Easy Data Conversion to VTK with Python
The VTK file format is widely used to describe all types of scientific datasets. Many software applications include support to open .vtk files and variants such as .vtp, .vtu or .vth file extensions. In this blog post, we demonstrate the simplicity of converting any data format to the VTK format in order to visualize datasets using the library itself or other applications such as ParaView. The method will be illustrated with a real life scenario performing a conversion from the CalculiX solver file format (.frd) to the VTK file format.
For many scientific applications, the Python language is a popular choice due to its ease of use and broad range of libraries, including VTK. The easiest way to use VTK in Python is thus to install it via the Python package manager pip:
> pip install vtkIt is also possible to download a wheel directly from the VTK download page, or to build it from scratch with the VTK_WRAP_PYTHON CMake variable set to ON.
With VTK and Python at your disposal, the essential steps to convert your data to VTK format are the following:
- Confirm that a VTK or ParaView reader for your format does not already exist
- Choose the correct VTK data model for your data
- Read your data
- Create and fill the VTK data object with your data
- Write your data to disk using a suitable VTK writer
A reader for the CalculiX file format has been a long time request from VTK users, hence our choice of example (see this ParaView discourse post). This could serve as a basis for contributions using the first four steps above.
Step 1: Check for Existing VTK (or ParaView) Readers
Since VTK and ParaView natively support a large variety of file formats, the very first step is to check that yours is not already supported. If it is, you can skip to Step 3.2 below.
A simple way to achieve this is to download the latest release of ParaView, which is based on VTK, from the official website and try to open your file. For instance, opening a CalculiX file (.frd extension) via drag and drop opens the dialog shown below, indicating that no reader is available for this format.
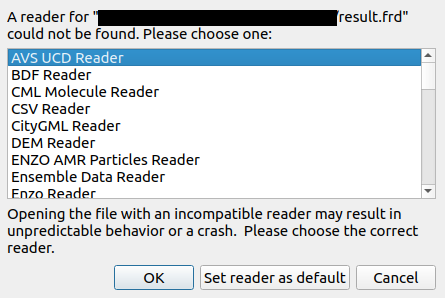
While this is a quick way of checking for most common readers, some of them are still exclusive to VTK. Feel free to search the VTK classes list for your file extension or the name of the software that produced your file (such as vtkTecplotReader or vtkPNGReader). A list of supported file formats and their corresponding readers/writers (work in progress) is also available in the official VTK documentation.
Step 2: Select a Suitable VTK Data Model
The next step is to determine the best VTK data model for the data described by your file format. Based on the format documentation and the types of datasets you wish to convert, you should select the adequate data model(s) to optimize the rendering and filter performance later on.
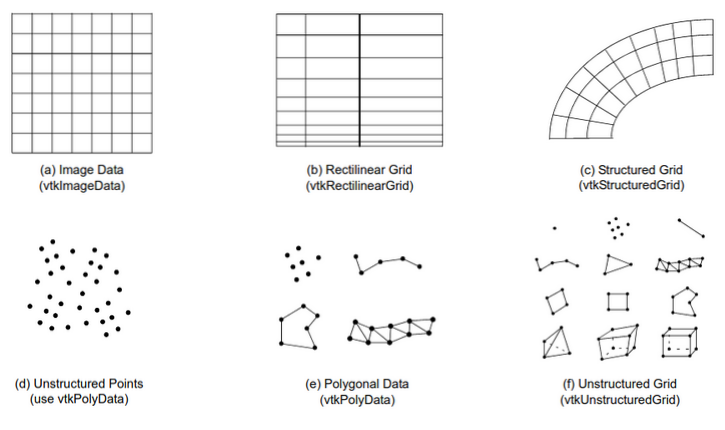
Depending on whether your data describes 2D or 3D meshes, images, and so on, you will need to match it with one of the types represented in VTK:
- Image Data
- Point Cloud
- Structured Grid
- Unstructured Grid
- Polygonal Data
- Table
- Adaptive Mesh Refinement (AMR) Data
- …
You may refer to the VTK book to learn more about VTK dataset types.
