Unsupervised segmentation on aerial point-cloud data in LidarView
3D scene understanding is challenging because of the inherent sparsity property of point-cloud data. In the meantime, 2D image understanding algorithms have already achieved near human-level perception, with a growing research community trying to improve the state of the art.
One idea to process 3D data is to actually project it into a 2D view and then apply a 2D pipeline. Such methods are well suited for aerial point-cloud segmentation if using the bird-eye view. This is why we introduced the segment-lidar plugin, which uses the latest LAS reader from LidarView 4.4.0 release that leverages PDAL library which is widely used for point cloud data translation, in particular in the geospatial domain.
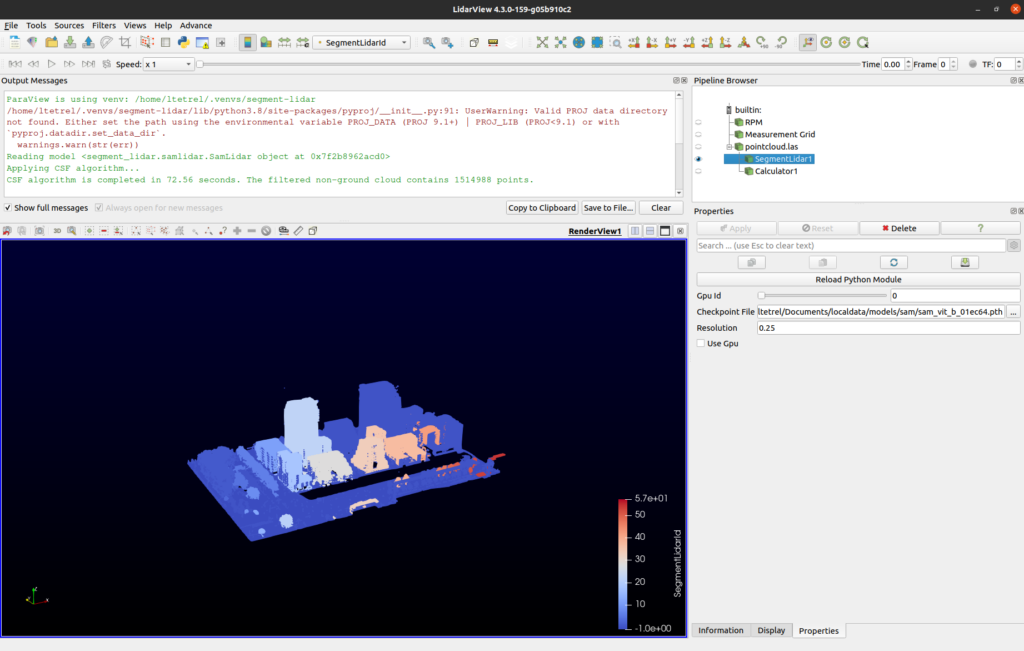
The segment-lidar plugin in action inside LidarView
Understanding the foundation model behind the plugin
The segmentation capability relies on a specific model that made a lot of noise recently: Segment Anything Model (SAM) [1].
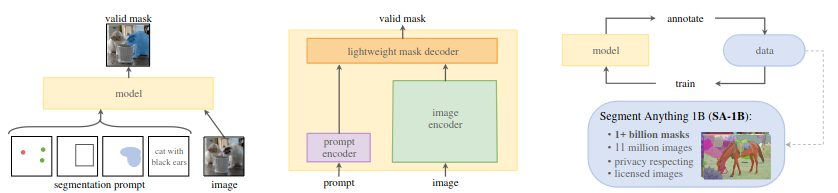
SAM is what we call a “foundation model” for computer vision, which can basically generalize to tasks and data distributions beyond those seen during training. More specifically, Its purpose is to be used as a pre-trained model in computer vision. In their recent paper they showcase this model for a promptable segmentation task:
Segment Anything Model (SAM): a new AI model from Meta AI that can “cut out” any object, in any image, with a single click
However, SAM capabilities goes beyond a simple model as it could be used as a data engine to generate new training data, or help in user-assisted annotation. It also extends quite well to other domains, such as medical imaging for example [2].
