analytic data federation and quantification library. This permission allows us to, for the first time, demonstrate an end-to-end analytic capability. While some of the pieces do not yet work together as smoothly as they ultimately will, they allow us to fully demonstrate some critical capabilities of KWIVER.
We will improve KWIVER over the course of the next year. We expect to add more documentation, examples, and code that will allow use of KWIVER in a more refined fashion. Watch the KWIVER website, read the Kitware blog [6], and join the kwiver-users mailing list [7] to keep fully abreast of developments.
In the meantime, we will take this opportunity to reintroduce some of KWIVER’s capabilities; demonstrate how to build the various parts of KWIVER; and illustrate how to use them to stabilize sample video, detect and track movers in that video, and review results using a graphical user interface (GUI) application. Hopefully, this will spark interest in KWIVER, provide an introduction to its capabilities, inspire its utilization in projects, and increase participation in its development.
KWIVER Components
Unlike other open-source projects, KWIVER does not have a single repository that contains all of the code for the project. Rather, the KWIVER repository located on GitHub [8] serves as a central location for KWIVER’s documentation. It contains sample code, utilities, tests, and other tools for the KWIVER community.
The bulk of the repository, however, consists of a CMake [9] “superbuild” that builds many members of the KWIVER family of projects. Each of these members typically has its own source code repository. In cases such as MAP-Tk, CMake builds and deals with members as single stand-alone projects. The KWIVER repository handles each of the sub-projects as a Git sub-module. KWIVER serves to combine all of its components in a way that makes their use together as convenient as possible.
Currently, the KWIVER superbuild handles the following repositories:
MAP-Tk
MAP-Tk is an open-source C++ collection of libraries and tools for making measurements from aerial video. Its initial capabilities focus on estimating the camera flight trajectory and a sparse three-dimensional point cloud of a scene.
Stream Processing Toolkit (sprokit)
sprokit [10] aims to make it easy to process a stream of data with various algorithms. It supports divergent and convergent data flows with synchronization between them and connection type checking—all with full, first-class Python bindings.
Vision Visualization and Analysis (ViViA)
ViViA is a collection of Qt-based applications for GUIs. It visualizes and explores content extracted from video.
VIBRANT
VIBRANT is an end-to-end system for surveillance video analytics such as content-based retrieval and alerts based on behaviors, actions, and appearances.
KWant
KWant is a lightweight toolkit for computing detection and tracking metrics on a variety of video data. It computes spatial and temporal associations between data sets, even with different frame rates. It has a flexible input format and can generate eXtensible Markup Language (XML)-based results.
vital
vital is a core library of abstractions and data types. Various KWIVER components use vital.
Additionally, a separate repository, called Fletch [11], is a CMake-based project that assists with acquiring and building common open-source libraries for developing video exploitation tools. (Why Fletch? The verb fletch means “provide (an arrow) with feathers for flight“ [12], and of course, arrows are kept in quivers.)
This article concentrates on the capabilities of KWIVER related to aerial video analytics. KWIVER does have other core capabilities. For example, SMQTK provides search and retrieval capabilities for data sets related to social media images and video.
Fletch
At its core, KWIVER is a cross-platform project. The goal is to make KWIVER fully useful on Linux, Mac OS, and Windows systems. This, of course, presents an immediate challenge. KWIVER leverages a broad collection of open-source projects across a wide variety of domains. On Linux systems, a simple apt-get or yum install makes many (but not all) of these projects available. Similarly, on Mac OS, Homebrew or MacPorts package managers makes many (but again, not all) of these projects available.
Windows systems tend to present an even more difficult challenge. Fletch simplifies things and provides a reliable source of all of the packages that KWIVER and its components require. Fletch is a CMake-based superbuild. What this means is that it has a top-level CMakeLists.txt file that can configure a Fletch build for specific projects.
