High-Performance Computing Made Easy with MoleQueue

One of the goals of the Open Chemistry project [1,2] at Kitware is to provide a simple, easy-to-use interface for submitting chemical simulations to be executed on high-performance computing (HPC) resources. To this end, we have developed MoleQueue — a system-tray resident server application that uses standard inter-process communication channels to interact with programs that generate and analyze simulation data. It enables applications such as the Avogadro molecular editor to easily interact with remote computing resources to perform calculations that are not feasible on a typical workstation. MoleQueue’s functionality is not limited to chemical simulations; it provides a generic interface to a variety of HPC resources suitable for use by any number of application domains. MoleQueue’s functionality is currently being applied to diverse fields at Kitware, such as large scale climate[3] and fluid dynamics[4] simulations.
Traditional HPC Workflow
In order to appreciate how an application integrated with MoleQueue can simplify an HPC user’s workflow, the figure below shows the typical workflow when using a HPC resource. Here the simulation component leads to job submissions, with a possible informatics/data storage step, and then results are generated on the nodes of the resource and brought back into a package for further analysis.
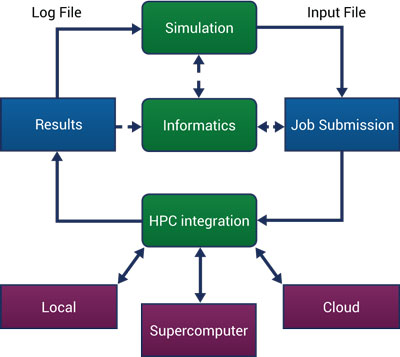
Initially, the researcher generates program-specific input files on their local machine, either using a dedicated application or by formatting and configuring the files manually with a text editor. The input files are then copied to the remote HPC cluster using a file transfer protocol, such as SFTP or SCP. Next, the user runs an SSH client to log into the remote system and obtain a command prompt, which is typically a shell on the head node of a Linux cluster. The user navigates to the simulation’s working directory using shell commands, and creates a submission script to configure the execution environment for the calculation. This submission script is sent to the cluster’s job scheduler, and the calculation begins as soon as the requested resources become available.
If one wants to monitor the job then it is necessary to log back into the cluster, execute commands to obtain a listing of all jobs in the scheduler, and locate their job in the output; or to configure the scheduler to email status updates to the submitter. Once a job has completed, the output files would normally be manually copied back to the local workstation using SFTP/SCP for further analysis. There is also the added complication of figuring out how to accomplish these tasks locally for small test runs, or on cloud resources for larger, on-demand submissions.
This workflow can be quite daunting for new researchers due to the steep learning curve associated with many of the technologies. A user must learn how to use and configure SSH and SFTP clients, interact with the cluster’s scheduler, set up the execution environment for each queue and program, and navigate and manipulate files from a command prompt. As we’ll see in the next section, MoleQueue automates most of this process, allowing the user to concentrate on their domain-specific research, rather than worrying about the details of job scheduling.
The MoleQueue Workflow
Using MoleQueue to perform a simulation consists of two stages: a one-time set up of the queues and programs they can access, and the submission of specific calculations.
One-time Set Up
Import Preset Configurations
The one-time set up of MoleQueue consists of configuring cluster login details, scheduler interactions, and program execution environments. Fortunately for non-technical users, MoleQueue provides a method for importing preset configurations. This feature enables site maintainers and research groups to provide users with an appropriate configuration file. In this case, setup will consist of simply importing the file through the MoleQueue user interface.
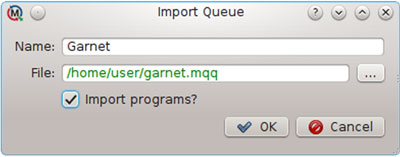
User specific settings such as login names and working directories would still need to be set, but the bulk of the technical details concerning scheduler interaction and program execution will be configured by the importer.
Manual Configuration
More advanced users (or those with less generous system administrators) can configure resources themselves using the MoleQueue application as detailed in the following sections.
