vtkImplicitArrays: A new VTK framework for manipulating array-like data
VTK now offers a flexible vtkImplicitArray template class that implements a read-only vtkGenericDataArray interface. It essentially transforms an implicit function mapping integers (indices) to values into a practically zero cost vtkDataArray. This is helpful in cases where one needs to attach data to data sets and memory efficiency is paramount.
Use cases include, but are not limited to:
-
wrapping analytical functions: where array values can be generated programmatically
-
providing views: where a homogeneous interface to a subset or combination of other data already in memory or on disk might be desired
-
simplifying interactions: where a complex data structure can be hidden behind an implicit array to encapsulate its API
The Backend Philosophy
In order to reduce the overhead of these containers as much as possible, vtkImplicitArrays are templated on a "Backend” type. This backend is "duck typed" so that it can be any constant functor/closure object or anything that has a map(integral_type) const method. As such, they provide a certain degree of flexibility and compute performance that is easily obtained through the static dispatching native to templates. Developers can use tried and tested backends in the VTK framework when it fits their needs or develop their own backends on the fly for specific use cases. vtkImplicitArrays can then be packed into data sets to be transmitted through the data processing pipeline with the idea that calls to the "read-only" API of vtkGenericDataArray should be inlined through the implicit array and generate close to zero overhead with respect to calling the backend itself.
Simple Usage
Here is a small example using a constant functor in an implicit array:
struct ConstBackend { int operator()(int vtkNotUsed(idx)) const { return 42; }; }; vtkNew<vtkImplicitArray<ConstBackend>> arr42; arr42->SetNumberOfComponents(1); arr42->SetNumberOfTuples(100); CHECK(arr42->GetValue(77) == 42); // always true
The array created above mimics a vtkIntArray explicit memory array with 100 components whose values are all equal to 42.
More Advanced Usage
The example below constitutes a more advanced usage of the vtkImplicitArray capabilities and is to be used with caution. The idea is to encapsulate a pointer to an actual data set in the backend and furnish a spatially varying analytical vector field as point data by dynamically computing its values as they are queried. As such, almost no supplemental memory is taken by the field at the cost of some computation during access. However, the pointer to the data set is a weak pointer to avoid a circular dependency. This means that as soon as the Geometry pointer is invalidated the data array is no longer valid.
struct VortexBackend { VortexBackend(vtkDataSet* geometry) : Geometry(geometry) {} double operator()(int idx) const { int iComp = idx % 3; int iTuple = idx / 3; double* pt = this->Geometry->GetPoint(iTuple); switch (iComp) { case (0): return -0.2 * pt[1]; case (1): return 0.08 * pt[0]; case (2): return 0.02 * pt[2]; default: return 0.0; } } vtkDataSet* Geometry; }; vtkNew<vtkImageData> grid; [...] vtkNew<vtkImplicitArray<VortexBackend>> vortex; vortex->SetName("Vortex"); vortex->ConstructBackend(grid); vortex->SetNumberOfComponents(3); Vortex->SetNumberOfTuples(nPoints);
The vector field, described by the implicit array backend above, models a vortex around the Z axis whose stream lines can be visualized using the vtkStreamTracer filter:
When used in conjunction with a vtkImageData data set, the whole structure takes very little memory. This same implicit array pattern can be used to rapidly visualize complex analytical structures with very little memory cost.
