VisGUI: A Visualization Framework for Video Analysis

The visualization capabilities offered by current tools for vision datasets are limited in many ways, hindering the ability of researchers to quickly inspect image and video data and verify algorithmic results. Therefore, we developed VisGUI; a novel, high-performance, extensible, and cross-platform framework, which offers various ways to visualize and analyze vision datasets in an effective and efficient manner. VisGUI is built on top of Qt [1] and VTK [2], sophisticated and mature cross-platform frameworks, and is described in detail in subsequent sections.
We recently received approval for the public (open-source) release of the VisGUI framework. We’re currently in the process of preparing its release, which is expected before the end of 2013.
Design and Implementation
Figure 1 shows the overall architecture of VisGUI. The core dependencies of VisGUI are Qt and VTK; lesser dependencies include other toolkits such as VXL, VIDTK, PROJ4, GDAL, GeographicLib, and KML. The VisGUI architecture primarily consists of a model-view framework, a scene graph, GUI elements, and a testing framework.
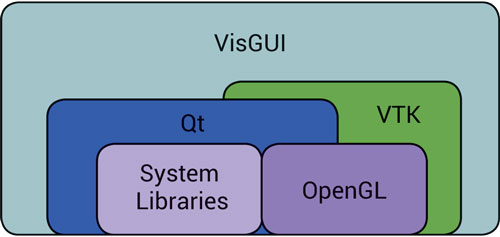
Figure 1: VisGUI Architecture
Model-View Framework
VisGUI uses a VTK-based model-view framework, separating the domain logic from the visual representation. This separation enables the creation of different representations for the same underlying data and rendering optimizations where only the data required for rendering is passed to the representation. Figure 2 shows a list of the models and representations available within the VisGUI framework.
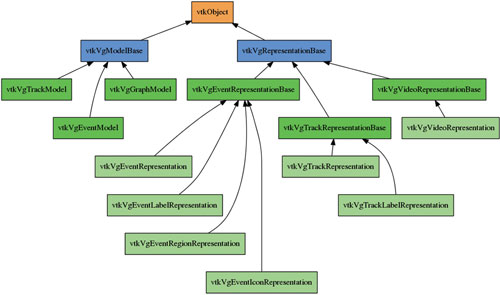
Figure 2: Class hierarchy of VisGUI model-view framework
Scene Graph
The map view of Viqui (discussed later) contains video results and other related visual entities that are spatially and temporally bonded to each other. Since this relationship can be described by a scene graph data structure, we created a VTK-based scene graph in which leaf nodes represent visual entities such as a track or video in the scene. These leaf nodes are comprised of at least one data model and one-or-more data representations. The scene is rendered by performing a depth-first traversal.
GUI Extensions
The application code within VisGUI primarily consists of VTK rendering elements within a Qt infrastructure. QtExtensions is a set of classes that extend Qt by providing useful features such as a command-line parser, real-number slider widget with arbitrary precision, helper classes for application configuration management, and a unit testing framework. QtExtensions is a standalone library and could be used independently of VisGUI or VTK. Similarly, we extended and developed several VTK-based widgets to provide enhanced interaction capabilities.
Testing Framework
No framework or application is complete if it is not tested. The VisGUI framework provides system integration and unit tests to ensure software quality and reliability. The core of the VisGUI testing framework is built on top of the CMake/CTest/CDash framework. GUI testing is performed by recording a sequence of events and playing these events back on a test machine. The final viewport render is then compared against a baseline image. VisGUI uses the QtTesting library, which was developed as part of a GUI testing mechanism for ParaView, as the underlying engine for GUI testing.
Applications
We have leveraged the VisGUI framework in developing three GUI applications, which provide graphical interfaces to control aspects of the visualization such that the video data, metadata, and derived data can be analyzed in a way that is easier to comprehend. We describe some of the features of these applications in the remainder of this article.
