Open Reproducible Electron Microscopy Data Analysis
Members of Kitware’s Scientific Computing Team and our collaborators at the the National Center for Electron Microscopy (NCEM) have been working on a Phase I SBIR project funded by the Department of Energy (DOE) to develop a prototype platform for reproducible electron microscopy (EM) data analysis. This article will provide the motivation for the project, walk through our overall approach, and conclude with a look at future work.
Motivation
Electron microscopy (EM) is a powerful technique for understanding structure and composition at the nano- to atomic-scale for applications across various scientific domains. The technique generally utilizes focused electron beams to measure biological and hard materials’ physical and electronic structure. Thus, EM is a cornerstone technique for identifying structure-property relationships in fields such as in biology, where the molecular structure is directly correlated to functionality. Advances in technologies means that one acquires datasets at increasingly large rates and sizes. We can measure materials at the nano- to atomic-scale with a lower dose, higher speeds, and improved precision.
These advancements present enormous opportunities for researchers to understand complex systems. However, processing the resulting large-scale, complex data in a reproducible and shareable way is a real challenge for the researchers. Building, managing, and maintaining complex workflows in a reproducible manner requires extensive knowledge in several areas that are usually outside the researchers’ core skill set, such as software engineering, data science, and high-performance computing (HPC).
A diverse set of open source packages exist in the EM space, such as Hyperspy, LiberTEM, py4DSTEM, and Nion Swift. They are implemented in a variety of languages with their own specific dependencies. There is a real opportunity to allow many of these packages/tools to work together by providing an inter-operable graphically based user interface which can support the diverse existing data formats and provide the ability to combine packages/tools in the same pipeline, building on the community’s existing investments.
The Open Reproducible Electron Microscopy Data Analysis (OREMDA) project seeks to meet these challenges by exposing advanced algorithms and tools in a user-friendly way so that end-users may utilize them without being programming experts. We are creating an open source, permissively licensed, high-performance, web-based platform for the experimental data community.
Approach
Our approach is to use containers to encapsulate processing logic into reproducible processing operators (operator containers) that can be combined into pipelines. These pipelines can be built up through a web application, providing drag-and-drop editing of a processing graph. The use of containers allows us to encapsulate a disparate set of technologies and use them within the same pipeline. Containers have many benefits in terms of portability and reproducibility. They allow a complete processing pipeline to be moved across platforms and between collaborators, providing true reproducibility. Container technologies have established image repositories for distributed container images; we are leveraging these to allow operator containers to be shared between collaborators. The diagram below shows a high-level overview of the components of the OREMDA platform.
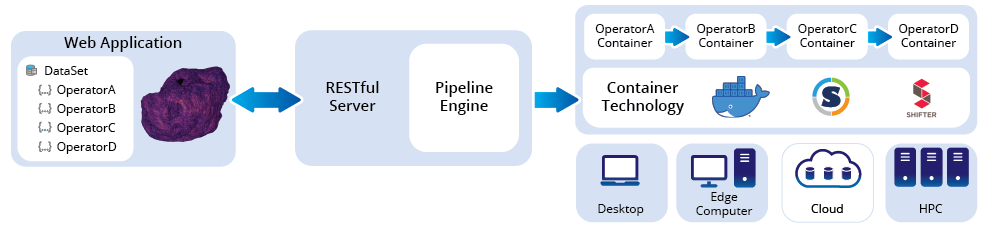
To connect containers into pipelines, we need to annotate them with appropriate metadata. Containers in OREMDA pipelines conform to a container interface. This is a well-defined specification that describes the operator, including inputs and outputs. We are using labels to store this information on container images. The advantage of this approach is that we can inspect the images without having to run a container.
Here is an example of labels used to describe a container operator to perform a gaussian blur, built using a Dockerfile:
LABEL oremda.name="gaussian_blur"
oremda.description="Apply a Gaussian filter"
oremda.ports.input.image.type="image"
oremda.ports.output.image.type="image"This metadata is used to validate a pipeline and determine how operators can be connected in the UI.
