Meta-configuration of C/C++ projects with CMake

Project configuration in software development is the process of setting up “how” your code will be built, managed, and/or run. It varies depending on the programming language and tools used, such as the IDE. For instance, when programming in C/C++, the project setup usually entails defining what artifacts (e.g., executables, libraries) will be built from certain source code files, with given compiling and linking options. In Microsoft Visual, this can be completed, for the most part, with wizards, menu, and contextual commands. For example, you can configure your directories containing external libraries in a dialog (Project Properties).
Other languages, especially interpreted ones such as node or python, typically require much less project configuration or setup. In languages such as Java, project setup can be accomplished with IDEs including Eclipse or Netbeans. Nevertheless, the use of Maven is more extended. Maven allows you not only to define how the project has to be built, packaged, executed, or tested, but it also allows you to specify dependencies to binaries artifacts (jars), which can be retrieved from external servers.
In the C/C++ ecosystem, the best tool for project configuration is CMake. CMake allows you to specify the build of a project, in files named CMakeLists.txt, with a simple syntax (much simpler than writing Makefiles). From those files, CMake can generate projects for the most popular IDEs and build systems on different OSs. It is a must-have tool. It is the de-facto standard in the industry for the C/C++ multiplatform and even for single OS development. We love it. We have used it for a long time in our own projects and, as professors, we have taught it from the first day in our Software Engineering courses.
C/C++ project meta-configuration
What is project meta-configuration? You probably already know something about meta-programming. Meta-programming is a process in which the code you write (e.g., a C++ template) is the specification or instructions for how the real code will be generated by a system (in the case of C++ templates, the compiler).
In biicode, meta-configuration is the process in which the project setup is completed (most of the time automatically) by collecting information about the project and user intentions from different origins. For example, the source code itself is a great source of information that can be exploited for this purpose.
Let’s see how it works with the well-known example “Hello World.” Imagine someone (“user1”) starts to write code and writes the following three (simplified) files for a Hello World application.
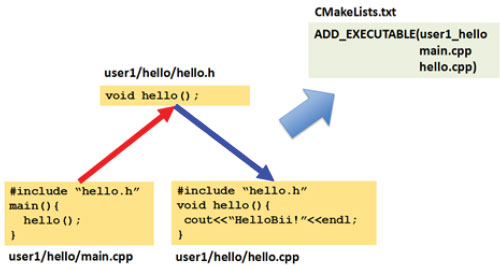
Fig. 1. Automatically generating a CMakeLists.txt from the source code. There is a main.cpp file that defines an entry point for an executable, which depends by #include to a hello.h header, which in turn is implemented by a hello.cpp.
Analyzing the source code, it is clear that the user wants to build an executable (from the main function, in green) that includes the file “hello.h” (red). By cross-checking declared and defined symbols in “hello.h” and “hello.cpp,” it can easily be deduced that the implementation (blue) of the function hello() is found in the “hello.cpp” file and, therefore, it is required to build the application. Accordingly, a CMakeLists.txt such as the one depicted above could be automatically generated.
What makes this automatic generation of the CMakeLists.txt file interesting? If a couple of new files are added and included by “main.cpp” or “hello.cpp,” they will automatically be added to the executable. If the user wants to create a new executable, all they have to do is write a file (with whatever name) with a main() function inside. That is, the user just has to focus on writing code. The rest of the process can practically be automated. Although real, large-scale multiplatform projects usually have a complex building process, which probably cannot be automatically fully deduced, this approach can be very valuable for students, programming courses, rapid prototyping, testing, etc.
Integrating dependencies
Biicode allows you to very simply publish and share your source code to the biicode cloud. You (or anyone else in the world) can later easily reuse code in another project. All you have to do to reuse previously published code is to write a #include directive in your code in the form of “username/block/path/to/file.h.” If biicode does not find such a file locally, it will look for it in biicode cloud and retrieve it into your project, along with other files (included by or implementing such file, i.e., red and blue arrows in the graph). What happens with such source code?
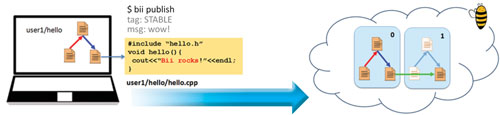
Fig. 2. Publishing code to the biicode cloud is very easy, as it requires just a simple command. The source code files, together with the meta information (such as the dependencies between files), are also uploaded so the user does not have to define any package or write any configuration at all. If the user modifies one file and publishes again, the server tracks information about the changes that can afterwards be used to check compatibility in the user dependencies graph.
It is retrieved as source code, not as binaries, so it has to be built locally. The source files could just be directly added to the executable, but it seems more intuitive to define a library that contains such files, as they will not usually be edited by the user and link the executable to such a library.
For example, imagine that the user, “user2,” is developing a simple chat application and includes the “hello.h” file previously published by “user1.” After invoking biicode, “user 2” ends with the following layout of files, from which a CMakeList can also be easily deduced.
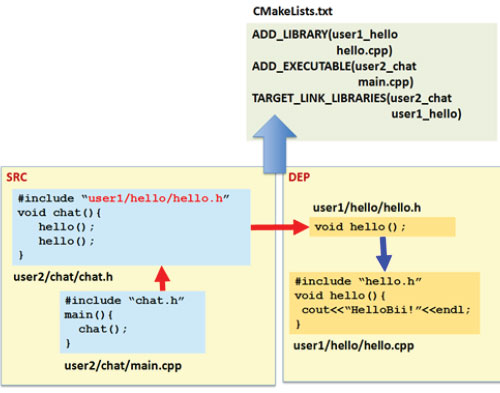
Fig. 3. In this example, “user2” has written some code and added a #include to the code previously published by “user1.” The biicode system automatically finds it in the server and retrieves the files “hello.h” and “hello.cpp” to the “user2” machine. These files are automatically integrated in the project, creating a library with CMake. Note that the “user1” main.cpp file has been automatically removed here, as it is not a real dependency so it is not included in the build and, thus, it does not generate a because of multiple definition of “main” function error link.
