MIXTAPE: Bringing Clarity to Multi-Agent Reinforcement Learning Through Interactive Explainability
Background
Multi-agent reinforcement learning (MARL) has emerged as a powerful approach for training AI systems to handle complex decision making scenarios, from coordinating autonomous vehicles to optimizing wargaming simulations. However, a critical challenge persists: understanding why trained agents make specific decisions, especially when multiple agents must coordinate their actions in dynamic environments.
Tactical planners, system operators, and AI developers face the same fundamental problem. When a trained model recommends a course of action or executes a tactical maneuver, stakeholders need to understand the reasoning behind those decisions. This becomes exponentially more complex in multi-agent scenarios where coordination between agents directly impacts mission success.
Current MARL systems often operate as black boxes. Developers train agents using reward signals and policy networks, but extracting meaningful explanations about agent behavior requires manual inspection of logs, custom visualization tools, and significant analytical expertise. This limits both the development cycle for researchers and the operational deployment of AI-assisted decision systems.
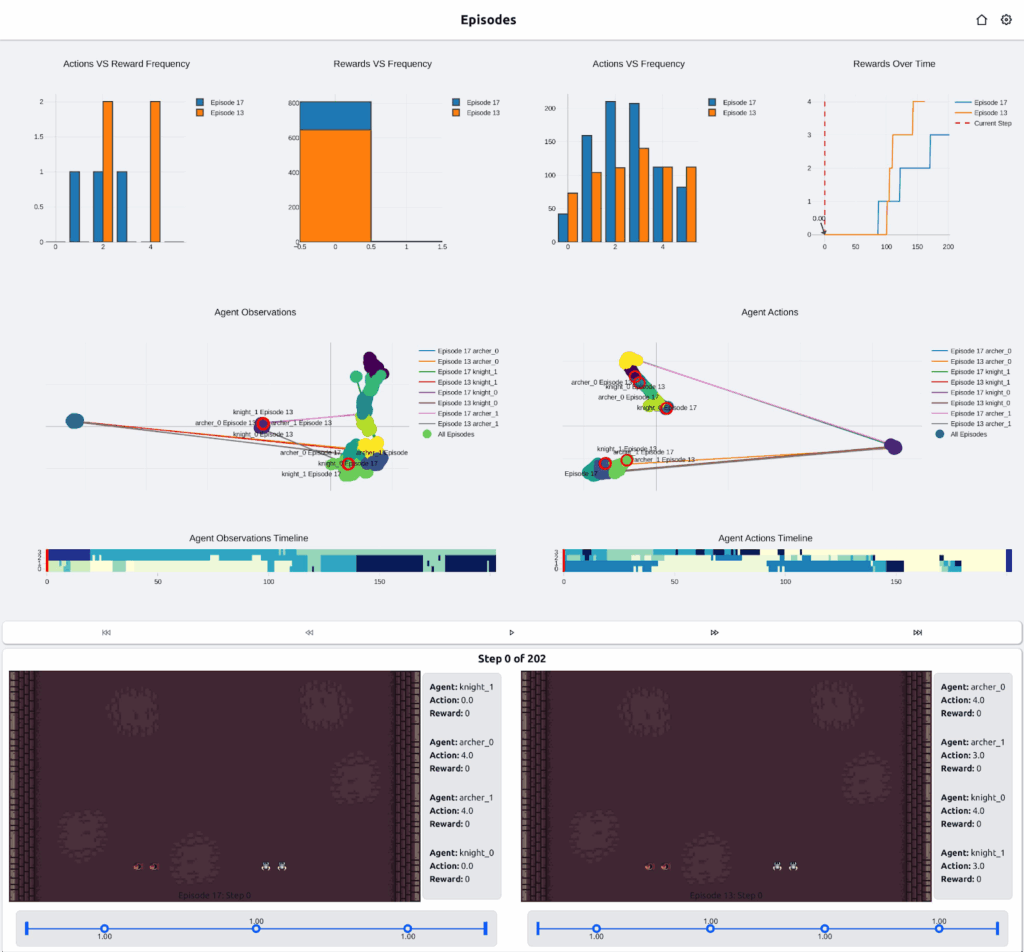
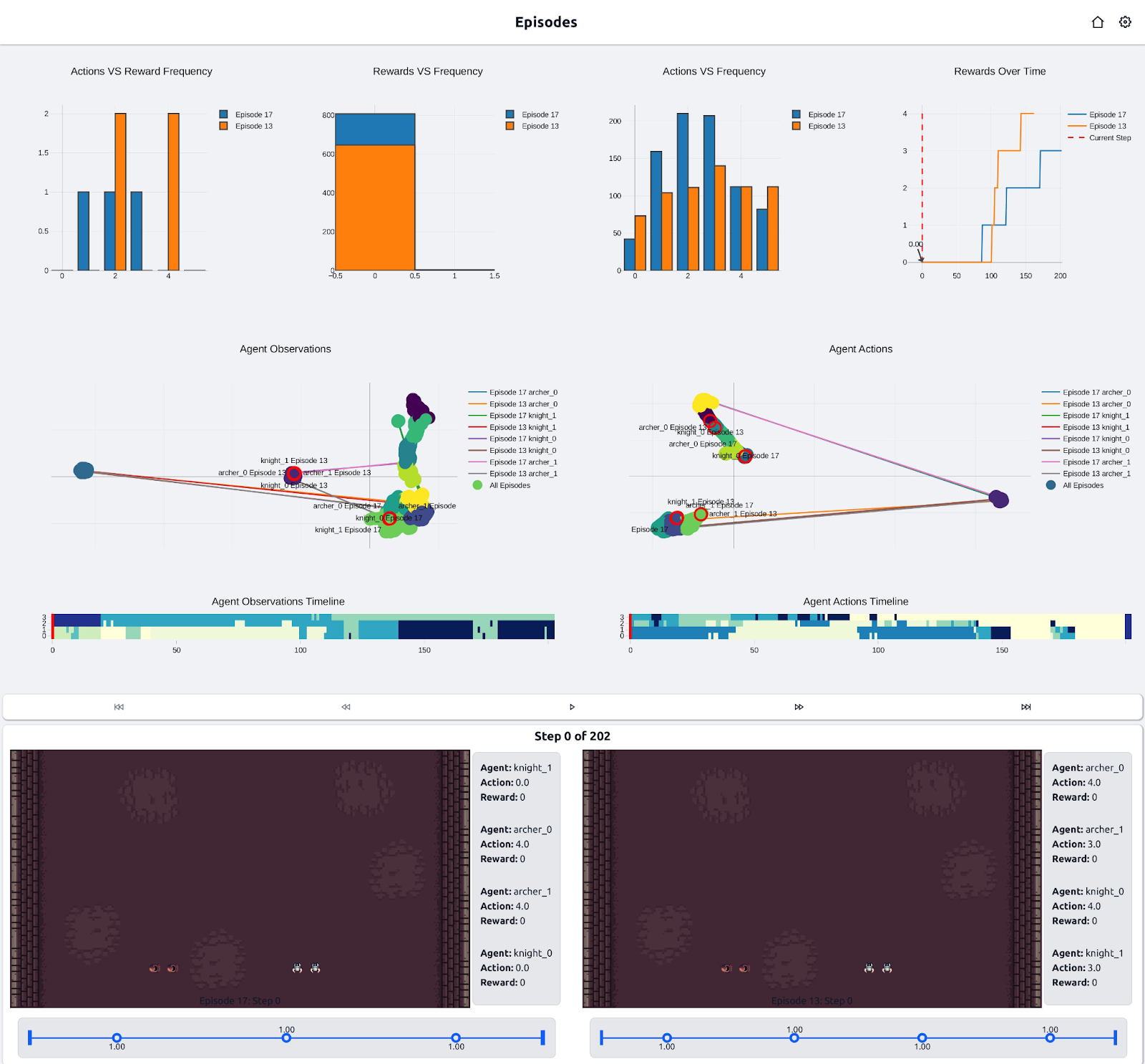
Figure 1: MIXTAPE web user interface displaying two episodes in parallel view. The platform provides reward decomposition charts (showing how agents balance multiple objectives) and agent clustering analysis (revealing coordination patterns) to enable deeper insights into agent decision-making in wargaming scenarios. For a full interactive tour of the MIXTAPE interface, click here to see the demo.
The Gaps We Identified
Through our Army STTR Phase II work with Penn State University, we identified several critical gaps in the current MARL development and deployment landscape:
- Limited Explainability Tools: Existing frameworks provide training capabilities but lack integrated explanation mechanisms. Developers must build custom solutions to understand agent decision-making, reward decomposition, and coordination patterns.
- Fragmented Workflow: The process of training agents, analyzing their behavior, and visualizing results typically requires multiple disconnected tools. Moving data between training environments, analysis scripts, and visualization platforms creates friction and increases the risk of errors.
- Scalability Challenges: Researchers with access to high-performance computing resources often cannot easily leverage them due to environment configuration complexity. Conversely, those with limited resources struggle to train agents on complex scenarios.
