VTK Shared Memory Parallelism Tools, 2021 updates

In this blog post, we will see the last improvements that have been made on VTK SMP Tools. Note that previous blogs on the SMP Tools are available: Simple, Parallel Computing with vtkSMPTools and Ongoing VTK / ParaView Performance Improvements.
The SMP Tools provides a set of utility functions which can be used to parallelize parts of VTK code on shared memory architectures, taking advantage of multithreaded CPUs. Several back-ends are currently available: Sequential, TBB, OpenMP and the new STDThread.
In this blog we will see various API Improvements such as new parallel methods (Transform and Fill), an improvement on the control of threads number and the support of standard iterators for the For method. Then we will introduce a new SMPTools backend which uses the native C++ standard library along with a performance benchmark between backends. Finally, we will present the possibility to change SMPTools backend at runtime.
These changes are already available in VTK master branch and will be added in the next VTK release.
API Improvements
We made some changes on the existing SMPTools API which was already supporting:
- Initialize allows the maximum number of threads to be changed.
- GetEstimatedNumberOfThreads to get the maximum number of threads.
- GetBackend gets a string with the currently used backend name.
- A For method, to execute a parallel operation on a range, with configurable grain.
- A Sort method, to sort a range of values in parallel.
New parallel methods
Here, we introduce two new SMPTools methods: Transform and Fill, which are based on the same prototype as their std counterparts:
- Transform applies a functor on each element of the container, evaluated each time (cf. std::transform),
- Fill will replace each element with the result of a method evaluated once (cf. std::fill).
As these methods are easy to use, we are hoping it will motivate people to discover and use VTK SMP Tools.
Below, you will find an example of Transform used with the range support of a vtkDataArray (see: https://blog.kitware.com/c11-for-range-support-in-vtk/).
// Initialize tests values
std::vector<double> data0 = { 51, 9, 3, -10, 27, 1, -5, 82, 31, 21 };
std::vector<double> data1 = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
// Pass the vectors values to an AOSDataArray
vtkNew<vtkDoubleArray> array0;
vtkNew<vtkDoubleArray> array1;
array0->SetArray(data0.data(), data0.size(), 1);
array1->SetArray(data1.data(), data1.size(), 1);
// Get the DataArrayValueRange from the DataArray
const auto range0 = vtk::DataArrayValueRange<1>(array0);
auto range1 = vtk::DataArrayValueRange<1>(array1);
// Call vtkSMPTools::Transform()
vtkSMPTools::Transform(range0.cbegin(), range0.cend(),
range1.cbegin(), range1.begin(),
[](double x, double y) { return x * y; });
// Array1 should contains { 0, 9, 6, -30, 108, 5, -30, 574, 248, 189}This code comes from Common/Core/Testing/Cxx/TestSMP.cxx
Thread control
We decided to give the user more control on the number of threads, and we can now change it with the VTK_SMP_MAX_THREADS environment variable (on supported backends: OpenMP, TBB and STDThread). This environment variable will act as a maximum thread limiter and will replace the threads default maximum. This environment variable cannot be changed during execution. Note that Initialize can still be used to configure the maximum number of threads.
However Initialize has a limitation, once called with a given number of threads, all future SMP Tools execution will use this new number of threads (even if in another filter) unless another Initialize is called. This is mainly due to the static nature of the current SMP Tools. It is important to know that a call to Initialize without any number will reset the maximum number of threads (either with the environment variable or the limit defined by the backend).
Local Scope
In order to enhance the control users have on the number of threads locally, and more generally the SMP Tools config, we added the convenient method: LocalScope. It is allowed to call a SMP Tools method and modify the SMP Tools configuration within its own scope, all that as a one liner!
Currently, vtkSMPTools::Config contains two parameters: MaxNumberOfThreads and Backend which allows the SMP Tools backend change. This configuration structure is intended to be expanded and new parameters could be added, such as NestedParallelism.