The Meta AI team made a significant impact in the computer vision community thanks to:
- An original semi-automated active learning approach: the algorithm first uses human annotation, and slowly transitions to a full self-supervised approach.
- Adapting the self-supervised masked auto-encoder for promptable segmentation [3]: using sparse or dense prompts encoded in the same latent space as the image features.
- A model suited for inference speed: by decomposing the feature extraction and mask decoder.
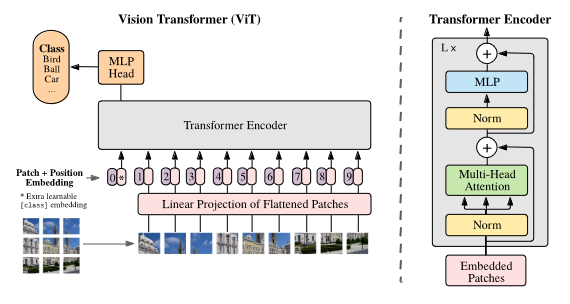
It uses under-the-hood the famous Vision Transformers block which helps in taking into account important regions in the image for the prediction (concept of attention) [4], in contrast to typical image processing using CNNs.
Applying SAM to bird-eye-view of 3D data
The whole idea behind segment-lidar is to actually use SAM on a bird-eye-view of the colored point cloud. The process of projecting a scene into a 2D image plane is actually called “rasterization”. One may think that doing such is not a good idea because of the sparsity of the point cloud. However, due to the nature of its capture, reprojection of aerial data actually gives quite a dense view and that is why it can be used here.

The library segment-lidar is actually a wrapper around segment-geospatial, with the addition of the rasterization of the LIDAR point cloud and ground estimation using a Cloth Simulation Filtering.
Installing and using the python plugin in LidarView
We will be using the same python venv workflow as the previous deep-learning plugin that we recently released for 3D detection.
The installation instruction is available in the LidarView public repository for deep learning plugins, and you must use our internal fork of segment-lidar. After installing the python plugin, make sure to first test outside of LidarView using this sample data and the python binary provided in bin/segment-lidar.
Before running the script, you will need to load the SegmentLidar.py plugin inside LidarView:
- if not yet active, activate the advanced mode in order to be able to load the plugin using by ticking Advance Features in the Help menu,
- load the
SegmentLidarpython plugin using the Advance > Tools (paraview) > Manage Plugins… menu, - if you want the plugin to be automatically loaded when opening LidarView, tick the Autoload box.
This plugin is only available for LAS and colorized point-cloud data, after loading the data you should see the SegmentLidar filter available.
There are few options available:
- Checkpoint File: is the SAM model you want to use,
- Resolution: defines how much resolution (in mm) you want for the rasterized image, the bigger the resolution, the smaller the resulting image will be,
- Use Gpu: a checkbox to enable GPU if you have enough video memory,
- Gpu Id: which GPU to choose among the ones available on your system.
Results
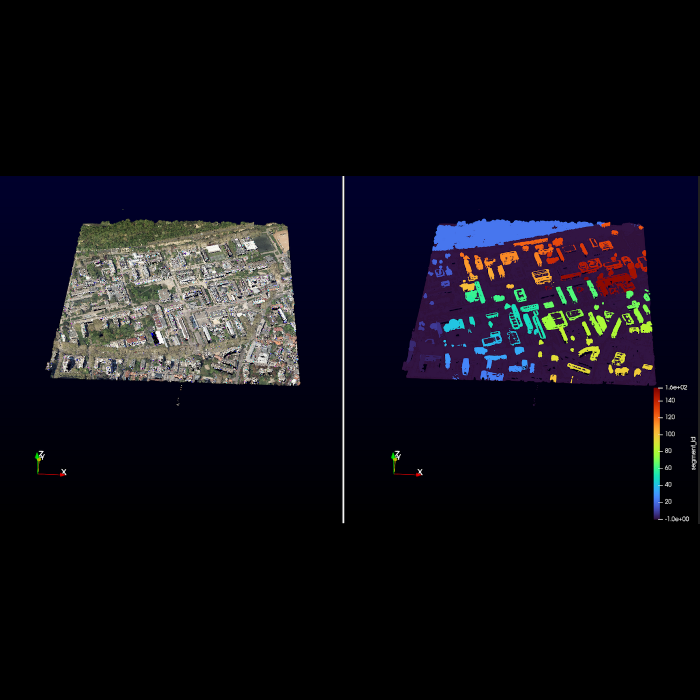
The following figure gives you an example of the segment-lidar plugin running inside LidarView, using the sample data from AHN-4.