A pipeline is a graph that is described using a JSON document, which defines the nodes (the containers), their parameters, and the connectivity between them (the “data flow” within a pipeline). Below is a snippet of a pipeline definition.
{
"nodes": [
{
"id": "10",
"image": "oremda/ncem_reader_eels",
"params": {
"filename": "08_carbon.dm3"
}
},
{
"id": "11",
"image": "oremda/background_fit",
"params": {
"start": 268,
"stop": 277
}
},
...
],
"edges": [
{
"type": "data",
"from": { "id": "10", "port": "eloss" },
"to": { "id": "11", "port": "eloss" }
},
...
]
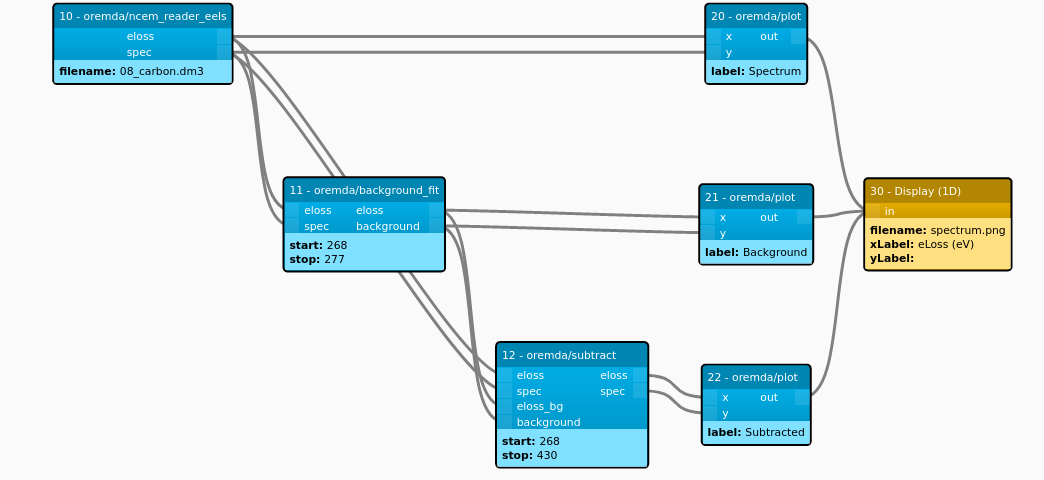
}These pipeline documents are created by the UI as a user builds up their pipeline by dragging container operators onto a canvas. Below is the graphical representation from the UI of the full pipeline the JSON snippet was taken from.
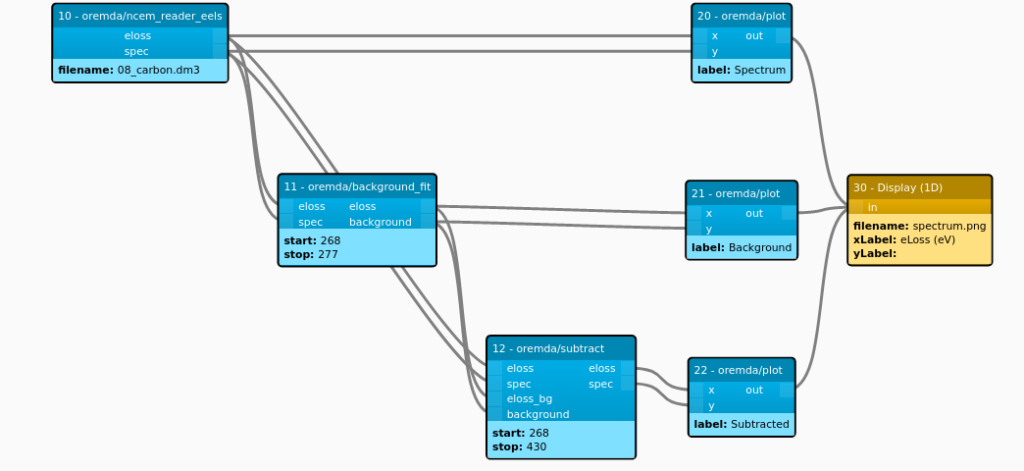
For a pipeline to be executed, its operator containers need to be able to efficiently pass data through the pipeline. Operators also need a shared understanding of how various EM datasets are formatted. In OREMDA, shared memory is used to pass data between operators using language agnostic in-memory data formats designed by Apache Arrow. Apache Arrow defines a language-independent columnar memory format for flat and hierarchical data, and provides libraries in many popular languages. We are also using Apache Arrow’s Plasma In-Memory Object Store to manage our shared memory as it is used within the pipeline execution.
