From Data Chaos to Clarity: Best Practices for Managing Complex Datasets

Data is one of the most powerful assets in modern research, but without the right infrastructure, it can become fragmented, inconsistent, and difficult to leverage. For scientists and organizations working with large, complex datasets, this can slow progress, limit collaboration, and add unnecessary costs. Modern data portals solve these common pain points.
A data portal is more than just a repository. It’s a scalable, secure platform that unifies diverse datasets and makes them accessible for analysis, collaboration, and informed decision-making. Data portals manage the entire data lifecycle—from acquisition and curation to visualization and advanced analysis—so researchers can focus on science rather than data wrangling.
The following initiatives highlight some specific challenges of data collection and management:
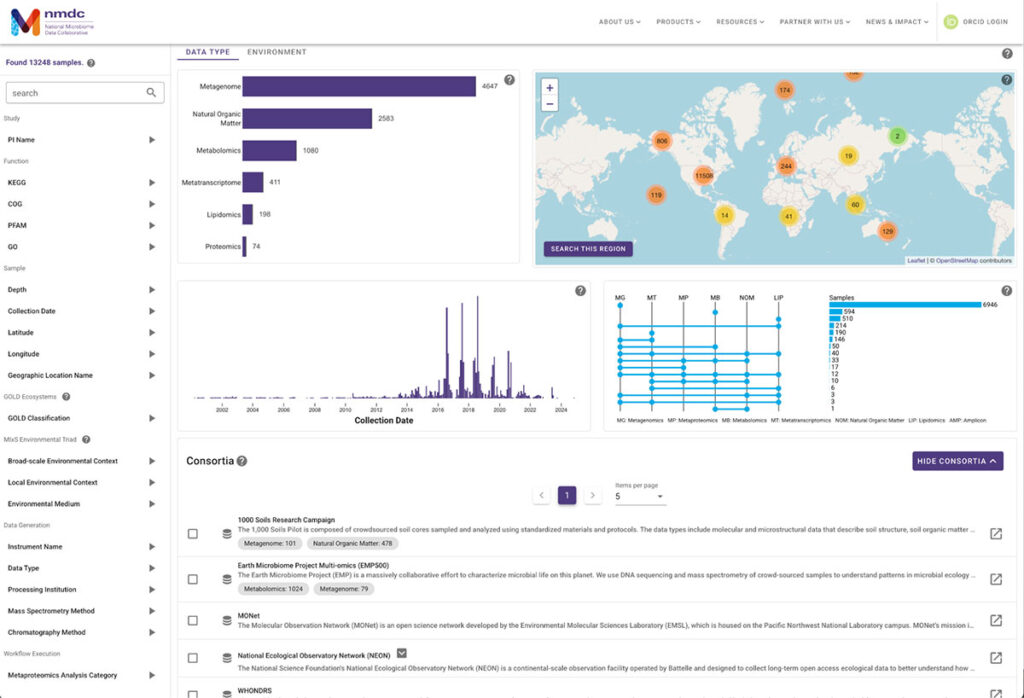
National Microbiome Data Collective (NMDC): Turning Distributed Data into FAIR Data
Microbiome research requires samples from many different sites and contexts. Without common standards, this data becomes fragmented and difficult to compare. NMDC is addressing this by ensuring that microbiome data follows the FAIR principles—Findable, Accessible, Interoperable, and Reusable—by:
- Developing ontology mapping tools that align metadata across diverse datasets.
- Automating annotation and curation to reduce the time scientists spend preparing data.
- Delivering intuitive, web-based interfaces for searching, exploring, and downloading standardized data.
These solutions make complex, multi-omics data more accessible and reusable, helping accelerate discoveries in microbiome science.