Adding a Local Queue
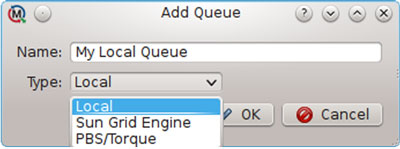
A local queue for performing calculations on a user’s workstation can be created by opening the Queue Manager in MoleQueue, clicking “Add,” and selecting the “Local” queue type.
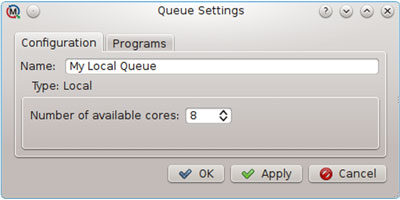
Configuring a local queue is simple — all it needs to know are the number of processor cores the user wishes to use for calculations. MoleQueue will automatically detect the number of available cores and use this as the default value.
Adding a Remote Queue
Queues on remote HPC clusters are added by selecting the type of scheduler running on the cluster. The Portable Batch System (PBS) and Sun Grid Engine (SGE) schedulers are currently supported, along with their descendants (i.e. Torque (PBS-like)) and OpenGrid (SGE-like)). The setup for each of these is similar, so we’ll use the PBS/Torque configuration as an example.
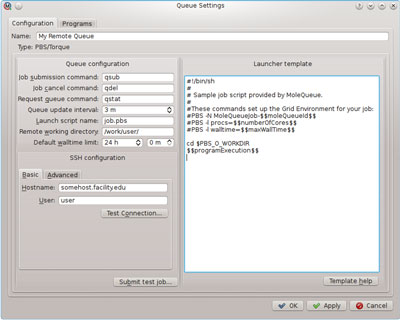
The remote queue’s configuration is initially set to reasonable default values. The status of running and queued jobs will be queried every three minutes; the standard qsub, qdel, and qstat commands will be used to interact with the scheduler, and the batch script will be written to job.pbs. A fully customizable batch script template is provided, using keywords such as $$numberOfCores$$ and $$maxWallTime$$ which will be replaced with job-specific options, and the $$programExecution$$ keyword which is replaced by program-specific execution details.
The connection to the remote host is configured by setting the hostname or IP address of the cluster’s head node (somehost.facility.edu in this example) and the name of the username that will be used during login (“user” in the above example). The “Test Connection” button will attempt an SSH login to the configured host, allowing for connection troubleshooting if necessary.
Submitted jobs will be copied to and submitted from the “Remote Working Directory” (/work/user above). “Submit Test Job” can be used to send a trivial job to the configured queue, enabling users to test their configuration.
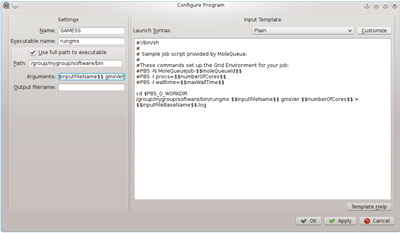
Adding Programs to a Queue
Program execution environments are fully configurable. Several presets for common execution syntaxes are available for simple programs, or the entire batch script template can be customized for more complex simulations. This allows programs to make use of advanced resources such as a specific MPI implementation for multi-node parallelism, configuration of environment variables, etc.
Job Submission with a MoleQueue Client
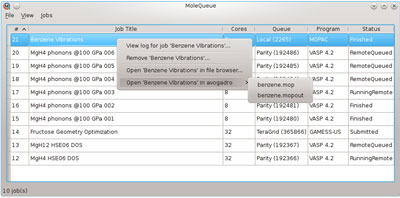
Once the initial setup of queues and programs is finished, performing a simulation using software that is integrated with MoleQueue is simple: prepare the simulation, select the target queue and program, and click submit in the client application. MoleQueue takes over at this point by copying the input files to the server, scheduling the job, and monitoring the remote queue until the job is complete. When the calculation finishes, MoleQueue will copy the output files back from server and notify the client that the job is complete. The user doesn’t need to use SSH directly, learn shell commands, or interact with the scheduler.
