Teaching Open Source

This year, for the first time during the Spring semester, we are teaching the Open Source Software Practices course at the Rensselaer Polytechnic Institute. The course has traditionally only been offered during the Fall. This is the sixth edition of the course and with 30 students registered, we had to move to a larger classroom after the second week.
This year we are emphasizing (a) Community management, (b) Economics, and (c) Applications of Open Source in Healthcare. One of the topics in particular is discussion of the importance of growing the size of a community to the right scale where the networking effects of the open-source software peer-production model become effective. For example, only with sufficient participants do we get to benefit from the virtues of the Linus Law: “Given enough eyeballs, all bugs are shallow”.
Our estimation is that a project needs one developer per every 1,000 lines of code in order to remain healthy. For example, a project with 800,000 lines of code would require at least 800 developers to take care of it. These 800 developers will not be full-time dedicated developers of course; rather, they follow the typical power-log distribution in which 20% of the developers make 80% of the contributions, and the large majority of the developers make contributions very occasionally. Figure 1 shows this type of power-log distribution for the Insight Toolkit. The vertical axis is the number of commits, while the horizontal axis is the list of developers ranked by their number of commits. In this particular case, 10% of the developers have made 80% of the commits.
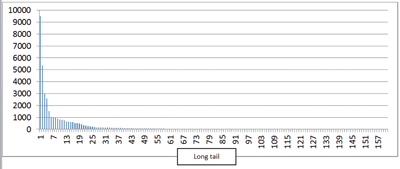 Figure 1: Statistics of number of commits per developer in ITK
Figure 1: Statistics of number of commits per developer in ITK
It is common to make the mistake of thinking that this 10% is more important than the rest of the community, underestimate the role of the long-tail 90%, and ultimately fail to bring the project to the operating regime in which the network effects of open source pay off. This concept of a required critical mass of contributors leads us to insist in that the most important behavior of well-managed open-source projects should be the continuous recruitment of new developers, regular efforts for retaining existing well-behaved developers, and converting the not so well-behaved ones. To achieve this, the class regularly discusses the motivations that drive developers to make contributions to a project, and how project gardeners must ensure that those motivations are nurtured in the community. In particular, community gardeners must focus on the essential trilogy of: autonomy, mastery, and purpose.
The economic perspective is used again in this edition of the course to illuminate the basic properties of peer-production systems, and to clarify why open-source software projects are highly efficient at the production of knowledge-based goods and services. This perspective also provides context for the cost-benefit analysis in which the creation of monopolies, such as copyrights and patents, has to be balanced against the social and economic costs that they impose to society; particularly how they restrict the pool of resources available to the next generation of creators. With a background on the economics behind open-source and references to Kitware’s experience, the class covers the key elements needed to build successful business models including removal of barriers to the flow of knowledge and information, creation of collaboration platforms, focus on services and support, and agile programming processes that rely on rapid iterative cycles of development and customer interactions.

As a class project, the students are being introduced to VistA, the Veterans Health Information Systems and Technology Architecture, and are making contributions to the Code Convergence effort of the project. To this end, the students are learning the “M” language. This is a great teaching instrument because it has helped to put all students on a level playing field, where they are learning the language together and we can focus on the open source aspects of the project, instead of drifting into a pure programming class.
This semester we are also using “Moodle”, the Open Source Course Management System, for the second time. This has streamlined the execution of quizzes, assignments, and class activities into a single platform. As part of the practical exercises in the class, students are being introduced to the use of the distributed revision control system Git, the issue tracker MANTIS, the code review system Gerrit, and virtual machines. These are all part of the set of tools that create the communications and coordination infrastructures that allow large communities of contributors to work together to further the goals of a project.
The class also benefits from a diverse set of invited speakers including Conor Dowling (Caregraf), Marc Natter (Children’s Hospital, Indivo Project), Christy Collins (M-CM), Richard Fontana (Red Hat General Counsel), and David Wheeler (Institute for Defense Analysis).
The combination of practical software tool exercises, with invited speakers, and essential reading from authors such as Eric Raymond, Yochai Benkler, Lawrence Lessig, James Boyle, Steven Weber, and Larry Rosen, is intended to provide a balanced background with which the students will be well prepared to participate and promote the development of open-source projects and craft profitable business models around them.
