Faster data loading in VTK
Introduction
VTK 9.3 has seen an improvement to its data file loading process and related performances. Let’s take a look at the VTK data loading process, what has changed since the last VTK release, and what are the benefits for performances!
Performance analysis
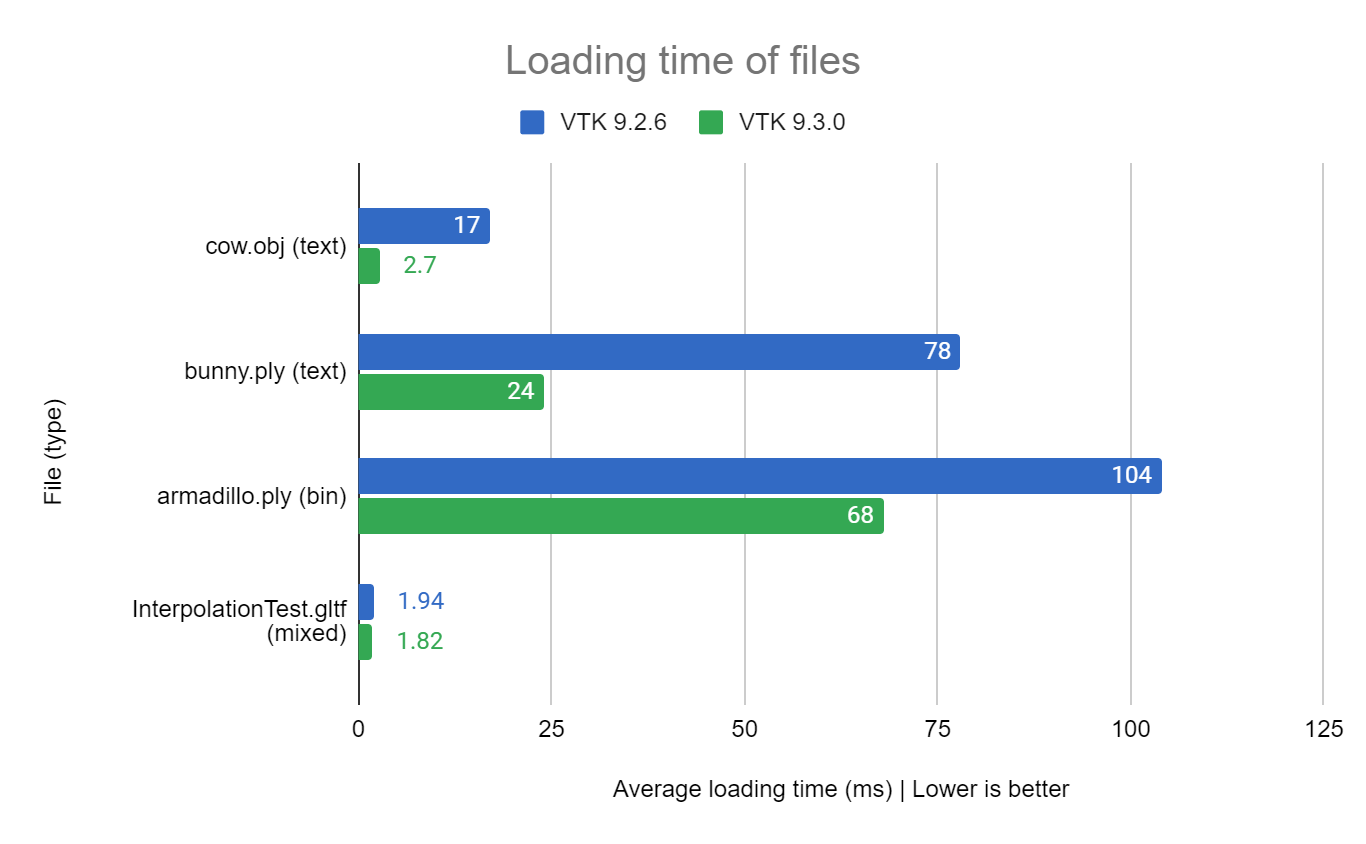
Thanks to the new vtkResourceParser, and a little bit of refactoring, vtkOBJReader is now about seven times faster than before, and can now load OBJ from any kind of stream (e.g. string) instead of being limited to file names. vtkPLYReader also benefited from vtkResourceParser, it is now about three times faster than before when reading text encoded PLY files, and also has a 35% performance improvement when reading binary encoded PLY files.