Pipeline execution starts with the instantiation of the containers used within the pipeline. One of the costs associated with using containers is the startup overhead. We try to mitigate this first by starting all the containers simultaneously in parallel, and also by starting the containers only at the beginning of the first execution of the pipeline; subsequent executions use the same containers, and thus avoid the startup overhead. This enables pipelines to support interactive parameter optimizations, which require the pipelines to be executed several times as the user tunes the parameters. Once the containers are running, the pipeline graph can be traversed to execute each operator. The pipeline engine communicates with the operators using interprocess communication (IPC) queues. This allows the execution to be coordinated across containers and processes. We have implemented a set of terminal operators, called display operators, that can be used to visualize pipeline output. The screenshot below shows the UI for a peak fitting pipeline after it has been executed. The left hand side shows the pipeline topology and the right hand side shows the output of the display operators.

To support deployment in a variety of environments, we support a range of underlying container technologies such as Docker and Singularity. We have implemented a container interface layer that abstracts away the particular container technology that we are using in a specific deployment. So, for example, on the desktop we can use docker but on an HPC deployment we may use Singularity. We have also generalized the internal messaging so that the pipeline is able to communicate with operators on separate nodes using MPI. This allows the pipeline to run operators in parallel on an HPC cluster.
We currently have first-class support for implementing operators in Python. However, our technology choices will allow us to support other languages in the future. Our Python implementation hides all the complexity associated with inter-container communication and coordination. The developer can concentrate on implementing a single processing function that is annotated with a decorator. An example operator is shown below, taken from a background subtraction pipeline.
from oremda import operator
@operator
def background_fit(inputs, parameters):
start_eloss = parameters.get("start", 0)
stop_eloss = parameters.get("stop", 0)
eloss = inputs["eloss"].data
spec = inputs["spec"].data
assert eloss is not None
assert spec is not None
start = eloss_to_pixel(eloss, start_eloss)
end = eloss_to_pixel(eloss, stop_eloss)
background, _ = power_fit(spec, (start, end))
outputs = {
"eloss": {"data": eloss[start:]},
"background": {"data": background},
}
return outputsOREMDA is designed to be deployed across a wide range of platforms from desktop, edge, and cloud, right through to HPC. With this in mind, functionality is broken down into a set of services that can be deployed in a variety of configurations. For example, the pipeline engine responsible for executing the pipeline can run on an HPC resource to allow it to run tasks in parallel across nodes. The client-server components communicate with each other using RPC over websockets.
Conclusion
Over the past year, we have developed a prototype platform that has been used to validate many of the ideas that we laid out in our initial proposal. We have demonstrated the power of combining container technology with shared memory techniques, enabling truly reproducible pipelines that are portable across platforms. We have driven our development using real-world EM data and workflows. Although this work has focused on EM workflows, we feel that it has broad reach across many domains. Future work will include more interactive visualizations, optimizing pipeline execution and support for multi-user environments and collaboration.
For further information or to get involved please visit our code repository.
This work was funded by the U.S. Department of Energy, Office of Science, Office of Basic Energy Sciences, Small Business Innovation Research (SBIR) program under Award Number DE-SC0021601.