If your data format supports more than one of these types, your script can contain several code paths to use the best data model depending on the content of each input file.
The CalculiX solver outputs unstructured meshes, where each element is described both with geometry (point coordinates) and topology (cell connections). The corresponding VTK data object for this model is the vtkUnstructuredGrid class.
Step 3: Read Your Data
With this you can start writing your Python script to convert your data format. The first part consists in reading or parsing the content of your files. More precisely, the mesh description (points and cells) and relevant data arrays should be extracted. Refer to Step 3.1 if you need to parse the file yourself or Step 3.2 if VTK has a reader for your file.
Step 3.1: Read It Yourself
Most file formats can be classified into these categories:
- Unstructured text files (ASCII)
- Structured text files (CSV, XML, JSON, …)
- Unstructured binary files
- Structured binary files (HDF5, …)
One of the easiest types to read is the ASCII file format, since the content of the file is human-readable in any text editor.
Otherwise, for each of these different cases, there is a good chance that the Python ecosystem already provides an adequate tool to do the hard work. Simply try searching in a browser for the keyword “Python” followed by your file format to check whether a relevant Python module is available, such as h5py to read HDF5 files.
In our example, the .frd file format of the CalculiX solver is an unstructured text file that can be parsed manually with the following piece of code:
with open("file.frd", 'r') as f:
line = f.readline()
while line:
[...]Step 3.2: Use an Existing Reader
If your file format is already readable by VTK, you can go ahead and use the associated reader. Supposing for instance that you would like to read a TIFF image file, you can simply use the vtkTIFFReader like so:
reader = vtkTIFFReader()
reader.SetFilename("file.tif")
reader.Update()
my_vtk_dataset = reader.GetOutput()Since the reader also creates a VTK object containing your data, you can then skip to Step 5.
Step 4: Create and Fill the VTK Data Object with Your Data
The second part of your Python script should correspond to the creation of the VTK object containing your data. Based on the data type identified during Step 2, the corresponding object is created, followed by points, cells, and data arrays.
The process can be divided into specific small steps, illustrated for our CalculiX example:
1. Create the VTK object for your data model
my_vtk_dataset = vtkUnstructuredGrid()2. Create the points by defining their coordinates
points = vtkPoints()
for id in range(number_of_points):
points.InsertPoint(id, [x, y, z])
my_vtk_dataset.SetPoints(points)3. Create the cells by specifying connectivity (the cells in this example are quadratic hexahedra with 20 vertices each)
my_vtk_dataset.Allocate(number_of_cells)
for id in range(number_of_cells):
point_ids = [<insert point IDs here>]
my_vtk_dataset.InsertNextCell(VTK_QUADRATIC_HEXAHEDRON, 20, point_ids)4. Create data arrays one by one according to value type and number of components (on points here)
array = vtkDoubleArray()
array.SetNumberOfComponents(number_of_components)
array.SetNumberOfTuples(number_of_tuples)
array.SetName('My Array')
for id in range(number_of_tuples):
values = [<insert values here>]
array.SetTuple(id, values)
my_vtk_dataset.GetPointData().AddArray(array)Steps that are not relevant to the considered data type can of course be skipped (e.g. no points and cells for tables).
Step 5: Write Your Data to Disk
Now that the VTK object containing your data is ready, the last step is to save it to disk. Different VTK file formats exist for different data models. For example, the .vtp format is used for VTK polydata, while .vtt files correspond to VTK tables. Therefore, use the writer designed for the target data object type. In particular, it is recommended to use the XML writers instead of the legacy ones (which produce .vtk files) since the former ones offer more features and are more flexible. The XML writer classes for VTK formats are usually named vtkXML<Type>Writer, such as vtkXMLPolyDataWriter.