VsPlay
The VsPlay application is targeted at working with a single stream source. It provides tools for interactively visualizing video and metadata from an input stream, and the high-level detections from a video processing and analysis system associated with that stream. The stream can be either “live” (data that is currently being processed by the system) or “archived” (data that has been previously processed). Working with live video also provides limited ability, in the form of alerts, to interact with the running system. Additionally, live feedback can be submitted to the running system to provide a form of streaming Interactive Query Refinement (IQR). High-level features of VsPlay include video viewing with DVR-style playback controls, visualization of tracks and events, geospatial filtering of events and tracks, and the ability to generate new events based on user input. Some of these features can be seen in Figure 3.
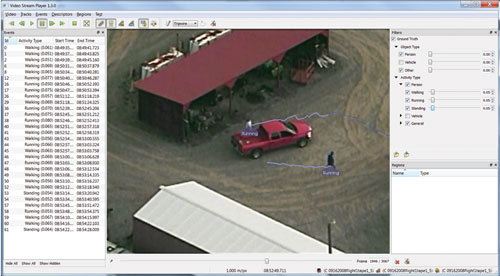
Figure 3: The VsPlay interface showing the main render view, a list of detected events on the left, and filtering controls on the right. Source data is from the VIRAT public dataset [3].
Viewing Video
Accessing and displaying the video is one of the core features of VsPlay. Full DVR-style playback controls are provided, allowing the user to pause and rewind the video, as well as alter the playback speed (both faster and slower than real time). Video playback is time-based, so playback follows real time in the face of uneven or dropped frames, and will automatically skip frames to maintain playback speed if the user’s machine is excessively loaded. Additionally, there is a time scrubber to allow quick seeking within the video.
Various metadata is displayed in addition to the video image, including the time that the video was shot, the frame number within the current stream, and the estimated ground sample distance of the current frame. The interface also provides the estimated geographical coordinates of a given pixel, and the ability to measure the approximate ground distance between two points on the image.
Visualization of Tracking and Events
VsPlay enables the visualization of tracks formed from the detection of moving objects. Tracking boxes, showing the video region that has been identified as an object, are drawn on the current frame for objects that are detected at that frame. Tracking history is drawn as a line from the estimated ground center of the tracked object, allowing the location and motion of the object over time to be visualized. Display of track boxes, track history, and track labels (including track classification) is all optional and can be turned on or off as required. Events such as walking, running, carrying, starting, and U-turning are displayed in a similar manner
(See Figure 4 ).
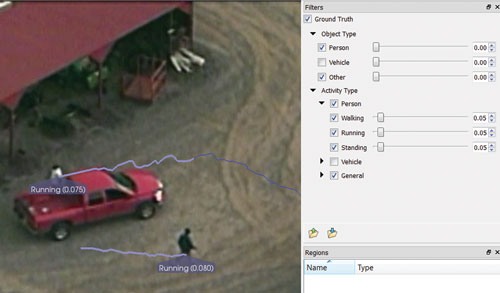
Figure 4: Events detected by the system are shown as a thicker line overlaid on the track, with labels indicating event type and probabilities. Source data is from the VIRAT public dataset [3].
Annotations
VsPlay provides the ability for users to make annotations on the video. Annotations are persistent, user-created shapes, which can be drawn while the video is playing and are persistent. By using the system’s video stabilization, their ground location remains constant as the camera moves. While an annotation is simply a marking on the video, the underlying capability is leveraged to provide additional functionality, including trip wires and geospatial filtering.
User-Defined Events
In addition to “canned” event detection and classification, VsPlay includes features that allow analysts to input additional parameters from which events should be generated. These can come in multiple variations, and the design of VsPlay enables new variations to be added as needed. One type of interactive event detection is the “trip wire” event (see Figure 5), which is a type of user region, like an annotation, that generates an event whenever an object (track) crosses it.
Another type of interactive event is a streaming query. The user selects a previously defined query (discussed more in a later section) and asks the system to match against it in real time. This can be used to detect event types not currently “built into” the system, or as a means of bringing attention to events matching more complicated criteria than the simpler built-in event detections. For example, the system might identify the event “vehicle turning,” but a streaming query could potentially be used to identify a red vehicle that stops and then turns. The user may then provide feedback to the system to refine the query in real time.