Related Performance
While taking little to no memory, the computational overhead of performing a calculation at every array access can be consequential. In the case described in the paragraph just above the usage of the vtkImplicitArray incurred a computational overhead of around 60% on average. Schematically:
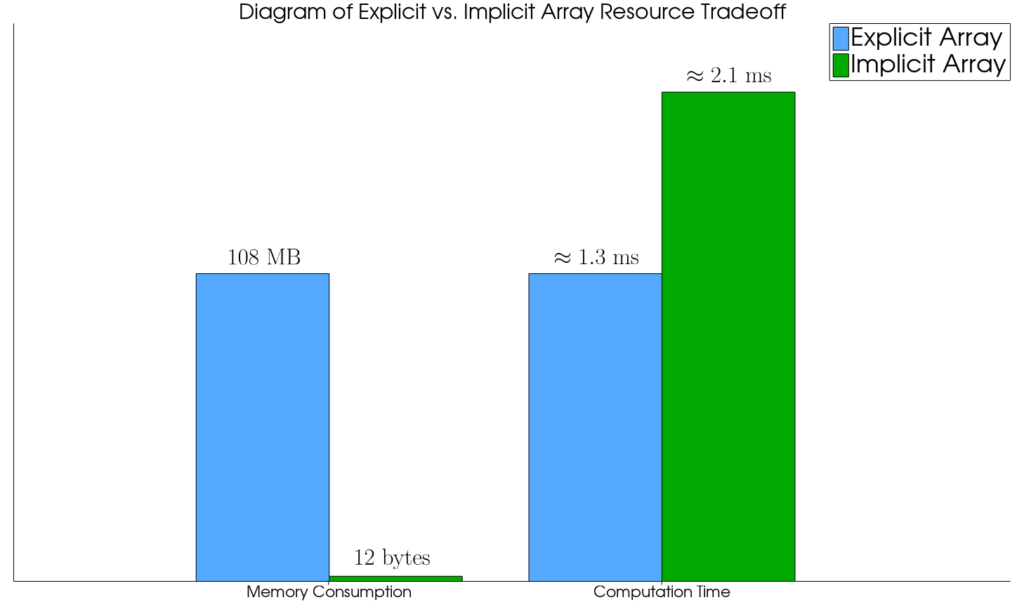
Pre-compiled Backends
For convenience, a number of backends have been pre-packed into the vtkImplicitArray framework. They are, in alphabetical order:
-
vtkAffineArray: using thevtkAffineImplicitBackendclosure backend that gets constructed with a slope and intercept and then returns values linearly depending on the queried index -
vtkCompositeArray: using thevtkCompositeImplicitBackendclosure backend that takes astd::vectorat construction and returns values as if the list has been concatenated into one array -
vtkConstantArray: using thevtkConstantImplicitBackendclosure backend that gets constructed with a given value and then returns that same value regardless of the index queried -
vtkStdFunctionArray: using astd::functionbackend capable of covering almost any function one might want to use (at the cost of usingstd::functions intensively) -
vtkIndexedArray: using thevtkIndexedImplicitBackendclosure backend that takes an indexing array (eithervtkIdListorvtkDataArray) and a basevtkDataArrayat construction and returns values indirected using the indexing array to give access to a shuffled array without the memory cost
Here is a small code snippet example to illustrate the usage of the vtkConstantArray:
vtkNew<vtkConstantArray<int>> arr42; arr42->ConstructBackend(42); arr42->SetNumberOfComponents(1); arr42->SetNumberOfTuples(100); CHECK(arr42->GetValue(77) == 42); // always true
This array effectively produces the same behavior as the "Simple Usage" example above.
Focus on vtkCompositeArrays
The vtkCompositeArray is a family of vtkImplicitArrays that can concatenate arrays together to interface a group of arrays as if they were a single array. This concatenation operates in the "tuple" direction and not in the "component" direction (in numpy terms, this concatenation acts like a vstack on the two dimensional arrays).
This new array relies on the vtkCompositeImplicitBackend template class to join a std::vector of vtkDataArrays. The vtkCompositeArrays use internal address referencing and indirection to implement binary search on the indexes of the composite array leading to access with O(log2(n)) time where n is the number of leaves (or base vtkDataArrays) composing the composite.
To facilitate the creation of vtkCompositeArrays in practice, a templated utility function vtk::ConcatenateDataArrays has been made available to users that can take a std::vector of vtkDataArrays (each with the same number of components) and turn them into a single concatenated vtkCompositeArray with the same number of components as the base array and a number of tuples being the sum of all the base arrays tuples (the order of the arrays in the composite being determined by the order of the input std::vector).