- Lack of Geospatial Context: Many real-world applications require understanding agent behavior in realistic terrain. Current tools rarely integrate geospatial data processing with RL training and visualization.
- Insufficient Support for Multi-Objective Scenarios: Real tactical situations involve competing objectives, yet most RL tools treat rewards as single scalar values, obscuring the tradeoffs agents make between different goals.
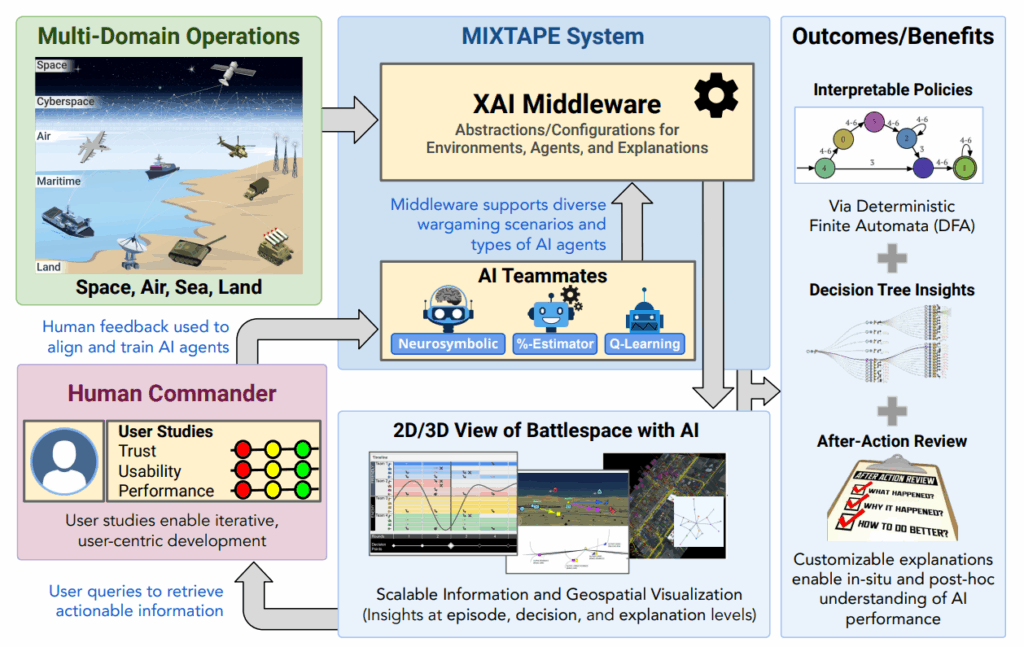
Figure 2: The MIXTAPE approach, illustrated here, utilizes our XAI (eXplainable AI) middleware to enable powerful multi-domain operations by focusing on human-AI collaboration: the middleware provides customizable explanations (such as interpretable policies via neurosymbolic reasoning and decision tree explanations) and After-Action Review tools to help users understand and evaluate AI agent performance. This understanding is supported by interactive and scalable visualizations offering actionable insights at various levels, including geospatial information. Critically, the MIXTAPE system is subject to iterative, user-centric development via controlled user studies to evaluate performance, usability, and the appropriateness of trust; this process ultimately informs novel methods to “close the loop,” enabling human feedback to be used directly during training to improve AI agent performance and align the agents with human users’ goals.
Our Solution: MIXTAPE
MIXTAPE (Middleware for Interactive XAI with Tree-Based AI Performance Evaluation) as shown in Figure1 and 2, addresses these gaps through an integrated platform that combines training, analysis, and visualization capabilities specifically designed for multi-agent reinforcement learning scenarios. For a full interactive tour of the MIXTAPE interface, click here to see the demo.
The system provides three core capabilities:
- Unified Training and Evaluation Environment: MIXTAPE supports multiple RL algorithms (PPO, A2C, QMix, MAPPO, and others) through standardized interfaces. The platform works with various environments including StarCraft II, PettingZoo scenarios, and custom Gymnasium wrappers. Researchers can train locally or scale to HPC resources using containerized deployment.
- Advanced Explainability Mechanisms: The platform incorporates multiple explanation approaches including reward decomposition visualization, specification-based explanations using deterministic finite automata, agent clustering techniques, and coordination analysis between team members. These tools help developers and operators understand not just what agents do, but why they make specific choices.
- Interactive Web-Based Visualization: A modern web user interface provides intuitive access to episode replays, real-time reward decomposition charts, agent coordination metrics, and comparative analysis across training runs. The interface supports both technical analysis for developers and operational review for commanders evaluating AI-assisted courses of action.