Figure 5: Example of a trip wire (shown in yellow) drawn around a structure, such that events will be created for tracks entering and exiting the structure. Source data is from the VIRAT public dataset [3].
Information Filtering
In order to reduce cognitive load and to help focus attention on relevant events, VsPlay provides several features to filter and organize information. Filtering is provided based on both event classification and geospatial location. Classification filtering operates in two stages. First, all information pertaining to a tracked object may be filtered based on its type. This is most typically used to tune detection to reduce false positives, but can also be used to quickly eliminate object classes that are not currently of interest. Second, events can be filtered by specific classification. Examples of specific classifications include “vehicle turning,” “person running,” “trip wire crossed,” or specific streaming queries. The UI also provides controls to easily toggle groups of classifications. Both styles of classification filtering also allow the user to specify a confidence threshold, so that only classifications above the requested threshold are shown (see the panel in the right portion of Figure 3).
Geospatial filtering makes use of user regions that have been designated as either filters or selectors, to allow the user to eliminate specific geospatial areas (such as a rooftop prone to false detections, as shown in Figure 6), or restrict displayed tracks and events to a specific region of interest.

Figure 6: Example of a “filter region,” a user drawn and ground stabilized region that “filters out” undesired returns (the false detections on the roof of the building).Source data is from the VIRAT public dataset [3].
Lastly, VsPlay provides event and track panes to allow for fine tuning of track and event display and controls to jump to the start or end of a track or event.
Viqui
Viqui is the front-end for the archival capabilities of a vision system, allowing a user to search a database of ingested video for video clips that match flexible user criteria. In summary, Viqui enables an analyst to:
• Define a query
• View and analyze results of a query
• Interactively refine a query
Results in Viqui are visualized using either a georeferenced display over a context map (which could be a street map or satellite imagery), or using a timeline chart. Result lists are also available, giving more detailed textual information such as the calculated relevancy score, rank, and the start/end time of each result. Individual results may also be viewed in a simple video player, which helps the user to focus on that result, while the other views provide an overview and can allow users to identify patterns in a result set (see Figure 7).
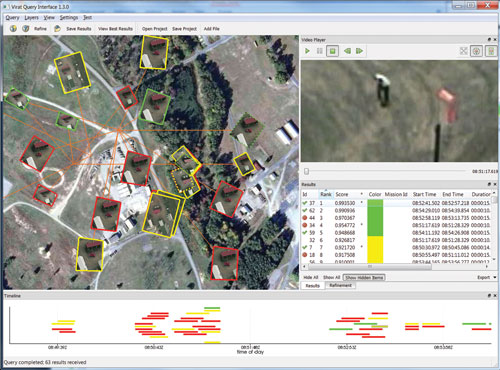
Figure 7: Viqui GUI showing map view (left), video player (top right), results list (right), and timeline view (bottom). Source data is from the VIRAT public dataset [3].
Query Formulation
Query formulation can take several forms, including exemplars and predefined queries that can be further constrained by geospatial or temporal limits. Users can also save queries and query results for later use. Viqui provides several methods to define a query. The primary query types are:
• Video Exemplar
• Image Exemplar
• System Predefined
Video Exemplar
Perhaps the most flexible query method is the video exemplar, where users provide an example video containing an instance of the event they wish to find. This video is processed by the system, after which users select one-or-more appropriate descriptors that numerically represent various aspects of the processed video. The system also provides a video player that presents tracks and regions detected by the system in the processed video, as shown in Figure 8.
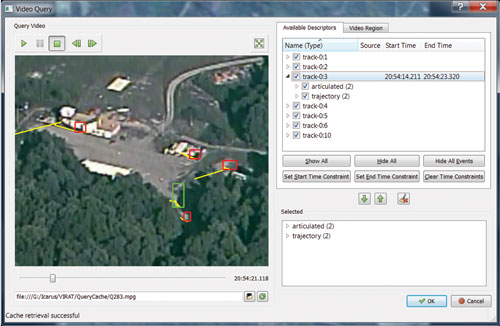
Figure 8: Query formulation using Video Exemplar in Viqui (Source data is from the VIRAT public dataset [3])
In some cases, it may be desirable to formulate a new query based on the contents of an existing result video clip. For example, the user might notice an interesting event in a video clip returned by a query. Users can then use this video clip for query formulation purposes by loading the clip in the query formulation interface and selecting the descriptors corresponding to the interesting event as the basis for a new query.