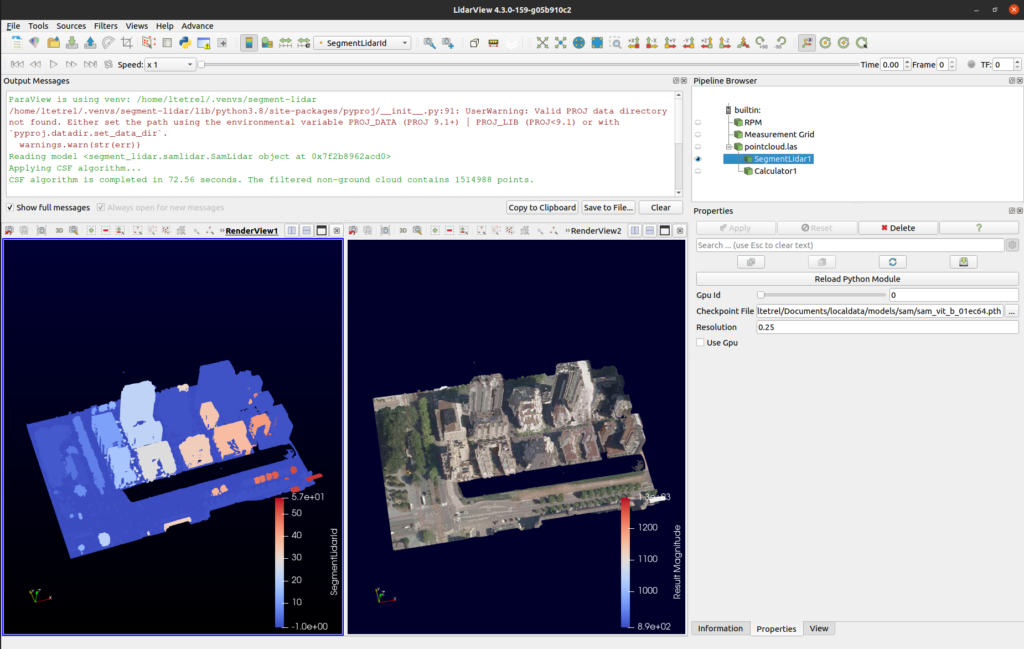
And here, on a bigger scale, on a las file captured in Lyon by GrandLyon metropole (as of 2018).

What’s next?
There are quite a few leads of development for such applications in the future which include:
- Running this process headlessly on huge amounts of data using the power of the client-server architecture of Paraview that is embedded in LidarView and its distributed architecture
- Improving the algorithm to add 3D constraints on the segmentation, including improving the a priori ground segmentation
- Merge aerial Lidar Data with ground-based acquired data (which can now be colored) to fill the holes of the aerial data and retrieve a more complete segmented map (as demonstrated here)
- Add more specific processing, such as building segmentation as in [5] or [6].
Do you have a use case in mind that could use this? Feel free to contact us to see how we can support you and concretize it !
References
[1] Kirillov, Alexander, et al. “Segment anything.” arXiv preprint arXiv:2304.02643 (2023).
[2] Shi, Peilun, et al. “Generalist vision foundation models for medical imaging: A case study of segment anything model on zero-shot medical segmentation.” Diagnostics 13.11 (2023): 1947.
[3] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[4] Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[5] Zhang, Y.; Yang, W.; Liu, X.; Wan, Y.; Zhu, X.; Tan, Y. Unsupervised Building Instance Segmentation of Airborne LiDAR Point Clouds for Parallel Reconstruction Analysis. Remote Sens. 2021, 13, 1136. https://doi.org/10.3390/rs13061136
[6] Jin Huang, Jantien Stoter, Ravi Peters, Liangliang Nan. City3D: Large-scale Building Reconstruction from Airborne LiDAR Point Clouds. Remote Sensing. 14(9), 2254, 2022.