3D Multi-Object Tracking using Lidar for Autonomous Driving

Introduction
Object tracking is a fundamental computer vision problem that refers to a set of methods proposed to precisely track the motion trajectory of an object in a video or in sequenced frames. Multiple Object Tracking (MOT) is a subclass of object tracking where the goal is to track nota single but multiple objects from one or multiple classes.
In this project, we implemented a TBD (Tracking by Detection) system on Lidar data provided in KITTI [7] dataset. In such a system, the detection and tracking algorithms are independent of each other and the tracking algorithm doesn’t have any effect on detection results.
So, contrary to a JDT (Joint Detection and Tracking) system where tracking and detection models are not independent but affect each other mostly being an unified Machine Learning (ML) model, in TBD, the tracking part is implemented on top of the detection model as an independent system which uses only the results coming from the detection but doesn’t give any feedback to the detection part. A TBD consists mostly of an ML detection model with a separated ML tracker or classical approach tracker (without using any ML mechanism).
We used here OpenPCDet [5] as the framework for training and testing object detection models on KITTI’s [7] Velodyne HDL-64E Lidar data, and a Kalman Filter for each object as the main component of the tracking step.
Object Detection vs Object Tracking
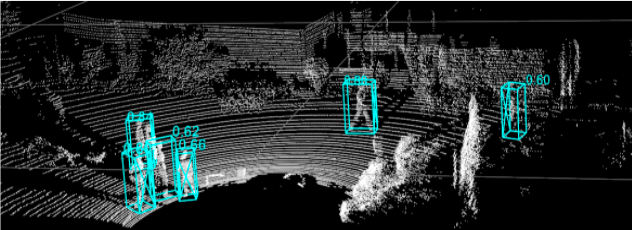
Detection is the process of identifying the presence of objects belonging to some specific classes, so in the above image, we see that the model detects some Car objects and marks them with their 3D bounding boxes having the precision score.
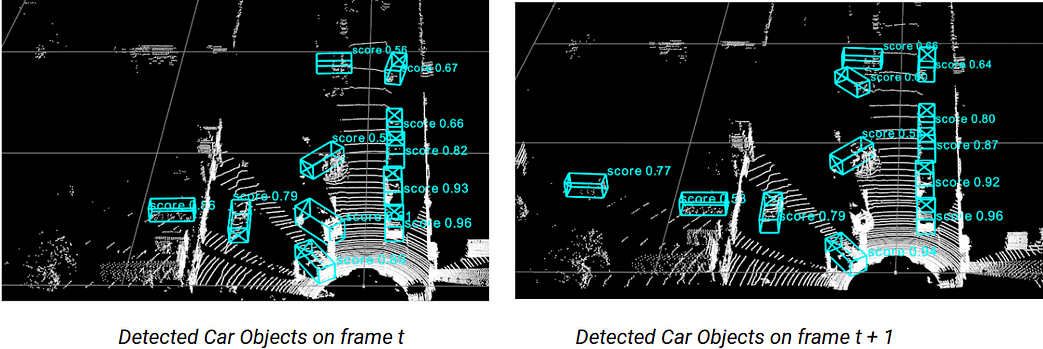
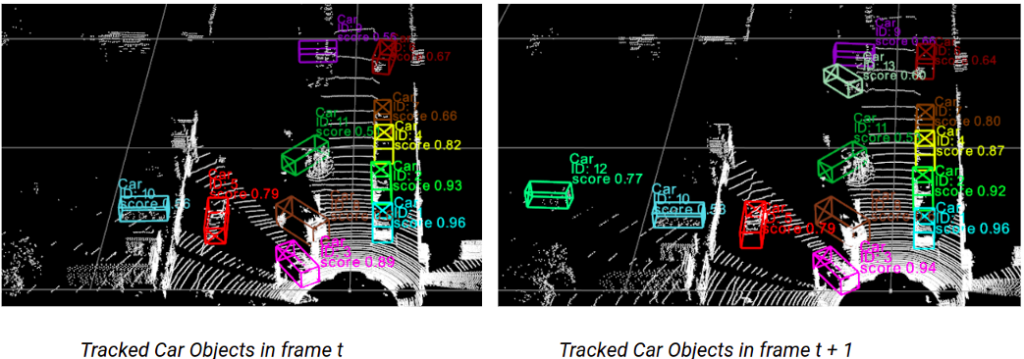
Note that a motion model may be extracted from those tracks and give an estimate of position and kinematics of each object, which can be used to predict their upcoming positions ( for instance to determine whether is in the expected trajectory of the ego vehicle )
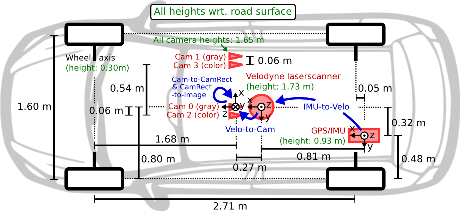
KITTI Autonomous Driving Dataset
KITTI [7] dataset is one of the main ones used for evaluation in autonomous driving applications
It has the following features in its car setup:
- 2 RGB cameras facing forward (10 Hz)
- 2 Grayscale cameras facing forward (10 Hz)
- 1 Velodyne Lidar Sensor Velodyne HDL-64E (10 Hz, 64 laser beams, up to 120 m range, ~100k points per frame)
- 8 classes are annotated in the dataset, and 3 of them are used for this project: ‘Car’, ‘Pedestrian’, ‘Cyclist’
Object Detection using Lidar