Fletch also provides a CMake variable, fletch_ENABLE_ALL_PACKAGES, which tells Fletch to build every package that it knows. Once configured, Fletch contains CMake modules that know how to build all of the packages requested and download the packages from their respective websites. In addition to building the packages, Fletch ensures that the packages know about each other. If, for example, Fletch has ZLib and Qt packages enabled, the Qt package will build and link against Fletch’s copy of ZLib, and so on.
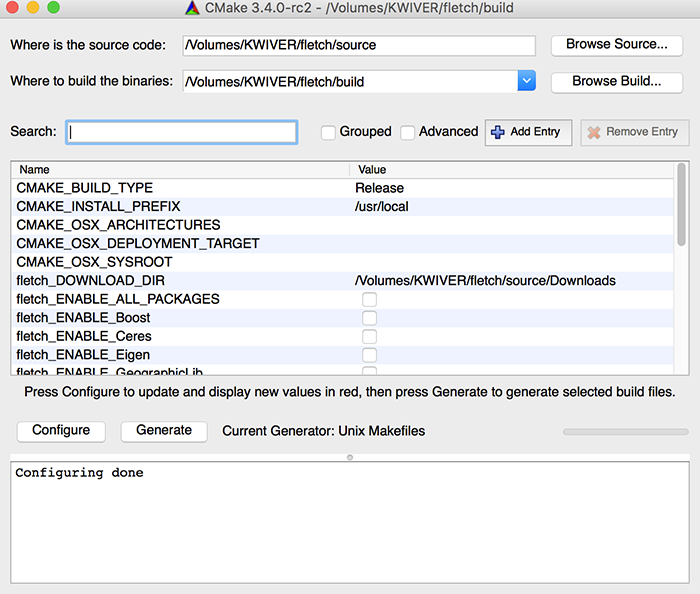
Fletch builds much like any CMake project. The first step involves configuring the project and deciding which of the toolkits to build, using the CMake GUI tool (usually called cmake-gui) as shown in the below figure:
Another route entails selecting the appropriate options on the command line through the CMake tool. For example, the following command configure builds Fletch with the default build environment (e.g., Unix Makefiles on Linux platforms):
cmake -Dfletch_ENABLE_ALL_PACKAGES:BOOL=TRUE ../source
Implementing the make command then builds the project, since CMake creates the appropriate makefile build files. Another choice is to utilize the cmake –build . command. CMake will try to do a command-line build for the generator used.
Building KWIVER
To get started with building KWIVER, the first step is to clone the KWIVER repository on GitHub:
git clone git@github.com:Kitware/kwiver.git
As noted earlier, the KWIVER repository serves as a superbuild for a collection of projects that it can configure to work together. KWIVER manages these projects as Git sub-modules and requires fetching as well:
cd kwiver git submodule update --init
This will fetch all of the other projects associated with the KWIVER build and checkout the version of those projects tested together within the KWIVER superbuild.
After the checkout completes, following the usual CMake build steps will build the KWIVER project. The KWIVER build uses the packages built by Fletch. Thus, the KWIVER build must know the location of the intended Fletch build. Setting the variable fletch_DIR to point to the directory in which Fletch built accomplishes this.
Selections within the KWIVER build turn on or off any of the optional KWIVER sub-components. Building all of KWIVER means setting the CMake variable kwiver_ENABLE_ALL_PACKAGES to TRUE. As with Fletch (and any CMake project), there are a number of ways to configure the project. The simplest uses a cmake command on the command line, such as the following:
mkdir build cd build cmake -Dfletch_DIR:PATH=~/Projects/KWIVER/fletch/build -Dkwiver_ENABLE_ALL_PACKAGES:BOOL=TRUE <kwiver source directory>
Once the KWIVER configuration completes, a make command can build KWIVER on Unix-style systems such as Linux or Mac OS X. Another option is to open the Visual Studio project, and build on a Windows system.
The above provides a fairly quick overview of how to build Fletch and KWIVER using CMake. For more details, consult the project documentation available through the KWIVER website and the CMake website.
