ClimatePipes: User-Friendly Data Access, Manipulation, Analysis & Visualization of Community Climate Models

Motivation
Observations unequivocally show that the global climate is changing, caused over the past 50 years primarily by human-induced emissions of heat-trapping gases. The dramatic effects of climate change include increases in water temperature, reduced frost days, a rise in sea level, and reduced snow cover. As the pace of climate change is expected to accelerate, the impact of these changes will resonate through a broad range of fields including public health, infrastructure, water resources, and many others.
Long-term coordinated planning, funding, and action are required to reduce the impact on ecosystems, infrastructure, economies, and the global population. The wide variety of fields impacted by climate change means access to climate data and resources can no longer be restricted to scientists and researchers; other stakeholders must be involved.
Unfortunately, widespread use of climate data in non-climate science communities is impeded by factors such as large data size, lack of adequate metadata, poor documentation, and lack of sufficient computational and visualization resources.
ClimatePipes (Figure 1) aims to address many of these challenges by creating a platform that provides state-of-the-art, user-friendly data access, analysis, and visualization for climate and other relevant geospatial datasets, making the climate simulation data available to non-researchers, decision-makers, and other stakeholders. The overarching goals of ClimatePipes are:
- Enable users to explore real-world questions related to climate change.
- Provide tools for data access, analysis, and visualization.
- Facilitate collaboration by enabling users to share datasets, workflows, and visualization.
 Figure 1: ClimatePipes interface showing cloudiness dataset in a geospatial context.
Figure 1: ClimatePipes interface showing cloudiness dataset in a geospatial context.

ClimatePipes uses a web-based application platform due to its widespread support on mainstream operating systems, ease-of-use, and inherent collaboration support. The front-end of ClimatePipes uses HTML5 (WebGL, CSS3) to deliver state-of-the-art visualization and to provide a best-in-class user experience. The back-end of the ClimatePipes is built using the Visualization Toolkit (VTK), Climate Data Analysis Tools (CDAT), and other climate and geospatial data processing tools such as GDAL and PROJ4. In the next section, we will provide some more detail on the technology and relevant tools used for ClimatePipes infrastructure.
Progress in the First Year
We are currently one year into the project and much has already been achieved. The first year has concentrated on building the infrastructure and components that will provide the building blocks of the ClimatePipes platform. In this year, the focus has been on creating and improving the essential climate and geospatial data libraries, and evaluating state-of-the-art web-visualization and analysis techniques. Here are some of the highlights of the past year work.
Key ClimatePipes Technologies
We chose Python as our server-side language using CherryPy (http://www.cherrypy.org/) as the web server. CherryPy allows developers to build web applications in much the same way they would build any other object-oriented Python program. This results in smaller source code developed in less time. Although we are currently using CherryPy, we have designed our modules in such a way that in the future we could easily move to another Python-based web framework, providing the flexibility to evolve in the future. Using Python as the back-end language allowed us to leverage existing toolkits such as VTK and CDAT, which provide APIs in Python. On the front-end we are using HTML5, particularly WebGL for geo-spatial visualization. JQuery (http://jquery.com/) and Bootstrap (http://twitter.github.io/bootstrap/) are being used as two supporting frameworks to provide a consistent interactive cross-browser experience.
Geo-spatial (Geo) Visualization Library using WebGL
In recent years, WebGL has gained popularity and wide support from different vendors and browsers. WebGL is a cross-platform, royalty-free web standard for a low-level 3D graphics API based on OpenGL ES interfaces. We chose WebGL as the API to render climate and other geo-spatial datasets because of its scalability, support for 2D and 3D formats, and accelerated graphics performance. We have developed a geospatial visualization library, named Geo, using WebGL and JavaScript. Geo provides support for rendering geometry (points, lines, polygons) and image data types. The library implements various features required for interactions such as picking, visibility toggling, and animations (see Figure 2).
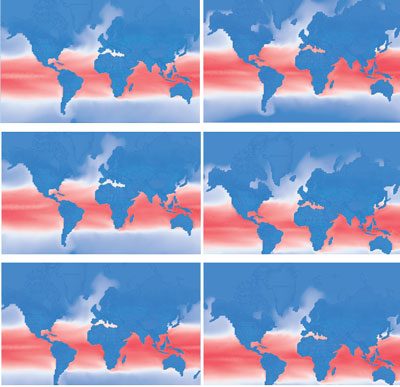 Figure 2: Visualization of time-varying historical climate data via animations in ClimatePipes
Figure 2: Visualization of time-varying historical climate data via animations in ClimatePipes
(powered by the Geo library).