Figure 3: An exemplar stack for training MARL agents on a SC2-based environment using our MIXTAPE system
Technical Details
Middleware Architecture
MIXTAPE uses a microservice architecture built on containerized components as shown in Figure 3. The core middleware manages training jobs, stores results in a postgres database, and coordinates between training backends (RLlib, ePyMARL, custom implementations) and visualization frontends. This design enables deployment flexibility from individual workstations to distributed HPC clusters.
The system leverages Singularity containers for HPC deployment, ensuring reproducibility and consistent environments across different compute resources. We have validated this approach on HPC systems, with documented procedures for researchers to replicate our setup.
Explainability Approaches
Our reward decomposition system tracks individual reward components throughout episodes, displaying how agents balance competing objectives. For example, in scenarios with both combat and navigation goals, users can see when agents prioritize reaching an objective versus engaging enemies, and understand the tradeoffs in their learned policies.
Specification-based explanations represent agent policies as state machines, showing critical decision points and state transitions. This approach proved particularly valuable for understanding failure modes and identifying when agents deviate from expected behavior patterns.


Figure 4: (Top) Reward decomposition visualization. (Bottom) Agent Clustering and Graph Visualization
Agent clustering techniques (see Figure 4) analyze internal neural network activations to identify coordination patterns between team members. Building on research by Pinto et al. [1], we extended dyadic coordination analysis to N-player scenarios, revealing when and how agents synchronize their decision-making.
Custom Environment Development
We developed custom StarCraft II environments with randomized spawn locations, variable unit counts, multiple victory conditions, and realistic terrain generated from SRTM elevation data as shown in Figure 5. These environments provide more diverse training scenarios than standard benchmarks while maintaining reproducibility through controlled randomization.
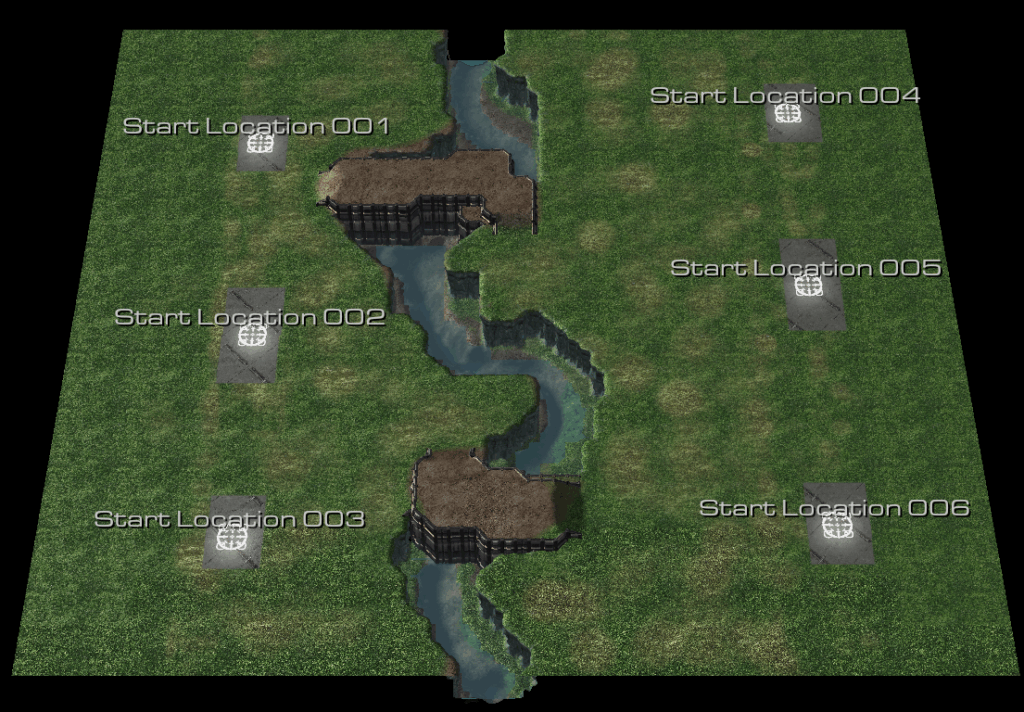
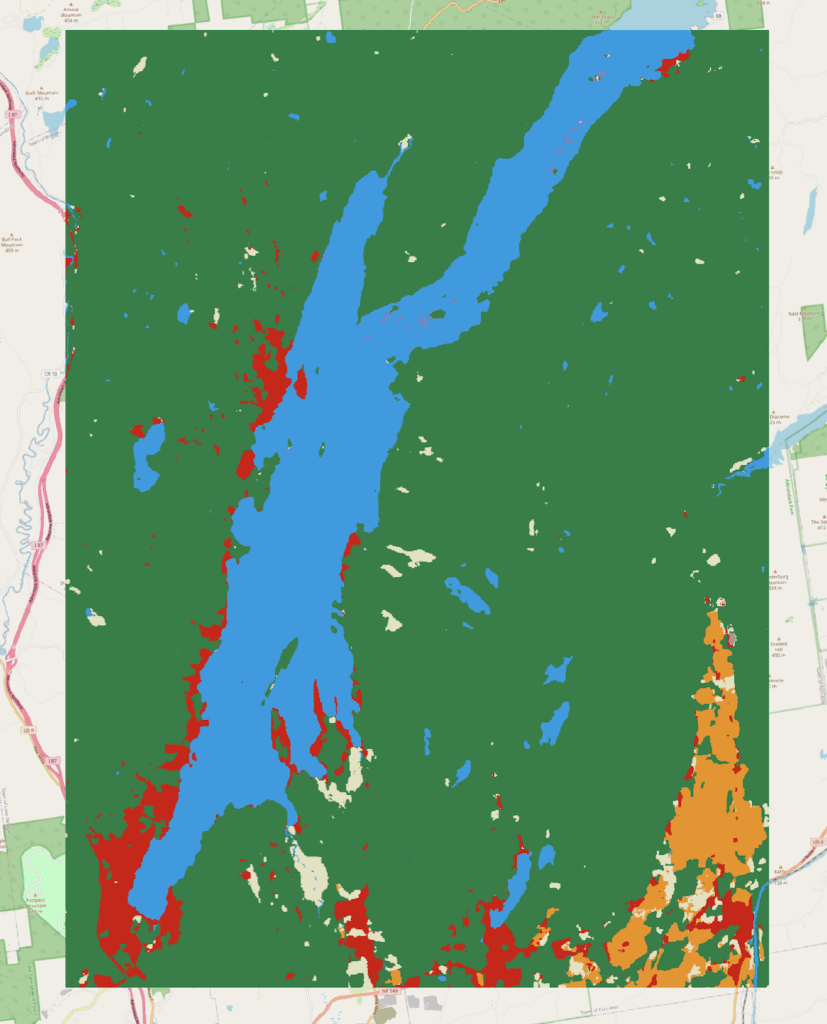

Figure 5. SCII environment creation (top) using SCII UI and map generation (bottom) using elevation (grayscale) and land use texture data
Specifically, the terrain generation pipeline converts geospatial data into StarCraft II-compatible height maps, enabling training on realistic operational areas. We have validated this approach for generating maps from user-specified regions of interest, with plans to integrate road networks and land use data from OpenStreetMap.