If the calculation finishes before the client software has been closed, the output file can be opened and analyzed, or used as a starting point for a new calculation. This approach enables client software to implement fast, efficient workflows for performing complex simulations. Alternatively, more complex calculations that require weeks or months to complete can be started from the client software and will continue to be monitored by the MoleQueue server application until complete. The application maintains state between sessions, so stopping and restarting the server program will not affect job monitoring. When a job completes, the output can be opened in an appropriate application directly from the job listing in MoleQueue.
Implementation
MoleQueue is an open-source, cross-platform C++ Qt application developed to provide an abstraction to local and remote computational resources. It consists of two primary components: a system-tray resident application that acts as a job dispatch server, and a small client library that provides an interface to the remote procedure call (RPC) API, which interacts with the server component. In addition to handling client requests, the server manages a local job queue where calculations can be scheduled for execution on the local workstation, and also directs communication and data exchange with remote HPC resources. Two client libraries are provided with MoleQueue: a C++ library extending Qt, and a Python module.
MoleQueue Client-Server Communication
The messages transmitted between the client and server are formatted using JavaScript Object Notation (JSON) and adhere to the JSON-RPC 2.0 specification. The JSON format was chosen due to the vast array of implementations in virtually every programming language; JSON-RPC 2.0 builds upon the JSON data format in order to provide a cross-platform, device-independent RPC API that can easily be implemented in any language desired. Exchange of messages occurs over standard inter-process communication channels: local sockets on Unix-like platforms and named pipes on Windows. Optional support for the ZeroMQ message passing interface is also supported (where available).
The JSON-RPC API is documented online[5], and the simple exchange below exemplifies the simplicity of the format. A client may query the available programs and queues on the server by sending a message such as:
{
“jsonrpc” : “2.0”,
“method” : “listQueues”,
“id” : 42
}
The server’s response to this request will contain a key-value map, with the names of the available queues (Gold, Tritium, and Local in this case) as the keys, and lists of available programs as the values:
{
“jsonrpc” : “2.0”,
“result” : {
“Gold” :
[ “GAMESS”, “MOPAC”, “Gaussian”, “NWChem” ],
“Tritium” :
[ “GAMESS”, “MOPAC”, “Gaussian”, “NWChem” ],
“Local” :
[ “GAMESS”, “MOPAC”, “Gaussian”, “NWChem” ]
},
“id” : 42
}
A slightly more complex RPC call to submit a job using MoleQueue would look as follows:
{
“jsonrpc” : “2.0”,
“method” : “submitJob”,
“params” : {
“queue” : “Tritium”,
“program” : “GAMESS”,
“description” : “B3LYP H2O optimization”,
“inputFile” : {
“filename” : “job.inp”,
“contents” : “Full contents of input file.\n
Will be created in the working
tree.”
}
},
“id” : 23
}
This submits a job to the remote queue named Tritium, with the program named GAMESS. The description is the string that will show up in the MoleQueue user interface, and the input file is specified by either a full path to an existing file or filename and content strings. The response for a successful submission looks something like the following:
{
“jsonrpc”: “2.0”,
“result”: {
“moleQueueId”: 17,
“workingDirectory”:
“/home/user/.molequeue/jobs/17/”
},
“id”: 23
}
This response object gives a long lived identifier for the job, moleQueueId, and the working directory where all of the files will be staged. Once a job is submitted, notifications are sent when the job state changes; for example, from submitted to running, error, completed, etc. Each of the notifications carries the moleQueueId of the job and the previous and current states. It is then possible for the client to act upon these changes to, for example, open output files once the job has finished. There are also RPC methods to query job status, or to cancel an already submitted job.
Submitting Jobs using the C++ Client
When considering adding MoleQueue functionality to an existing Qt-based C++ application, the C++ MoleQueue client library is a great choice. It takes care of generating the JSON-RPC 2.0 calls for you, and will emit signals when responses or notifications are received from the server.