After building everything, ensuring to source the setup_KWIVER.sh (or setup_KWIVER.bat on Windows machines) file in the install directory of the build directory puts the various KWIVER tools on the PATH and makes certain that the KWIVER applications can find their libraries and other data files.
Using KWIVER for Video Analytics
The following example uses a variety of KWIVER-based tools and techniques to compute and visualize detection and tracking analytics on full motion video (FMV). This includes pre-processing the data to subtract out the camera motion, detecting moving objects within the video, and linking those detections together into tracks. Finally, the example demonstrates how to visualize the results using one of the video analytics applications available through KWIVER’s ViViA project.
Utilizing Test Data
KWIVER’s website (http://www.kwiver.org/TestData) contains download instructions for the data used in this example. The data set of interest is kwiver_fmv_set_1. The test data does not include individual images and metadata (camera position, time of day, etc.) in the video.
Three sub directories make up the test set: an images directory that contains the actual data, a KWIVER Archive (KWA) directory, and a Tracks directory. These make convenient locations for the output that KWIVER will generate.
Creating KWIVER Archive Files with MAP-TK and sprokit
Generating a special format video file called a KWA file allows for use of the KWIVER GUI applications that are part of ViViA. A KWA file contains all of the frames of a given video stored in a way that provides for easy and efficient random access to any frame in the video. The file also stores information about the frames, such as the frame homographies. Homographies are the mathematical relationship of one frame’s pixels to another frame’s pixels. The ViViA applications (and the various analytics applications) use these homographies for many purposes. In particular, they use homographies to compensate for camera motion. This means that when drawing a tripwire (a line that generates an alert if someone crosses over it) in a scene, the ViViA application can ensure that the tripwire stays in the same position in the scene, even if that position moves across the frame as a result of camera motion. In addition, the tracking application can ignore apparent motion generated by the movement of the camera so that the application can focus on detecting people and vehicles moving within the scene.
When trying to produce analytics on video scenes that involve moving cameras, such as those captured when taking video from an aerial drone like a quad copter, computing these homographies constitutes a critical first step. Fortunately, KWIVER (using MAP-Tk) provides services to do just that.
To make it easy to generate the necessary KWA files, Kitware created a sprokit pipeline. sprokit is another component of KWIVER and a plug-in-based pipeline framework. It excels when processing a lot of data in a sequential fashion (like the frames of a video) and when such processing involves a lot of sequential steps. Since KWIVER focuses primarily on video analytics, sprokit is a core part of KWIVER’s architecture. KWIVER adapts the capabilities of its various sub-projects (e.g., MAP-TK, VIBRANT, and KWant) as sprokit plug-ins to assemble them into useful and interesting processing chains.
In its simplest form, the pipeline_runner runs a pipeline defined in a text file called a pipeline configuration file. Such a configuration file in the KWIVER repository is kwiver_util/pipeline_configs/images_to_kwa.pipe.
The heart of the configuration is actually at the end of the file, and it looks something like this:
connect from input.timestamp to stabilize.timestamp connect from input.image to stabilize.image connect from stabilize.homography_src_to_ref to writer.homography_src_to_ref connect from input.timestamp to writer.timestamp connect from input.image to writer.image
What this tells sprokit is that the pipeline consists of three processing elements: an input element; a stabilize element, which computes the homographies; and a writer element, which writes out the KWA files. Connecting an element’s output port with another element’s input port joins the elements. For example, the stabilize element has an output port called homography_src_to_ref, which connects to the writer’s homography_src_to_ref input port. The whole pipeline looks like this:

The remainder of the pipeline file configures each of the elements. For instance, the input element needs to know what images to read, the writer element needs to know where to write the KWA files, and so on. The key elements to adjust are as follows.
Input
Under the process input section, the following line must contain the correct location of the image_list.txt file in the test data set.
:image_list_file image_list.txt
Choices include an absolute or a relative path (from where to run pipeline_runner).
Writer
Under the process writer section, the following line must point to a directory in which to write the KWA files.
:output_directory ../KWA/
Again, it is important to specify an absolute or a relative path.