What Comes Next
Several development threads will mature in the coming months:
- Enhanced Multi-Objective Support: We are expanding our reward decomposition framework to support negative weights and non-linear scalarization functions. This will enable more sophisticated policy families that can adapt to varying operational priorities.
- Language Model Integration: Early experiments with LLaMA-VID show promise for generating natural language descriptions of agent behavior from gameplay footage. We are exploring how large language models can augment our existing explanation mechanisms, potentially generating after-action reviews automatically. Subsequently, we are planning to develop interfaces to integrate with LLM based agents.
- Broader Environment Support: While we have focused on StarCraft II environments, the middleware architecture supports arbitrary Gymnasium-compatible environments. We plan to document integration procedures and provide reference implementations for common wargaming platforms.
- Production Deployment Guidance: We are developing best practices for deploying MIXTAPE in operational contexts, including integration patterns with existing battlespace visualization systems and procedures for generating explainable courses of action for command staff review.
Get Involved
MIXTAPE represents an opportunity to accelerate MARL research and deployment across defense applications. The core system components of MIXTAPE have been released as fully open source (Github link), enabling researchers and developers to extend the platform for their specific use cases.
Program managers interested in applying MIXTAPE to their domains should contact us to discuss integration opportunities. We are particularly interested in connecting with teams working on multi-agent coordination problems in cyber operations, autonomous systems, and decision support tools.
Research organizations seeking to leverage the platform for academic work can access our documentation and container images. We welcome collaboration on extending the explanation mechanisms and validating them across different problem domains.
For more information about MIXTAPE capabilities, deployment options, or partnership opportunities, contact kitware@kitware.com or visit us at https://www.kitware.com/contact. We look forward to working with the community to make multi-agent reinforcement learning more transparent, explainable, and operationally useful.
References
[1]: Lima Dias Pinto, Italo Ivo, et al. “Symbolic dynamics of joint brain states during dyadic coordination.” Chaos: An Interdisciplinary Journal of Nonlinear Science 35.1 (2025).