In the CalculiX example, we will thus use the VTK writer for unstructured grids (vtkXMLUnstructuredGridWriter) to produce .vtu files:
writer = vtkXMLUnstructuredGridWriter()
writer.SetFileName("output.vtu")
writer.SetInputData(my_vtk_dataset)
writer.Write()Step 6: Enjoy!
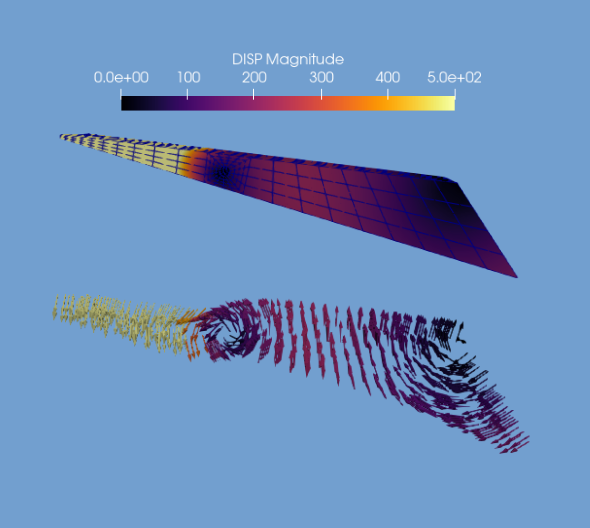
Your newly converted data is now ready to be imported within various software applications. In our example, the converted CalculiX file is visualized in ParaView by displaying the displacement using 3D arrow glyphs.
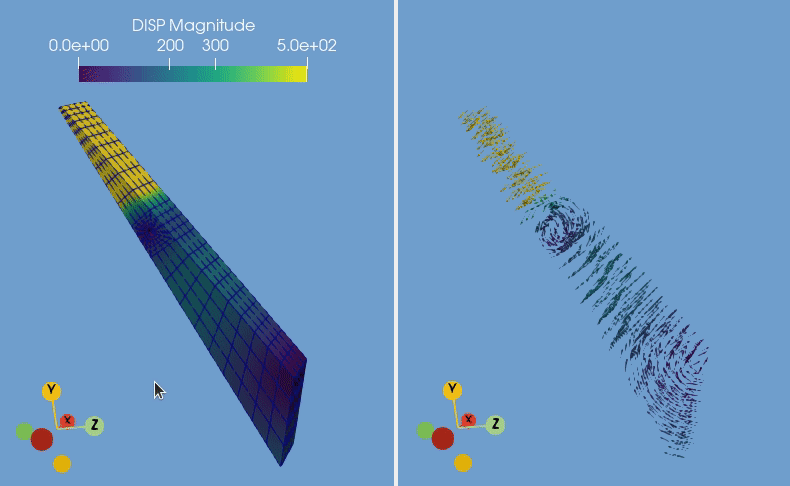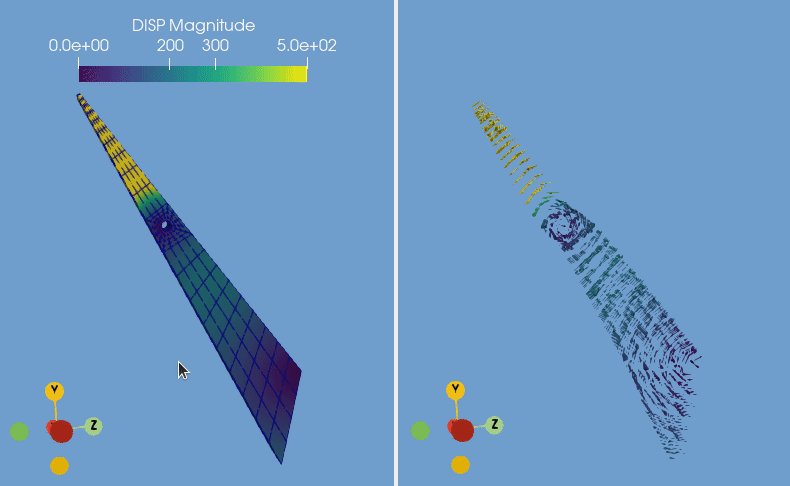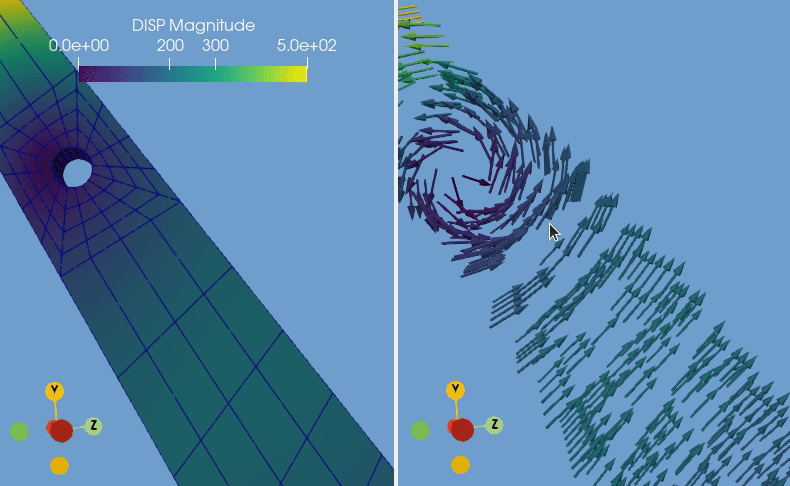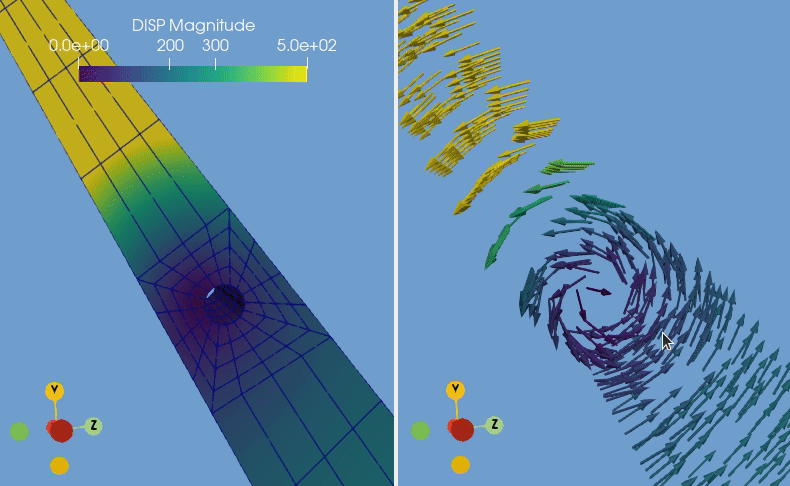
If you wish to have a deeper look into the script used in the CalculiX example, you can find it at this link.
Another example is available for the conversion of an HDF5 file to a VTK image data with the Combustion Open Data from the Center of Excellence RAISE.
About Kitware
Kitware Europe’s Scientific Visualization Department has extensive expertise in meshing algorithms, but also in multiple other fields such as massive datasets processing and visualization, in-situ visualization of simulation data, various rendering techniques, and much more.
Whether you are from a research organization or a commercial product company, feel free to reach out here to discuss technical needs or collaboration opportunities.
A great article, one other thing that is useful is to use pandas to read structured ASCII files (CSV) from here you can select what columns to use, use numpy and also write out a temporary csv file for use with vtkDelimitedTextReader.
Great post! Here is an example of how to read MFEM mesh and results files into ParaView by creating a custom reader in Python:
https://github.com/benzwick/paraview-mfem-reader
Interesting. Can the current version of Paraview convert .r3d file to let’s say .vtk?