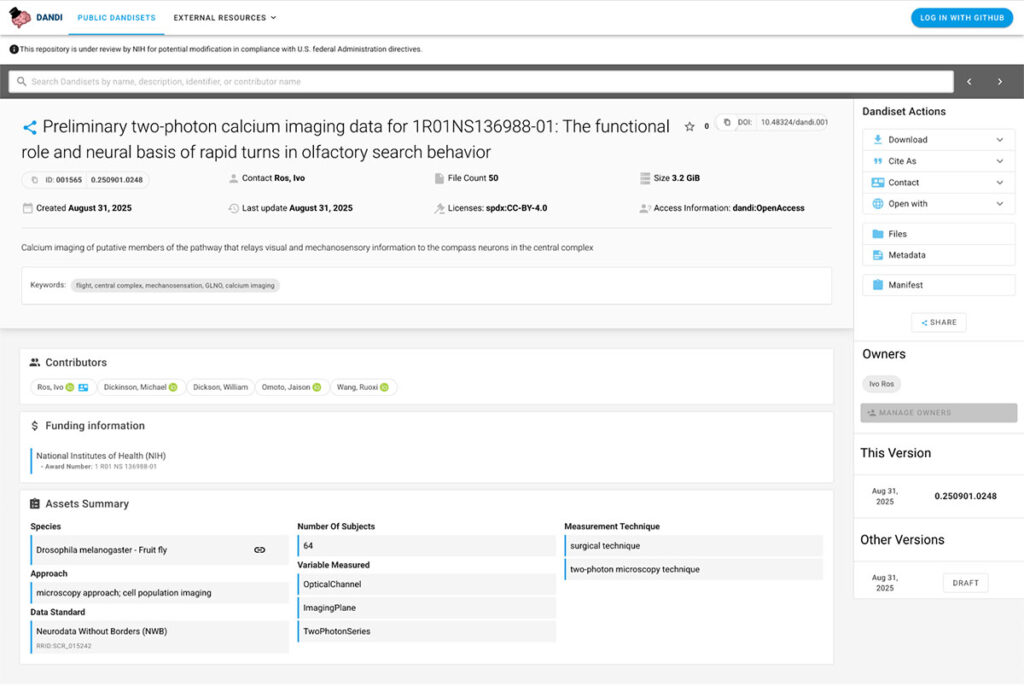
Distributed Archives for Neurophysiology Data Integration (DANDI): Enabling Scalable Neuroscience Research
Neuroscience research generates highly heterogeneous data, ranging from electrophysiology to behavioral to imaging, produced by different devices and labs, at very different size scales. DANDI is a cloud-based data archive that standardizes and unifies these data streams by
- providing an API for seamless integration with analysis workflows;
- enabling computation directly on the data in the cloud, avoiding the need for large-scale downloads;
- and supporting immutable, versioned datasets that ensure reproducibility and transparency.
With these tools, DANDI empowers researchers to collect, store, and share data to collaborate, analyze, and build on each other’s work.

Applying These Practices to Your Own Data Strategy
Across these examples, a few recurring challenges stand out:
- Data fragmentation → solved with shared standards and unified APIs.
- Inconsistent quality → addressed through automated curation and metadata alignment.
- Collaboration barriers → removed by secure, web-based portals with reproducible workflows.
- Scaling issues → managed with flexible, cloud-ready architectures.
While NMDC and DANDI represent large-scale national and international initiatives, the same challenges can apply to organizations of any size. If you are evaluating your own data infrastructure, consider these best practices:
- Start with standards. Identify where your data formats, metadata, or vocabularies differ, and implement consistent frameworks that make integration easier.
- Automate where possible. Manual curation is time-consuming and error-prone—look for opportunities to introduce automated annotation and validation pipelines.
- Design for collaboration. Build platforms that make it simple for colleagues and partners to find, access, and reuse your data securely.
- Plan for scale. Even if your current needs are modest, adopt architectures that can handle growth in both dataset size and computational demands.
- Think about reproducibility. Ensure that your data can be trusted, reused, and cited by embedding version control and transparent workflows.
Organizations that adopt these practices not only improve the day-to-day efficiency of their teams but also strengthen the reliability, credibility, and impact of their research.
Turn Best Practices into Real-World Results
Kitware has decades of experience building secure, scalable data portals that make complex datasets usable and actionable. If you’d like guidance applying these best practices—or want to explore how a custom data platform could support your work—our team is here to help.