A code snippet using this type of array:
std::vector<vtkDataArray*> baseArrays(16); vtkNew<vtkDoubleArray> baseArray; baseArray->SetNumberOfComponents(3); baseArray->SetNumberOfTuples(10); baseArray->Fill(0.0); std::fill(baseArrays.begin(), baseArrays.end(), baseArray); vtkSmartPointer<vtkCompositeArray<double>> composite = vtk::ConcatenateDataArrays<double>(baseArrays); // nTuples = 160 CHECK(composite->GetComponent(42, 1) == 0.0); // always true
Focus on vtkIndexedArray
The family of vtkIndexedArrays allows you to wrap an existing vtkDataArray with a layer of indirection through a list of indexes (vtkIdList or another vtkDataArray) to create a derived subset data array without any excess memory consumption. As such, by providing a vtkIndexedImplicitBackend with an indexation array and a vtkDataArray, one can effectively construct a reduced and reordered view of the base array.
Using this type of feature to create only one indexed array can be counter productive given that allocation of the index array can be more expensive than an explicit copy of the data. However, this feature enables sharing the same index list amongst multiple indexed arrays effectively using less total memory.
Here is a snippet:
vtkNew<vtkIntArray> baseArr; baseArr->SetNumberOfComponents(3); baseArr->SetNumberOfTuples(100); auto range = vtk::DataArrayValueRange<3>(baseArr); std::iota(range.begin(), range.end(), 0); vtkNew<vtkIdList> indexes; indexes->SetNumberOfIds(30); for (idx = 0; idx < 30; idx++) { indexes->SetId(ids, 10*idx); } vtkNew<vtkIndexedArray<int>> indexed; indexed->SetBackend(std::make_shared<vtkIndexedImplicitBackend<int>>(indexes, baseArr)); indexed->SetNumberOfComponents(1); indexed->SetNumberOfTuples(indexes->GetNumberOfIds()); CHECK(indexed->GetValue(13) == 130); // always true
Building and Dispatch
The entire implicit array framework is included in the CommonImplicitArrays module. Support for dispatching implicit arrays can be enforced by including type lists from vtkArrayDispatchImplicitTypeList.h and compiling VTK with the correct VTK_DISPATCH_*_ARRAYS option.
Implementing a vtkImplicitArray in VTK
Implementing a new vtkImplicitArray in the VTK library usually passes through the following steps:
- Implementing the backend: this is the step where the underlying functionality of the implicit array needs to be developed.
- Creating an alias and instantiating the concrete types: once the backend is ready, one can create an alias for the array in its own header (
using MySuperArray = vtkImplicitArray) and use this header and the automatic instantiation mechanisms present inCommon/ImplicitArrays/CMakeLists.txtto make sure that the VTK library gets shipped with pre-compiled objects for your arrays. - Hooking up the dispatch mechanism: this step ensures that your new arrays can be included in the
vtkArrayDispatchmechanism when the correct compilation option is set. - Testing: be sure to set up some tests in order to both verify that your implementation is functioning correctly and to avoid regressions in the future.
An example merge request that was used for including the vtkIndexedArrays can be found here: !9703.
How can I convert an explicit memory array into a vtkImplicitArray?
A new filter vtkToImplicitArrayFilter in a new FiltersReduction module that can transform explicit memory arrays into vtkImplicitArrays has been developed. The filter itself delegates the "compression" method to a vtkToImplicitStrategy object using a strategy pattern.
The following strategies (in order of complexity) have been implemented so far:
vtkToConstantArrayStrategy: transforms an explicit array that has the same value everywhere into avtkConstantArray.vtkToAffineArrayStrategy: transforms an explicit array that follows an affine dependence on its indexes into avtkAffineArray.vtkToImplicitTypeErasureStrategy: transforms an explicit integral array (with more range in its value type than necessary for describing it) into a reduced memory explicit integral array wrapped in an implicit array.vtkToImplicitRamerDouglasPeuckerStrategy: transforms an explicit memory array into avtkCompositeArraywith constant (vtkConstantArray) and affine (vtkAffineArray) parts following a Ramer-Douglas-Peucker algorithm (wikipedia).
This filter on its own does not have much use. However, it can be used as a last post-processing step internally in another filter to replace explicit output arrays with compressed implicit arrays when possible.