Visualization of Climate Dataset in a Geospatial Context
We have developed an infrastructure for providing high-resolution imagery as the geospatial context for climate data visualizations. The Tile-Based Geospatial Information System (TBGIS) supports panning, different levels of zoom, rotation in one axis (X-axis between 0-to-60 degrees), and different tiles sources. By panning and changing the zoom-level, users can easily find points of interest in the map. The rotation gives the possibility of 3D plots over the map. In addition, with tile sources, users may opt between different sources in order to have different visual representations of the map. Currently, it supports three tile sources: OpenStreetMap, MapQuest Map, and MapQuest Satellite; however, the implementation supports ability to add more new tile sources if needed. The algorithm calculates the number of tiles necessary to cover the entire canvas, and based on the zoom-level and the specified position (longitude and latitude), it calculates and downloads the tiles around that region. Previously-downloaded tiles are cached to improve the rendering performance of the system. Figure 3 shows the tiles downloaded and rendered by the ClimatePipes system for a given position and zoom-level. Artificial spacing between tiles is introduced for clear visual separation.
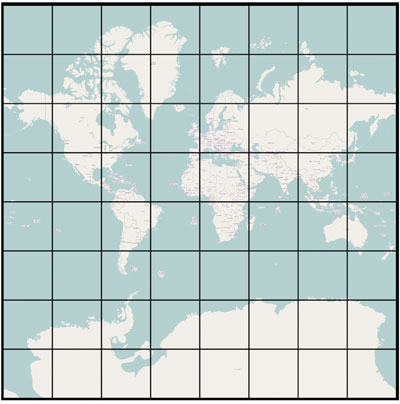 Figure 3: WebGL Map tiles shown with artificial spacing using the Geo library in ClimatePipes.
Figure 3: WebGL Map tiles shown with artificial spacing using the Geo library in ClimatePipes.
Data Integration with ESGF
One of the main features of ClimatePipes is to enable users to combine datasets from different sources. The Earth System Grid Federation (ESGF) is one such source. ESGF is a distributed data archive used to host climate datasets and associated metadata. We have integrated with ESGF by providing a query interface to enable searching of climate datasets in ESGF using a RESTful search API. The search is performed by the ClimatePipes back-end. The result set returned by ESGF can potentially be very large and the total search time can be significant. A streaming approach is used to maintain the interactivity, and to avoid having users wait for the entire search to be completed. The XML document containing the search result from ESGF is parsed and as each catalogue is receives the result is streamed up to the client so users see the first documents very quickly; they can then interact with this data as the rest streams in.
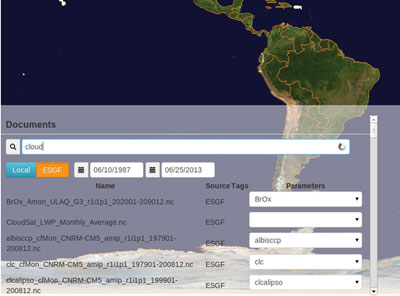 Figure 4: ClimatePipes interface showing data integration and query functionality.
Figure 4: ClimatePipes interface showing data integration and query functionality.
Data Processing for Visualization and Analysis
Climate data in ClimatePipes is accessed through a VTK pipeline via a ClimatePipes VTK service module that exists within the CherryPy web server instance. This module contains a static pipeline that begins with a vtkNetCDFCFReader source. The reader opens and parses a given NetCDF CF convention format file, and produces VTK data structures corresponding to a chosen time step and variable selection. The client-side GUI interface is provided with a list of available files via a MongoDB database interface to a catalogue of available files with their relevant meta-data including temporal and spatial domains and the set of available attribute arrays.
The rest of the pipeline contains filters that prepare the data for transmission to the client. Currently, the VTK pipeline constructed is rather simple, but in the future it can be extended to do more server side data processing.
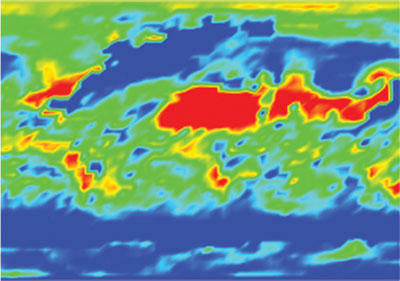 Figure 5: Percent Total Cloudiness interpolated in data space using different color map.
Figure 5: Percent Total Cloudiness interpolated in data space using different color map.
To deliver data to the client, we chose to use the simple and well-known GeoJSON format (http://www.geojson.org/geojson-spec.html). We then developed a server-side VTK writer and a client-side JavaScript GeoJSON importer. On the server-side, the new vtkGeoJSON writer instance sits at the end of the VTK pipeline and converts vtkPolyData into an in-memory GeoJSON representation that is suitable for delivery over the network.