Performance of text-encoded files, with vtkOBJReader and vtkPLYReader, is significantly increased thanks to the new number parsing algorithm included in vtkResourceParser.
Parsing of binary-encoded files with vtkPLYReader is also faster thanks to the “ReadLine” function of vtkResourceParser that is about four times faster than its standard counterpart, std::istream::getline.
vtkGLTFReader performance does not change much, because JSON parsing is still handled by the same third-party JSON parser. The difference in the previous graph is not significant and is probably related to the few changes induced by vtkResourceStream support.
All tested files are part of VTK testing data.
What changed
If you are curious about what lead to those improvements and the motivations behind the changes, read the next sections, otherwise, jump to the current status part.
Current status of data loading in VTK
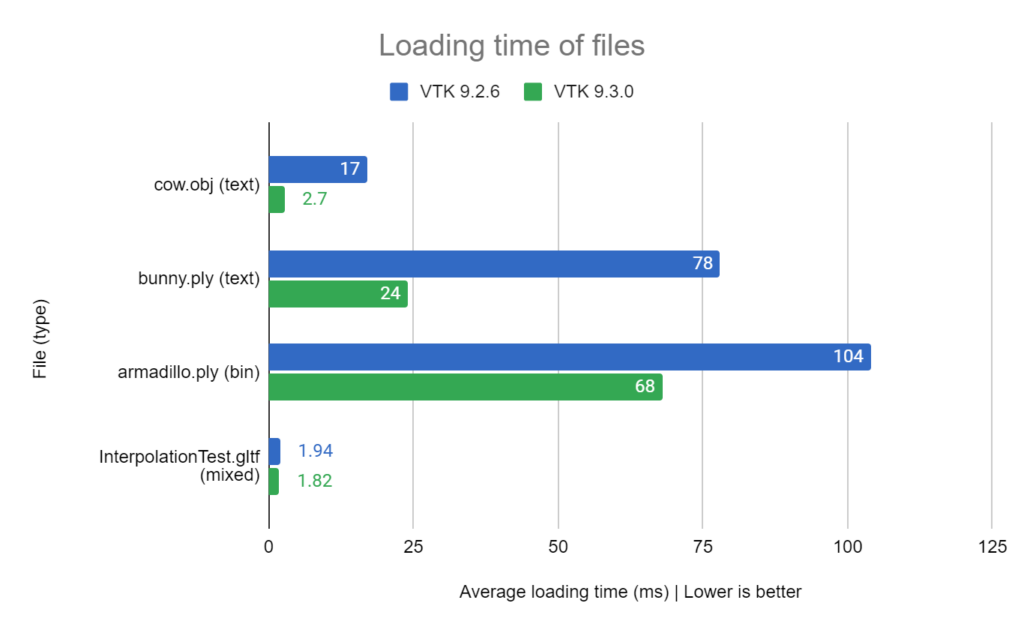
When it comes to loading data, VTK 9.2 and older had one standard way of doing it, the SetFileName() function. It was the only function defined in every reader.
Some readers implement other ways to load data, generally using a string as input, which induces a copy of input data, and more sparsely, a raw buffer.
This had the following limitations:
- Inconsistent API; some readers supported more input methods than others. The only common input method being via file names.
- Some readers only support file names; if data comes from another source such as a web resource, data would have to be written to a file and then read back from it.
- This has drawbacks. First one is performance, because of file system access. Second one is more code, which reduces maintainability and also creates more opportunities of making errors. Last one is other questions that may need to be answered, such as: where to put this file ? Putting confidential data on disk may also require more work to ensure it can not be accessed later.
- Some readers support reading from a string; but this always performs an additional copy of input data.
Present and future of data loading in VTK
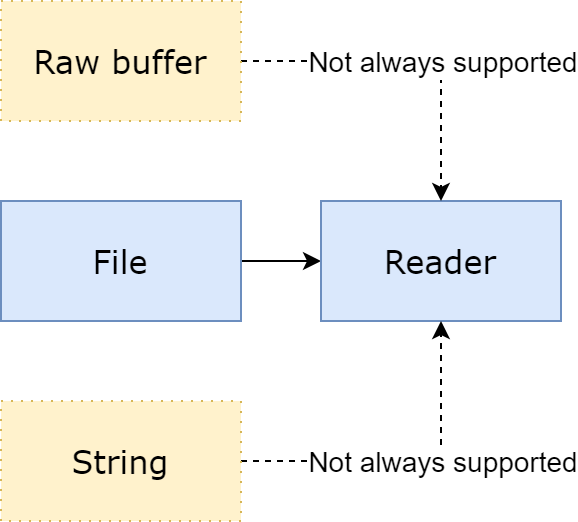
Resource streams are intended to become the new standard for data loading in VTK 9.3; they provide a common, simple and extensible interface for data loading.