The following code shows the basic process of submitting a job from a C++ application.
#include <molequeue/client/client.h>
#include <molequeue/client/job.h>
// Create the client
MoleQueue::Client client;
// Create a job to submit.
MoleQueue::JobObject job;
job.setQueue(“Tritium”);
job.setProgram(“GAMESS”);
job.setInputFile(“/path/to/job.inp”);
// Connect to the correct signal, the slot
// is called jobResponse.
connect(&client,
SIGNAL(submitJobResponse(int, uint)),
this, SLOT(jobResponse(int, uint)));
// Submit the job to the queue, the job submission
// gives the local ID, the signal gives the local
// ID (int) and the moleQueueId (uint).
int localId = client.submitJob(job);
The slot can match up the local ID to the returned MoleQueue ID, and all future queries or notifications will use the MoleQueue ID. Other actions have corresponding signals that can be used, and the C++ API is asynchronous.
Submitting Jobs Using the Python Client
In order to submit a job with MoleQueue, application code must be written that connects to MoleQueue and makes the appropriate remote calls. One of the easiest way to do this is with the Python API, which allows job submissions from simple Python scripts.
The following code snippet shows the basic process of submitting a job in Python:
# create molequeue client
client = molequeue.Client()
# connect to server
client.connect_to_server(‘MoleQueue’)
# create Job
job = molequeue.Job()
# set the queue that the job will be submitted to
job.queue = ‘Tritium’
# set the program to run
job.program = ‘GAMESS’
file_path = molequeue.FilePath()
file_path.path = “/path/to/job.inp”
# Set the input file path
job.input_file = file_path
# now submit the job to the server. This methods
# will return the MoleQueue ID that can in used
# in other method. For example to cancel the job.
molequeue_id = client.submit_job(job)
print “MoleQueue ID: “, molequeue_id
# finally disconnect from server so resources can
# be cleaned up.
client.disconnect()
Conclusions
The MoleQueue application can be used to interact with local and remote computational resources and provides a user-friendly configuration interface. Client libraries allow application developers to integrate HPC functionality with their software. This provides a rich and compelling user experience by lowering the barriers faced by new researchers and saving time previously spent configuring simulation environments. Support for several common job schedulers is available, and the application framework is available on Windows, Mac, and Linux. Client applications may interact with the MoleQueue server from any language using standard communication protocols and data exchange formats.
References
[1] http://www.openchemistry.org
[2] http://www.kitware.com/source/home/post/39
[3] http://uv-cdat.llnl.gov
[4] “Computational Model Builder (CMB): A Cross-Platform Suite of Tools for Model Creation and Setup,” Hines, A.,
et al. DoD High Performance Computing Modernization Program Users Group Conference, 2009.
[5] http://wiki.openchemistry.org/MoleQueue_JSON-RPC_Specification
 Marcus Hanwell is Technical Leader in the scientific computing team at Kitware, where he leads the Open Chemistry effort. He has a background in open source, open science, Physics, and Chemistry. In addition to leading the Chemistry team at Kitware, he is also the lead developer of Avogadro.
Marcus Hanwell is Technical Leader in the scientific computing team at Kitware, where he leads the Open Chemistry effort. He has a background in open source, open science, Physics, and Chemistry. In addition to leading the Chemistry team at Kitware, he is also the lead developer of Avogadro.
 David Lonie is an R&D Engineer on the scientific computing team at Kitware. He has been active in the open-source chemistry community since 2009, developing for various projects such as the Avogadro editor and the Open Babel toolkit.
David Lonie is an R&D Engineer on the scientific computing team at Kitware. He has been active in the open-source chemistry community since 2009, developing for various projects such as the Avogadro editor and the Open Babel toolkit.
 Chris Harris is an R&D Engineer at Kitware. His background includes middleware development at IBM, and working on highly-specialized, high performance, mission critical systems.
Chris Harris is an R&D Engineer at Kitware. His background includes middleware development at IBM, and working on highly-specialized, high performance, mission critical systems.