Conclusion
The new vtkImplicitArray framework has been developed in VTK as a means to decrease memory usage and inject more flexibility into the definition of a data array. The framework itself is modular and fast with minimal invasiveness into current functionality. Also, this new family of arrays opens up some interesting perspectives. Integration into some specific filters would likely decrease pipelines’ memory footprint. For example, the contour filters could most likely benefit from the vtkConstantArrays for representing the contoured values on iso-surfaces and vtkIndexedArrays for referencing static cell data. Even so, given the potential performance hits associated with using some of the more complex implicit arrays, the integration of these structures should remain on an "opt-in" basis for memory-strapped users. The memory conscious vtkHyperTreeGrid framework can also benefit from these new arrays for describing both geometry information as well as field data. For other memory restricted cases, one could also imagine implementing a compression backend relying on a compression library like zfp and integrating that into an implicit array family. Finally, these new functional arrays open up some neat potential possibilities in the "Out Of Core" and "Level Of Detail" (LOD) domains where they could act as transparent and adaptive interfaces to data on disk or in memory.
Appendix: Developer notes
- Multi-component arrays have de-facto AOS ordering
- The read-only parts of the vtkDataArray API work out of the box for any
vtkImplicitArrayincluding the following functionalities:- Get components, typed components, tuples, number of components and number of tuples
- vtkAbstractArray::GetVoidPointer (implementing an internal deep copy of the array into an AOS array that can be destroyed with
vtkImplicitArray::Squeeze) - Standard library like ranges and iterators using vtkDataArrayRange functionalities
- vtkArrayDispatch, provided the correct compilation options have been set and the correct type list is used for dispatching (see below)
Appendix: Benchmarking
While evaluating the potential memory gains of specific vtkImplicitArrays can be relatively straightforward and usually greatly in favor of using implicit arrays, the computational overhead of their use is less so. The "static dispatching" mechanism achieved through the templating of the class on the backend itself was designed to minimize its dynamic overhead. Was it successful?
In order to evaluate the computational overhead of the vtkImplicitArray framework the methodology has been to compare the cost of iterating over an explicit array with an implicit array that does nothing but wrap that same explicit array. To that effect, we use the following backend:
struct DoubleArrayWrapper { const vtkDoubleArray* View; DoubleArrayWrapper(const vtkDoubleArray* arr) : View(arr) {} double operator()(vtkIdType index) const { return this->View->GetValue(index); } };