On the client-side, a geojsonReader instance is created in response to a JQuery request to the server for a particular data file. The reader parses the data stream so that it may be visualized and otherwise processed on the client.
To display the data on the client, we populate JavaScript data structures that are suitable for WebGL rendering. The data structures and other rendering infrastructure are defined in the ClimatePipes VGL rendering library component that has also been developed in this first phase of the project.
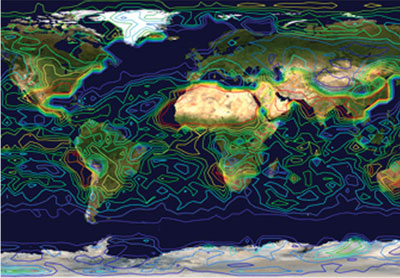 Figure 6: Isolines of the percent total cloudiness data set clt.nc.
Figure 6: Isolines of the percent total cloudiness data set clt.nc.
Interactive Web Editor for ClimatePipes
ClimatePipes has an interactive workflow editor intended to provide easy creation of task-specific workflows. The implementation of workflow-required development of two main components: the JavaScript front-end used to display and interact (build/edit) with the workflows, and a Python workflow engine on the back-end to execute the workflow. New modules are created in the JSON data structure used by the JavaScript front-end. The front end was created using HTML5, JavaScript, and CSS. To execute the workflow, we created a lightweight workflow engine in Python, which simply executes the modules in order and passes data along. Alternatively, VisTrails (http://www.vistrails.org/index.php/Main_Page) can be used to execute the workflow if provenance, caching, and other features are desired. These workflows are automatically generated for the user after selecting data and a visualization. Users can bring up the workflow view and edit the workflow to perform more advanced changes.
Conclusion
Going into the second year, we are planning on improving integration between different components of ClimatePipes to provide a robust, scalable system at the end of Summer as version 1.0 of the system. Our particular area of focus in the next few months will be:
Data Integration: We will continue to integrate data sources such DataOne and other data sources hosted by NASA, NOAA, and USGS.
Analysis: We will provide several simple but extremely useful climate data analysis algorithms to make it easier for users to comprehend climate variability such as yearly and decadal averages.
Workflows and Data Processing: The challenge is working with large datasets while maintaining the interactive user experience. We have several fronts to work on here, including the use of cloud computing and data streaming.
Acknowledgements
We are thankful to Dr. Berk Geveci of Kitware and Dr. Claudio Silva of NYU-Poly for their support and guidance. We also appreciate Dean Williams and Charles Doutriaux of Lawrence Livermore National Laboratory for providing climate domain expertise and integration efforts with ESGF and UV-CDAT.
The work is performed under DOE SBIR Phase II (DE-SC0006493).
 Aashish Chaudhary is an R&D Engineer on the Scientific Computing team at Kitware. Prior to joining Kitware, he developed a graphics engine and open-source tools for information and geo-visualization. Some of his interests are software engineering, rendering, and visualization.
Aashish Chaudhary is an R&D Engineer on the Scientific Computing team at Kitware. Prior to joining Kitware, he developed a graphics engine and open-source tools for information and geo-visualization. Some of his interests are software engineering, rendering, and visualization.
 David E. DeMarle is a member of the R&D team at Kitware where he contributes to both ParaView and VTK. He frequently teaches Kitware’s professional development and training courses for these product applications.
David E. DeMarle is a member of the R&D team at Kitware where he contributes to both ParaView and VTK. He frequently teaches Kitware’s professional development and training courses for these product applications.
 Ben Burnett is a senior software developer in the vgc research group at NYU Poly. He received his M.S. in Computing from the University of Utah where he focused on Data Management and Analysis.
Ben Burnett is a senior software developer in the vgc research group at NYU Poly. He received his M.S. in Computing from the University of Utah where he focused on Data Management and Analysis.
 Chris Harris is an R&D Engineer at Kitware. His background includes middleware development at IBM, and working on highly-specialized, high performance, mission critical systems.
Chris Harris is an R&D Engineer at Kitware. His background includes middleware development at IBM, and working on highly-specialized, high performance, mission critical systems.
 Wendel Bezerra Silva received both his bachelor and masters degree at Universidade de Fortaleza (UNIFOR), working with real-time rendering on mobile devices. Currently, he’s a Ph.D. student at Polytechnic Institute of NYU (Poly-NYU), working with information visualization, large data and visualization for the masses.
Wendel Bezerra Silva received both his bachelor and masters degree at Universidade de Fortaleza (UNIFOR), working with real-time rendering on mobile devices. Currently, he’s a Ph.D. student at Polytechnic Institute of NYU (Poly-NYU), working with information visualization, large data and visualization for the masses.