CMake integration
Obviously, the above approach is not very useful; if the CMakeLists.txt is continuously generated, there is little chance that the user can actually use his or her own configuration and adapt the project to his or her specific needs.
The files inside the CMake folder are automatically generated by biicode. The CMakeLists.txt is created just once, so the user can modify its contents if necessary.
PROJECT( hello ) ... # This file defines variables INCLUDE(bii_vars.cmake) # This file defines the actual targets using the # variables in the above file INCLUDE(bii_targets.cmake)
It includes two other files, also generated by biicode. These two files are overwritten every time the “bii” tool is called and there are changes in the project.
The first file, “bii_vars.cmake,” creates variables that define the targets to build, as well as their properties, but does not create those targets yet. Some variables might be empty, but they are declared here for the user’s convenience. A very simplified example for “Hello World” could be:
SET(TARGET_user1_hello_main_NAME user1_hello_main) SET(TARGET_user1_hello_main_FILES ../blocks/user1/hello/hello.cpp ../blocks/user1/hello/hello.h ../blocks/user1/hello/main.cpp)
The other “bii_targets.cmake” file is the one that actually defines the targets to be built, based on the variables declared in the previous file:
ADD_EXECUTABLE( ${TARGET_user1_hello_main_NAME}
${TARGET_user1_hello_main_FILES})
TARGET_LINK_LIBRARIES(
${TARGET_user1_hello_main_NAME}
${TARGET_user1_hello_main_LIBS})
Using this file makes it very simple to define or customize the building process. Users can edit the used variables in the CMakeLists.txt between the two included .cmake files. They can even completely drop the “bii_targets.cmake” and define their own targets. Note that this approach does not exclude the possibility of users having their own CMakeLists along with their source code or even of having other cmake files that could be included from the biicode generated CMakeList.txt one. For example, if your code is using boost (only header libraries), a simple approach could be:
PROJECT( hello ) ... # This file defines variables INCLUDE(bii_vars.cmake) INCLUDE_DIRECTORIES(path/to/boost/installation) # This file defines the actual targets using the # variables in the above file INCLUDE(bii_targets.cmake)
Of course, you can also use the FIND_PACKAGE features of CMake for such a purpose. In fact, we are already using it to find and configure projects with well-known dependencies, including large and massively used libraries such as WxWidgets or Boost, so that it will be enough for users to just #include what they want. Biicode is able to fully configure the project if a local installation of such libraries is found.
Ongoing work
We are currently working toward better integration with CMake and are trying to empower the synergies between both tools. CMake is incredibly powerful and has advanced features (e.g., INTERFACE targets) that are a very natural fit for some biicode requirements. We also like the OBJECT library targets, which could be very helpful for many of our use cases. However, we have a problem here. As I said, biicode can be great for students and beginners, many of whom are using mainstream linux distributions, as could Ubuntu 12.04 LTS. These distributions come with a CMake 2.8.7 version, which does not yet support these features. We are currently evaluating the policy as follows: force our users to manually upgrade CMake on their machines so we can use those features or implement hacks and workarounds in biicode that offer the same final functionality.
We are also working in a better binaries products management. Biicode always builds executables and libraries from source, but it still lacks integration or support with “install” features. Here, we are concentrating on automatically generating packages and package information so that generated binaries can also be easily discovered and used with FIND_PACKAGE.
Conclusion
In this post, I have introduced a new approach to C/C++ project configuration: meta-configuration from user information, mainly source code. This is a powerful approach that can lower barriers for students and new users of the C/C++ language. However, we are also working on supporting more languages such as node and python (even fortran thanks to CMake fortran support), as well as embedded systems including Arduino and RaspberryPI.
We currently target users of the major OSs: Windows (mingw, Visual), Linux (Ubuntu only now), and MacOS. We could not have reached our current functionality without CMake; it is the most required element in our tool chain. We cannot imagine developing C/C++ projects without CMake and, thus, we have integrated it in biicode from the very first moment. The fact that we use CMake has been widely accepted by our users, as it is something they know and value very highly. As we are just using a fraction of CMake’s power, our next steps involve using more of its power, as well as creating more value for the CMake community by helping to automate some tasks in the package definition process.
Acknowledgement
This work is partially funded by Spanish Ministry of Economy, under Program INNPACTO (Ref: SDT- Scalable Development Tools: IPT-2012-0797-430000)
References
1. www.biicode.com
2. http://web.biicode.com/blog/meta-configuration-of-cc-projects-with-cmake-1

Diego Rodriguez-Losada is an Industrial Engineer with an M.S. in Mechanics and a Ph.D in Robotics. He is the co-founder and CTO of biicode, where he currently enjoys one of his great passions, SW development.
He is an Associate Professor (now on a leave) at Universidad Politecnica de Madrid UPM and a researcher at Intelligent Control Group, a research group located at DISAM laboratory in Madrid, Spain, that belongs to the Center for Automation and Robotics CAR UPM-CSIC.
While his main research interest is Mobile Robots Navigation, specifically Simultaneous Localization and Mapping (SLAM), he has been involved in a variety of robotics and industrial projects.