The directory that stores the data set’s images runs the checked-in version of the .pipe file without requiring any changes. Once properly configured, the next step calls for running the pipeline:
pipeline_runner -p /path/to/images_to_kwa.pipe
This will take some time to process and write status messages to the console. When the processing completes, the specified directory will contain the KWA files needed to visualize the analytic results.
Detecting and Tracking Movers with VIBRANT
After processing the test data set and producing the KWAs that the KWIVER GUI applications will need, it is time to generate analytics on the video and review them with those applications. In this case, VIBRANT detects and tracks the moving objects in the scene (either people or vehicles). In the future, Kitware plans to adapt VIBRANT’s detection and tracking algorithms to work as sprokit components. For now, VIBRANT provides a stand-alone executable that reads images and generates a track file. The executable is vibrant_detect_and_track_async.
Similar to the sprokit pipeline used earlier, vibrant_detect_and_track_async requires a configuration file. The KWIVER source tree contains this file at Packages/vibrant/tools/config_files/kwt_kwiver_fmv_set_1.conf. The file configures VIBRANT’s detection and tracking capabilities for this particular data, which comes from a publicly available data set called AP Hill (for the location of its collection).
Like the .pipe file used earlier, this file is checked in so as to allow it to run without change from the images directory in the test data set. Running a different configuration requires a change to the line so that it properly specifies an absolute or a relative path to the image_meta_list.txt file included in the images directory.
src:image_metadata_list:file = list.txt
The following syntax runs the command:
vibrant_detect_and_track_async -c /path/to/kwt_kwiver_fmv_set_1.conf
As happened when running pipeline_runner, this command will run for some time, generating logging output. When the run completes, the Tracks directory stores a track file, called tracks_terminated.kw18, next to the images directory where the run occurred.
Reviewing Results with ViViA
After producing analytics, ViViA reviews the results using an application called vsPlay. vsPlay makes interacting with videos possible in a manner similar to a normal video player for watching movies. However, vsPlay can overlay analytics—in this case tracks—on a video. In addition, it has facilities for drawing annotations on the video. These facilities leverage the homographies produced earlier so that they stick to the ground where drawn. vsPlay also has facilities for filtering and adjusting the way the analytics display.
Providing arguments on the command line runs vsPlay by telling it the locations of the KWA file and the track analytics file produced earlier. This command assumes that the images directory in which the other commands run also runs vsPlay:
vsPlay -vf ../KWA/kw_archive.index -tf ../Tracks/tracks_terminated.kw18
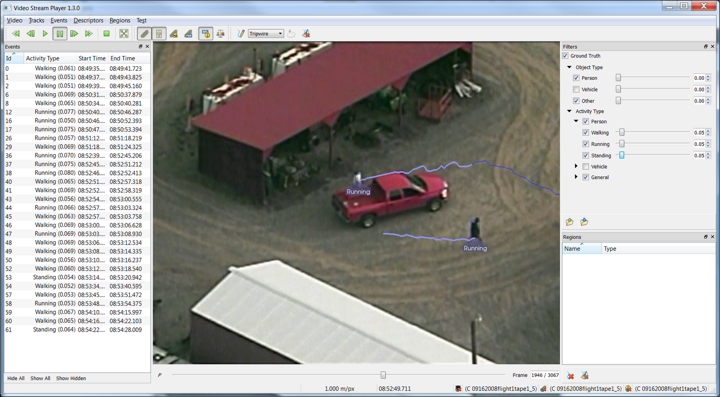
This brings up the user interface seen here:
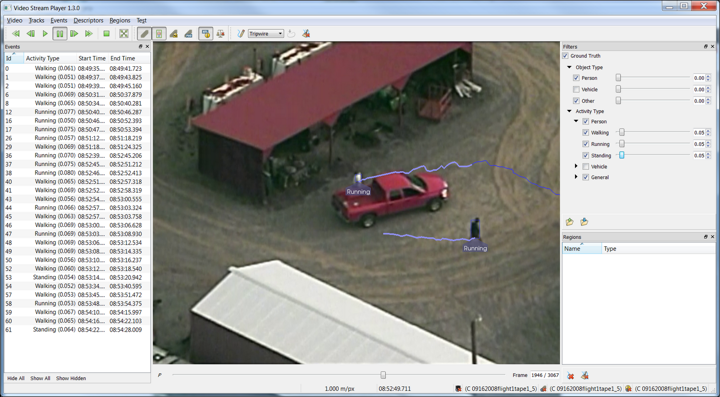
The upper left displays the standard media controls that allow for playing, stopping, pausing, and rewinding the video. Under the Tracks menu, it is important to make sure to check the Show Tracks menu item. Accordingly, as the video plays, it will present trails associated with most of the movers, showing where the detection and tracking from VIBRANT found people and vehicles moving in the scene.