Image Exemplar
Image exemplar queries are formed by providing the system with an example image, rather than a video clip. The image is processed using a special pipeline optimized for this mode of operation. The user then selects the desired descriptors (appearance properties for different sub-extents of the image) using the same interface as the one used in video exemplar query formulation.
System Predefined
The simplest means of performing a query is by selecting one from a predefined list; that is, using queries that have previously been created using an alternate method of formulation. The list is generated by traversing a directory structure that contains previously saved query files. Additional constraints may be placed on a query by providing temporal or spatial limits for the results.
Query Result Overview
The map view, also the main view of Viqui, displays an overview of the query results in a geographical context. A VTK-based scene graph was developed for this view to capture the spatio-temporal relationship between the video results and related visual entities. In this view, the first frame of each result is displayed in its geospatially-registered location on the context as seen in Figure 1. Since the first frame of a result gives only a limited sense of the quality of the result, the border of each of the results is colored according to one of a variety of schemes to provide additional information. Results are also displayed in a table view and a timeline view. Playback of a particular result can be started from either the context view (by double-clicking the desired video window) or by selecting the desired result in any of the other views. A standalone video player is provided to view the video in a traditional mode. Playback of the video in the video player is synchronized with playback on the context, which is geospatially registered for each video such that the video pixels correspond roughly to the ground plane; the video window is warped and rotated according to the camera parameters for each video frame.
The map view provides basic interaction features such as pan, zoom, and rubber band zoom. Since a query can potentially have thousands of results, it is possible that some of these results will be co-located or nearby, such that overlap or occlusion occurs. To help alleviate this problem and to reduce cognitive overload, Viqui provides Z-Sort, Blast, and Stack layout strategies as shown in Figure 9.
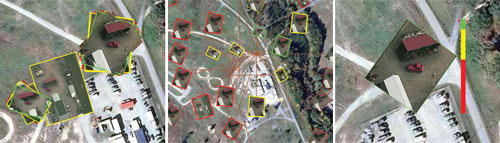
Figure 9: Different layout modes: Z-Sort, Blast, Stack (Left to Right) for results in Viqui (Source data is from the VIRAT public dataset [3])
Timeline View
It is often useful for analysts to get a sense of the temporal spacing, ordering, and duration of various results. The timeline pane (shown at the bottom of Viqui in Figure 7) provides this functionality by displaying the time span of results along the X-axis, and an offset for overlapping results along the Y-axis. Inspired by similar tools found in non-linear video editing software, the timeline chart is fully interactive and enables users to pan, zoom, and select results. The timeline is also integrated with the rest of the application; selecting an interval in the timeline will cause the corresponding result to be selected in the result list, and its video will begin playback in the context view and video player.
Clip Viewer
The clip viewer (as shown in Figure 10) provides the ability to view video clips from multiple results simultaneously. Multiple result clips are cropped to the relevant detection and played back in real time, allowing the analyst to quickly compare results of interest.

Figure 10: Clip viewer showing multiple result clips simultaneously playing back. Source data is from
the VIRAT public dataset [3].
Analyzing and Refining the Result Set
Interactive Query Refinement (IQR) enables users to focus the search algorithm on (or away from) particular aspects or features within the results. During the review process, the user has the ability to mark each result as either relevant or not relevant. This feedback is then used by the system as a means to rescore and thus reorder the results to be returned.
Report Generation
VsPlay and Viqui both provide the ability to compile and output information about a selected subset of events to aid in creating summary reports for later analysis. The content included in the summary report includes an encoded full-frame video for each event, a representative sample image from a single frame of video with track and region overlay information, geographic coordinates of the event for that frame, any per-event notes added by the user, and any other metadata relevant to the detection. The data contained in the generated report are human-readable, but are also formatted in a way to make it easy to process with other tools.