There are various architectures dedicated to object detection using Lidar, especially coming out after PointNet [1], the first paper that proposes a robust model to process Lidar data directly, without transforming the data into other forms like previous works. That model is compatible with classification and segmentation tasks mostly for smaller Lidar frames (~100 points in 1 frame) and not really compatible with huge Lidar frames like those provided by Lidars used in recent autonomous driving datasets (~100k points in 1 frame). But it gives the intuition so that the further models adapt their approach for bigger frames and create some object detection models too.
VoxelNet [2] comes right after and proposes a great architecture to process high volume Lidar data voxel by voxel instead of processing the whole Lidar frame at a time. It uses PointNet’s architecture at this “voxel processing” step to extract the features directly from the point cloud before passing to the high-resolution feature extraction with convolutions. The detector is a two-stage detector RPN (Region Proposal Network).
A further improvement comes with SECOND [3], having only one but significant change from VoxelNet. It uses Sparse CNNs [4] (Convolutional Neural Network), instead of the usual ones where the convolutional operations are applied only on “non-sparse” data. Considering that a lidar frame is highly sparse, this type of CNNs are really effective in increasing the model speed and even accuracy since the model tries to extract the high-resolution features from only sparse e.g significant data.
The last model checked for this project was Pointpillar [6], which has a similar approach to VoxelNet again. The main difference is that in this article, the point clouds are not divided into the voxels but pillars by separating the whole lidar frame only in x and y-axes but not in z. Therefore, instead of applying a 3D convolutional layer to a 4D tensor output like in VoxelNet, a 2D convolutional layer is applied to a 3D tensor output which is efficient for increasing the model speed.
Using OpenPCDet framework [5], Voxelnet, SECOND, and PointPillar architectures are trained and tested.
The table below shows the accuracy performance of different models with different thresholds
(i.e @50 means the IOU threshold is %50) and for 3 difficulty levels (Easy Medium Hard) for 3 classes Car, Pedestrian, and Cyclist.

It is seen that the SECOND Multi-head has near-accuracy results to default SECOND architecture but for more sensitive classes like pedestrians and cyclists, its results are quite better without any big change in speed. In conclusion, we chose SECOND Multi-head as the main object detection model to continue with the tracking task where multi-head refers to having not only 1 but as many as class count’s RPN head located at the detection step each of them working for 1 specific class in parallel.
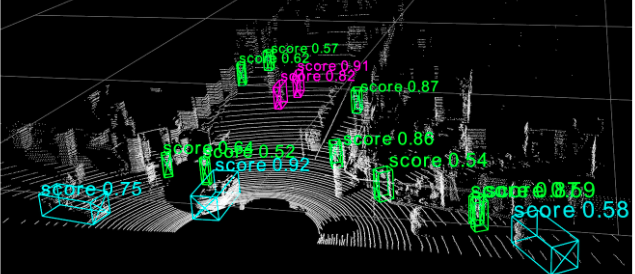
Some inference results coming from the SECOND Multi-head model are shown below!