Practice and Code Convergence
Since the course started in 2007, one constant challenge has been identifying mechanisms for engaging students in real-life, direct experiences with open-source software projects. We initally expected that this aspect of the course was going to be trivial. The initial thought was to simply direct students to identify a project to participate in and we expected that involvement would rapidly follow after they knocked at the doors of any open source community. It turned out however, that in the initial attempts, the experiences of the students were widely diverse. Some of them started their own projects, some attempted to join small projects with communities of two-to-four developers, and others went after large established projects. Each one of those approaches led to the following drawbacks:
Starting your own project. This is the exciting option where students can craft the project to their preferences. However, in this case, what we observed is that students get to be too focused and too busy with the initial design and coding of the project that they don’t get to be exposed to the variety of experiences that were sought in this exercise. In particular, they don’t get to interact with a community of fellow developers, nor a community of users; they don’t get to appreciate the full power of revision control as the mechanism for maintaining the technological and social history of the project; and they miss out on the opportunity to appreciate the importance of documentation, bug tracking, and software quality process. From all these limitations, probably the worst consequence is that they propagate the misconception that “development” is what matters most in software; that the final software can be a finished product and that open source is simply posting your code on-line once “you are done”. In reality, we know that design is only about 2% of the total cost of ownership (TCO) of a software project, writing the code is about 7%, and that the lion’s share is maintenance, and that accounts for 67% of TCO.
Joining a small project. This is the case where students attempted to join existing projects with a current crew of two-to-four developers. In these cases, we found that the attention of the developers was sporadic and there was not enough activity to expose the students to the full range of behaviors and technologies that the course was covering. These projects are typically more prone to a governance model of a “benevolent dictator,” which means that newcomers are at the mercy of being aligned with the vision of the main developer, or to end up clashing with that vision.
Joining a large project. In these cases, students joined the developer community of a well-established project and started making contributions to the code. What we found is that many open-source projects have not done enough to facilitate and expedite the engagement of newcomers to their communities. This came as a revelation about our own projects; for example, in ITK, it taught us a lot about the ramps that we were missing to offer to new developers to facilitate their rapid and painless engagement in the community. It turns out again that many projects are so focused on the technology and the engineering of the code that they tend to forget the human and social aspect of their communities. Only a handful of projects have active initiatives for recruiting new developers and training them in the culture and practices of their community. This is a positive criticism to open-source projects, and one from which we learned a valuable lesson that we have applied to our own projects.
As a result of these experiences, recent editions of the course have used a more controlled approach in which the students are now required to participate in a large-scale, open-source project, and to engage in directed activities mentored by existing developers. In the particular case of the last two editions of the course, students have been working with VistA and making contributions to the community of the Open Source EHR (http://www.osehra.org).
There have been multiple advantages to the choice of this project: (a) the higher purpose of contributing to a project of great social and economic importance, (b) the participation in the engineering challenges of a project of large dimensions, and (c) a level playing field where all the students have to learn the “M” language and familiarize themselves with the particularities of the project.
On the front of learning the “M” language, students were exposed to two introductory lessons on M programming, and then worked together on writing an M tutorial using a distributed model of peer-production. The content of the tutorial is hosted in a publically-available Git repository (https://github.com/OSEHR/M-Tutorial), and the generated material is posted online for all users looking to learn M (http://www.opensourcesoftwarepractice.org/M-Tutorial/).
 Students are also making a transformative contribution for solving one of the critical challenges of the VistA community. The fact that the code base of VistA has been forked on multiple occasions by multiple organizations, and as a result the attention and focus of the larger community has been fractured and divided into maintaining each one of the individual forks. Given the large size of the VistA code base, about 2.5 million lines of M code, it is counterproductive to have a fractured community. Reunifying these communities and regrouping them around a single code base is one of the critical transformations that will lead to realizing the benefits of the open-source, peer-production economic model.
Students are also making a transformative contribution for solving one of the critical challenges of the VistA community. The fact that the code base of VistA has been forked on multiple occasions by multiple organizations, and as a result the attention and focus of the larger community has been fractured and divided into maintaining each one of the individual forks. Given the large size of the VistA code base, about 2.5 million lines of M code, it is counterproductive to have a fractured community. Reunifying these communities and regrouping them around a single code base is one of the critical transformations that will lead to realizing the benefits of the open-source, peer-production economic model.
To this end, multiple organizations are working together on guiding the students through the exercise of analyzing the differences between the multiple VistA distributions, including: WorldVista, OpenVista, vxVista, and Medsphere. To facilitate this goal, Conor Downling of Caregraf has developed a semantic analysis of the multiple instances by taking advantage of VistA’s self-description capabilities (http://www.caregraf.org/semanticvista/analytics).
This system uses a query language to retrieve information describing the schema of the underlying database and the specific versions of the code patches that have been applied to the systems deployed in production. Students have compared source code routines between the various distributions, and become familiarized with the use of Git, the MANTIS issue tracker and the code review system Gerrit.
The participation in a large-scale project, under active mentorship of experienced developers provides a better guarantee of consistently exposing students to the social, cultural, and technological aspects of participating in an open-source software project. This indeed also prepares them better for one of the most likely activities that they will engage in once they join the job market.
 Luis Ibáñez is a Technical Leader at Kitware, Inc . He is one of the main developers of the Insight Toolkit (ITK). Luis is a strong supporter of Open Access publishing and the verification of reproducibility in scientific publications.
Luis Ibáñez is a Technical Leader at Kitware, Inc . He is one of the main developers of the Insight Toolkit (ITK). Luis is a strong supporter of Open Access publishing and the verification of reproducibility in scientific publications.