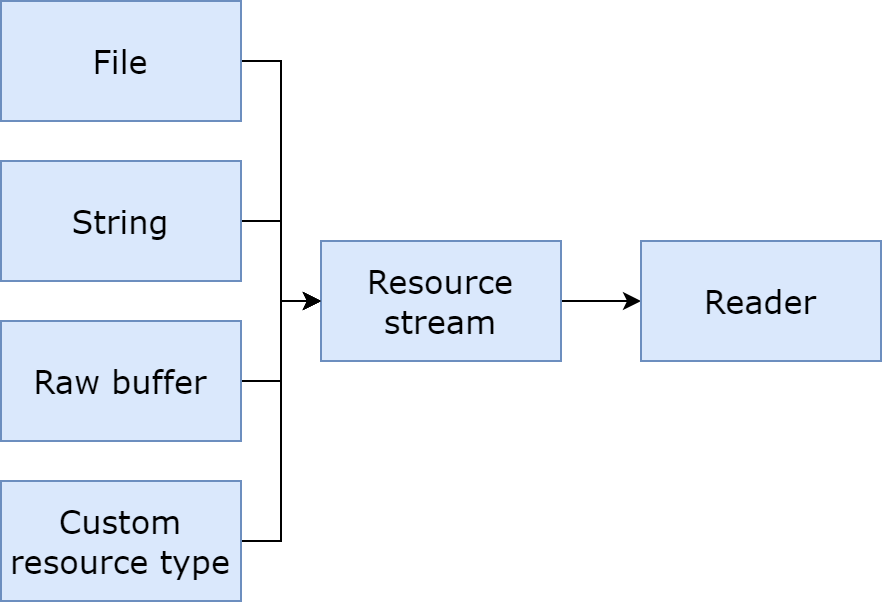
A resource stream is represented by the vtkResourceStream class, an abstract class that represents a raw data stream (i.e. sequence of bytes).
This abstract class has four virtual methods: Read, EndOfStream, Seek and Tell. Only the two firsts are required. When only the two firsts methods are defined, the stream is “non seekable”. These four methods are standard stream functions that can be found in most languages. vtkResourceStream is an input stream, but may become a bidirectional stream in the future.
Current implementation supports file input, through vtkFileResourceStream, and memory input through vtkMemoryResourceStream. Additional streams supporting other types of resources, such as web resources or object storages, can easily be added in the future.
Current status
| Reader | Status | VTK version |
|---|---|---|
| vtkPLYReader | ✅Done | Merge Request | 9.3.0 |
| vtkOBJReader | ✅Done | Merge Request | 9.3.0 |
| vtkGLTFReader | ✅Done | Merge Request | 9.3.0 |
| vtkXMLReader (vti, vtp, …) | 📅 Planned | TBD |
Possible contributions
A lot of work still needs to be done in order to support resource streams everywhere in VTK and more ways of loading data:
- Add resource stream support to all readers and importers
- Add new resource stream types to support other input methods, e.g. HTTP(s), zip archives…
Please reach out to Kitware if you need our support with this work.
Acknowledgement
This work has been implemented by Kitware Europe and was funded by the CALM-AA European project (cofunded by the European fund for regional development).

It’s great to hear about the rearchitecting to allow data to come from sources other than files. What was the fundamental change that enabled an almost order-of-magnitude speed increase for OBJ and PLY files?
The main improvement is the replacement of the standard float parsing function (strtod, istream, etc) with the fast float parsing implementation from Daniel Lemire (https://github.com/fastfloat/fast_float). This simple change make text based format that mainly contains decimal values to be read way faster. This is the reason why text-based formats benefit that much of vtkResourceParser.
Other improvements have been done on different aspects of file parsing, such as implementing faster algorithm for line-by-line reading, better code architecture (especially in vtkOBJReader) and a slightly faster text to int parsing algorithm.
This is very cool from a WebAssembly point of view. I’ve currently hit a limit attempting to load a
.vtpfile larger than 2GB in chrome because the chrome JavaScript engine cannot allocate more than 2 billion bytes for ArrayBuffer. Both the input string and file modes involve a copy from the javascript heap onto the webassembly heap. This motivates me to investiage if it’s possible to connect Web Storage API to VTK with a custom vtkResourceStream.