Tracking Model Architecture
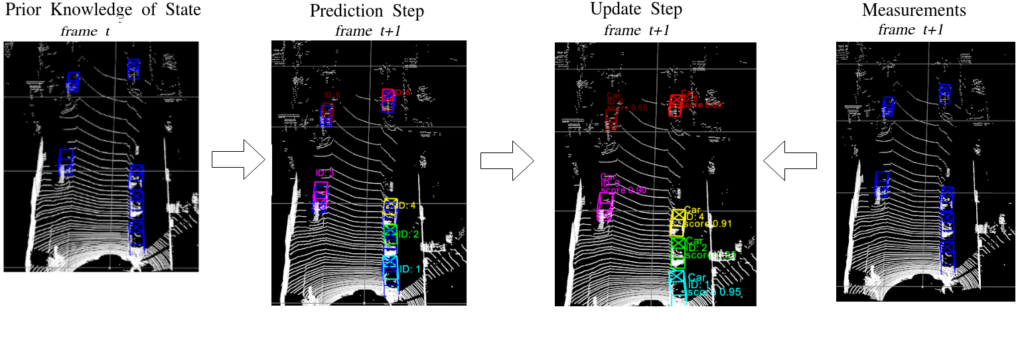
Tracking mechanism is implemented using the results coming from SECOND Multi-head object detection model frame by frame and it is based on “Probabilistic 3D Multi-Modal, Multi-Object Tracking for Autonomous Driving” paper. The model consists of three main components:
- Kalman Filter
- Mahalanobis Distance Calculation
- Greedy Match Algorithm
A constant velocity Kalman Filter is used to calculate the locations of the trackers coming from frame t, in the frame t+1 with a state vector [x, y, z, theta, l, w, h, dx, dy, dz, da]
xt = [x, y, z, theta, l, w, h, dx, dy, dz] being
x = center point of the box in x-axis
y = center point of the box in y-axis
z = center point of the box in z-axis
a = the angle between the object’s facing direction and the x-axis
l = length of the box
w = width of the box
h = height of the box
dx, dy, dz = represent the difference of (x, y, z) between the current and the previous frame.
After this prediction step, measurements are taken from object detection model for again frame t+1. In our case, these detections are 3D box locations in a 1×7 vector form:
detection = [x, y, z, a, l, w, h] being
x = center point of the box in x axis
y = center point of the box in y axis
z = center point of the box in z axis
a = the angle between the object’s facing direction and the x-axis
l = length of the box
w = width of the box
The last step is to update the Kalman predicted locations with appropriate measurements. To do that, Mahalanobis Distance is calculated between each Kalman prediction and measurement. Using Greedy Match, the measurements are associated with the detection having the lowest distance if it is not already chosen.
In the case a measurement stays unmatched, a new tracker object is created to store this possible new object coming into the frame t+1.
Additionally to these 3 main components, there are 3 important parameters that decide if a tracker should be visualized, stored in the background of the system, or deleted:
hits : counts how many times the tracker got a match in its total lifecycle
time_since_last_update : count when the last time the tracker got a match
max age: threshold to determine how long a tracker can be alive without having a match
Conclusion
Finally, we obtain a 3D Multi-Object Tracking mechanism where we can track Car, Pedestrian, and Cyclist objects with a good accuracy performance both for stationary and mobile lidar cases.
This model may be used in future work on different lidar data to showcase their potential in Driving assistance systems and autonomous driving applications.
We could also imagine running it on stationary lidar data to accurately track and count cars/cyclists or pedestrians in a scene.
Future work may also focus on implementing End to End networks and comparing them with the current results or merging those results with image-based detection algorithms.
References
[1] PointNet paper https://arxiv.org/abs/1612.00593?context=cs
[2] VoxelNet paper https://arxiv.org/abs/1711.06396
[3] SECOND paper https://pdfs.semanticscholar.org/5125/a16039cabc6320c908a4764f32596e018ad3.pdf
[4] Sparse CNNs https://arxiv.org/abs/1505.02890
[5] OpenPCDet framework https://github.com/open-mmlab/OpenPCDet
[6] PointPillar paper https://arxiv.org/pdf/1812.05784.pdf
[7] KITTI Dataset http://www.cvlibs.net/datasets/kitti/
I currently use Google Maps which is very accurate every time.