The vsPlay application is a very feature-rich application. To learn more about ViViA, read “ViSGUI: A Visualization Framework for Video Analytics” [13]. (VisGUI is the former name of ViViA.) Also see the vsPlay user’s manual in Packages/vivia/Documentation/User Manuals/vsPlay.rst.
Conclusion
Now that we released what we consider to be the core components of KWIVER, we will work hard to improve them and make them more useful to the community at large. We will add more documentation and write blog posts to show how to do other interesting things with KWIVER. We will also adapt more of the KWIVER technologies as sprokit elements to provide for building bigger, more flexible, and more capable pipelines. For example, we will adapt the core elements of the vibrant_detect_and_track_async application to enable configuration within the same pipeline as the KWA pipeline. We will also add other new capabilities.
To stay posted on developments in KWIVER, keep an eye on KWIVER’s website, and subscribe to the mailing list. Finally, KWIVER is an open-source project. We welcome pull requests and look forward to combining efforts to make KWIVER as useful as possible to the community at large.
References
[1] Kitware, Inc. “Tackle challenging image and video analysis problems with KWIVER.” KWIVER. http://www.kwiver.org.
[2] GitHub, Inc. “Kitware / maptk.” GitHub. https://github.com/Kitware/maptk.
[3] GitHub, Inc. “Kitware / SMQTK.” GitHub. https://github.com/Kitware/SMQTK.
[4] GitHub, Inc. “Kitware / vibrant.” GitHub. https://github.com/Kitware/vibrant.
[5] GitHub, Inc. “Kitware / kwant.” GitHub. https://github.com/Kitware/kwant.
[6] Kitware, Inc. “Kitware Blog.” Kitware. http://www.kitware.com/blog.
[7] Kitware, Inc. “Mailing List.” KWIVER. http://www.kwiver.org/mailing-list.
[8] GitHub, Inc. “Kitware / kwiver.” GitHub. https://github.com/Kitware/kwiver.
[9] Kitware, Inc. CMake. https://cmake.org.
[10] Github, Inc. “Kitware / sprokit.” GitHub. https://github.com/Kitware/sprokit.
[11] GitHub, Inc. “Kitware / fletch.” GitHub. https://github.com/Kitware/fletch.
[12] Oxford University Press. “Definition of Fletch in English.” Oxford Dictionaries. http://www.oxforddictionaries.com/us/definition/american_english/fletch.
[13] Aashish Chaudhary et al., “VisGUI: A Visualization Framework for Video Analysis.” Kitware Source, October 2012.

Keith Fieldhouse joined Kitware in May 2010 as a research and development engineer. He soon became a Technical Lead for his contributions and leadership across multiple projects on the Computer Vision team. These include the Defense Advanced Research Projects Agency’s (DARPA’s) Persistent Stare Exploitation and Analysis System (PerSEAS) and Video and Image Retrieval and Analysis Toolkit (VIRAT) efforts. Keith continues to provide technical and project leadership on multiple efforts, such as the Air Force Research Laboratory’s Data-To-Decisions program. Keith specializes in large system design and
integration.