VpView
VpView was initially developed to visualize and analyze threat detection in wide-area motion imagery and is similar to VsPlay with respect to track and event visualization. However, the large wide-area images, inherent to the collected data, led to the development of a new multi-resolution JPEG (MRJ) format, which enables VpView to have fine control of image level-of-detail in order to maintain interactive frame rates for the visualization. Additional features unique to VpView within the VisGUI tools are activity visualization, a 3D graph view for data analysis, and an interactive graph model editor.
Activity Visualization
Activities are a collection of coherent events. To visualize the activity, a representation was developed that uses VTK’s implicit modeler to build a reasonably tight 2D shell around the events that comprise the activity. The 2D shell is then rendered translucently such that the imagery is visible beneath the representation (see Figure 11).
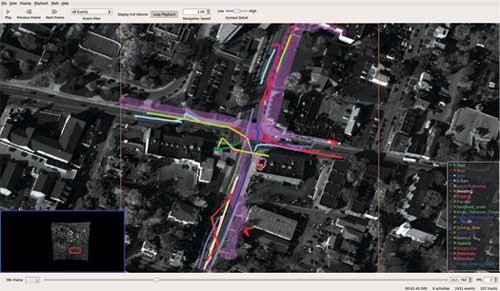
Figure 11: Tracks, events and activities shown in a 2D View. Source data is from CLIF dataset [4].
3D Graph View
As the number of tracks, events, and activities increases or the relationships become more complex, the basic 2D view can become too cluttered. This led to the development of a 3D view (shown in Figure 12) where the entities are drawn as graph nodes and the relationship between the entities are shown as edges of the graph. In this view, activities are drawn at the highest level, followed by events and then tracks. This hierarchy made sense since activities are comprised of events, which in turn are comprised of tracks. The 3D view mode also provides a full volume mode, which when activated, simultaneously renders all of the detected entities and their relationships. The 3D view utilizes VTK’s graph framework and a custom GraphMapper.
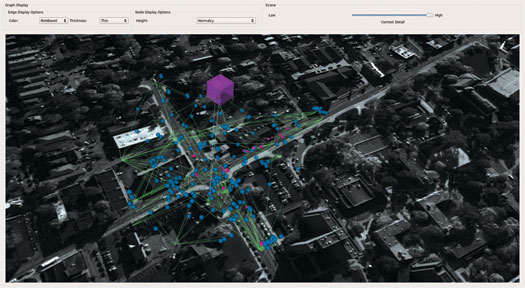
Figure 12: Tracks, events and activities shown in the 3D Graph View. Source data is from CLIF dataset [4].
Graph Model Tool
The VpView graph editor provides researchers with a convenient method of creating a model for a new activity and defining the relationship of the events that comprise the activity. Internally it uses a custom GraphModel and GraphMapper from the VisGUI framework. The graph editor view provides various interactive features such as pan and zoom, node and edge selection, interactive addition and deletion of nodes and edges, and interactive labelling of nodes. Importing and exporting of a model is accomplished via a JSON file format. Figure 13 shows a graph created using the graph editor.
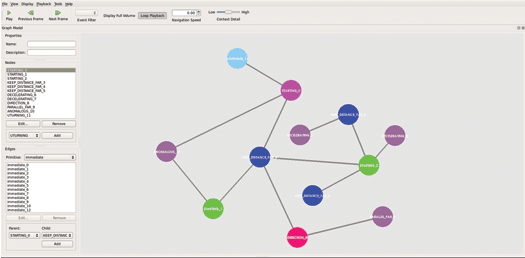
Figure 13: Graph Created by the User using the Interactive Graph Editor of VpView.
Conclusion
The VisGUI toolkit has proven to be quite capable in building fully-featured, interactive, cross-platform, high-performance applications. The tools have served as the delivery mechanism for vision results of many high-profile demonstrations, and have received praise from active-duty analysts. Originally developed in support of the DARPA PerSEAS [5] and VIRAT [6] projects, the tools are being used with only minor modifications on other research projects within the vision program.