Benchmarking the vtkImplicitArray framework is then performed by iterating over a given vtkDoubleArray directly and comparing with the same iteration wrapped in a vtkImplicitArray. The overhead is computed as the percentage of additional time spent in implicit array iteration.
Two main iteration/access scenarios were studied:
- access through the
vtkGenericDataArray::GetValueinterface: which has approximately~ 0 %overhead regardless of the size of the array - and access through the
vtk::DataArrayValueRangeinterface: which has approximately~ 15 - 20 %overhead regardless of the size of the array
The supplemental cost of iterating through the "range" objects is attributed to the specific AOS range implementations used for vtkDoubleArrays which are more efficient than their Generic counterparts used for the vtkImplicitArrays.
Focus on vtkCompositeArray
The vtkCompositeArray‘s computational overhead can be evaluated as well. In order to do so, we compare the cost of iterating over an explicit memory array with the cost of iterating over a composite array of the same total size and variable number of internal sub-arrays. While the overhead of the composite array is not affected by the total size of the array, it does exhibit the theoretical logarithmic scaling expected from a binary search on the number of a sub-arrays. This is a graph of the evolution of the implicit over explicit timing ratio with respect to the number of internal sub-arrays n in the composite array plotted alongside an empirical scaling law 1.5log2(n) + 2:
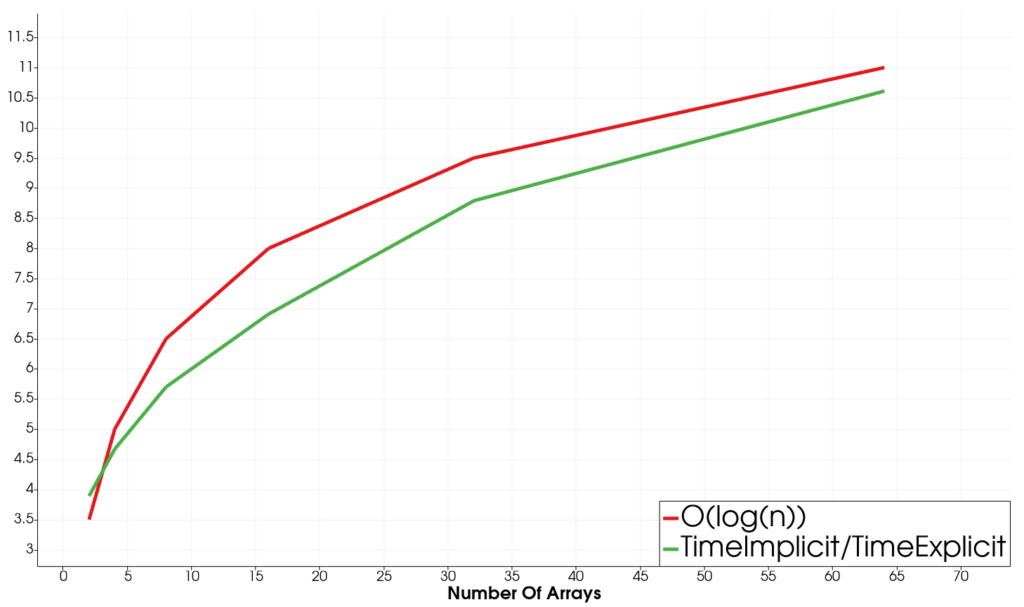
The implementation shows good scaling with the number of arrays but with a steep upfront cost for low numbers of arrays (~ 3 - 4 x the cost of iterating over the explicit counterpart for n = 2).
Focus on vtkIndexedArray
The computational overhead associated with the vtkIndexedArray is measured much in the same manner. The iteration over an explicit array is compared with iterating over a same sized indexed array with indexes being chosen uniquely at random. This is the worst case scenario for the indexed array since each memory access to the underlying array is random during iteration and therefore memory access is not easily optimizable or cacheable. Here is a graph of the timing ratio associated with the indexed array iteration as a function of array size:
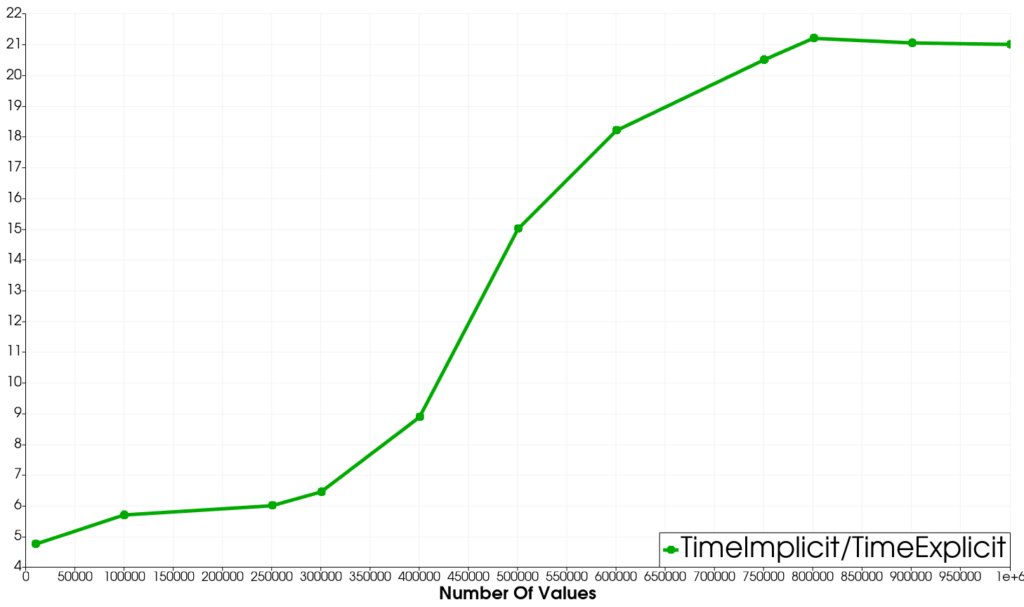
The two plateaus separated by a steep increase is indicative of an increase in levels of cache missing associated with the random memory indexing, although this might be difficult to check for sure. In any case, the overhead associated with the indexed array can be consequential being 5 times longer to iterate through even at small array sizes.
Funding
The development of the vtkImplicitArray framework was funded by the CEA, DAM, DIF, F-91297 Arpajon, France