For further information or to discuss potential collaboration, please contact kitware@kitware.com.
References
[1] Qt, http://qt.nokia.com
[2] Visualization Toolkit (VTK), http://vtk.org
[3] Sangmin Oh, Anthony Hoogs, Amitha Perera, Naresh Cuntoor, Chia-Chih Chen, Jong Taek Lee, Saurajit Mukherjee, J.K. Aggarwal, Hyungtae Lee, Larry Davis, Eran Swears, Xiaoyang Wang, Qiang Ji, Kishore Reddy, Mubarak Shah, Carl Vondrick, Hamed Pirsiavash, Deva Ramanan, Jenny Yuen, Antonio Torralba, Bi Song, Anesco Fong, Amit Roy-Chowdhury, and Mita Desai, “A Large-scale Benchmark Dataset for Event Recognition in Surveillance Video” in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), 2011. Aerial data from Release 2.0, http://www.viratdata.org
[4] Columbus Large Image Format (CLIF) 2007 Dataset, https://www.sdms.afrl.af.mil/index.php?collection=clif2007
[5] Persistent Stare Exploitation and Analysis System (PerSEAS), http://www.darpa.mil/Our_Work/I2O/Programs/Persistent_Stare_Exploitation_and_Analysis_System_(PerSEAS).aspx
[6] Video and Image Retrieval and Analysis Tool (VIRAT), http://www.darpa.mil/Our_Work/I2O/Programs/Video_and_Image_Retrieval_and_Analysis_Tool_(VIRAT).aspx
This material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA) under Contract Nos. HR0011-08-C-0135 and HR0011-10-C-0112. It is approved for release under DISTAR #19562. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of DARPA.
 Aashish Chaudhary is an R&D Engineer on the Scientific Computing team at Kitware. Prior to joining Kitware, he developed a graphics engine and open-source tools for information and geo-visualization. Some of his interests are software engineering, rendering, and visualization
Aashish Chaudhary is an R&D Engineer on the Scientific Computing team at Kitware. Prior to joining Kitware, he developed a graphics engine and open-source tools for information and geo-visualization. Some of his interests are software engineering, rendering, and visualization
 Rusty Blue is a Technical Leader on the Computer Vision team at Kitware. With nearly 15 years of VTK experience, he leads a team developing visualization tools and applications utilizing VTK in support of many of the vision projects.
Rusty Blue is a Technical Leader on the Computer Vision team at Kitware. With nearly 15 years of VTK experience, he leads a team developing visualization tools and applications utilizing VTK in support of many of the vision projects.
 Ben Payne is an R&D Engineer on the Computer Vision team at Kitware. Before joining Kitware, Ben worked in the video game industry. He holds a B.S. in Applied Science with a focus on Computer Engineering, and a Master’s degree in Computer Science.
Ben Payne is an R&D Engineer on the Computer Vision team at Kitware. Before joining Kitware, Ben worked in the video game industry. He holds a B.S. in Applied Science with a focus on Computer Engineering, and a Master’s degree in Computer Science.
 Matthew Woehlke is an R&D Engineer on the Computer Vision team at Kitware. He holds a B.A. in Computer Science and Mathematics from Concordia University, which he received in 2004
Matthew Woehlke is an R&D Engineer on the Computer Vision team at Kitware. He holds a B.A. in Computer Science and Mathematics from Concordia University, which he received in 2004
Can i get a copy of the source code ?
Unfortunately our source code contains ties to code that does not have public release approval (yet); this limits (largely eliminates) its usefulness out-of-the-box, which is something we’re trying to address before giving out source code. We’re currently
exploring the possibility of public release of the code VisGUI depends on and options to remove the dependencies, as well as working another round of public release approval for the updates we’ve made since the summer of 2012.
The VisGUI project has been opened source now?
Thanks!
https://github.com/xsmart/vdc project hope for your source code.