Changing the thread count may be especially useful when the processing is large enough to be parallel but not large enough to spawn a high number of threads.
Here is an example of LocalScope that limits a For with 4 threads maximum:
vtkSMPTools::LocalScope(vtkSMPTools::Config{ 4 },
[&]() { vtkSMPTools::For(0, size, worker); });Another example of LocalScope that limits a Sort with 2 threads maximum and set the backend to TBB:
vtkSMPTools::LocalScope(vtkSMPTools::Config{ 2, "TBB" },
[&]() { vtkSMPTools::Sort(myVector.begin(), myVector.end()); });Iterators support
For can now be used with standard iterators which can be useful to traverse non indexed containers like set or map.
Below is a simple example of such a use case:
template<class IteratorT>
struct ExampleFunctor
{
vtkSMPThreadLocal<int> Counter;
ForRangeFunctor() : Counter(0) {}
void operator()(IteratorT begin, IteratorT end)
{
for (IteratorT it = begin; it != end; ++it)
{
this->Counter.Local() += *it;
}
}
};
std::set<int> mySet = { 25, 72, 12, 23 };
ExampleFunctor<std::set<int>::iterator> worker;
vtkSMPTools::For(mySet.cbegin(), mySet.cend(), worker);We could also use a lambda such as:
vtkSMPTools::For(myVector.begin(), myVector.end(),
[](std::vector<double>::iterator begin, std::vector<double>::iterator end) {
for (std::vector<double>::iterator it = begin; it != end; ++it)
{
*it *= 2;
}
})Backend improvements
STD backend presentation
In order to improve SMP Tools, we decided to introduce a std::thread backend. This new backend doesn’t need any external dependencies as it relies on the C++ standard library (the std::thread library is implemented on top of pthreads, on linux). Therefore it should be convenient for users who can’t directly use OpenMP or TBB libraries. This allows us to have a threaded backend available on all platforms by default.
Note that std::thread backend should become the default one soon, but the sequential backend will still be available for debugging.
Thread Local Reminder
A thread local object helps to safely store variables in a parallel context. It maintains a copy of an object of the template type for each thread that processes data, it creates a storage for all threads. The actual objects are created the first time Local() is called.
When using the thread local storage object, a common design pattern is to write/accumulate data to local objects when executing in parallel. Then in a sequential reduce step, iterates over the whole storage to do a final accumulation.
Here is a simple example of a vtkSMPThreadLocal usage:
// ARangeFunctor uses a ThreadLocal variable to increment Counter the size of the range independently of threads.
class ARangeFunctor
{
public:
vtkSMPThreadLocal<vtkIdType> Counter;
ARangeFunctor() : Counter(0) {}
void operator()(vtkIdType begin, vtkIdType end)
{
for (vtkIdType i = begin; i < end; i++)
this->Counter.Local()++;
}
};
// Define the range size over which to operate
const vtkIdType Target = 10000;
ARangeFunctor functor;
vtkSMPTools::For(0, Target, functor);
// Iterates over the storage to calculate the accumulation.
vtkIdType total = 0;
for (const auto& el : functor.Counter)
{
total += el;
}
// total should be equal to Target
STD backend performance
You will find below some performance comparisons between OpenMP, TBB, STDThreads and Sequential SMPTools backends. The results are in milliseconds and each curve is an average of 4 executions. The tests were executed on an Intel i7-8700 (12) @ 3.20GHz, and 64Gb of RAM. Because of this setup the number of threads stay relatively low, tests with a higher number of threads could be interesting.
For these tests we used 3 different 512³ regular grid datasets with a pipeline composed of a vtkFlyingEdges3D and a vtkWindowedSincPolyDataFilter:
- The first one, “Elevation”, is a simple synthetic dataset and quite easy to process.
- The second dataset, “Enzo”, is a simulation of the universe, so a rather noisy dataset.
- The last one, “EthaneDiol”, is a molecular simulation, a smooth dataset.
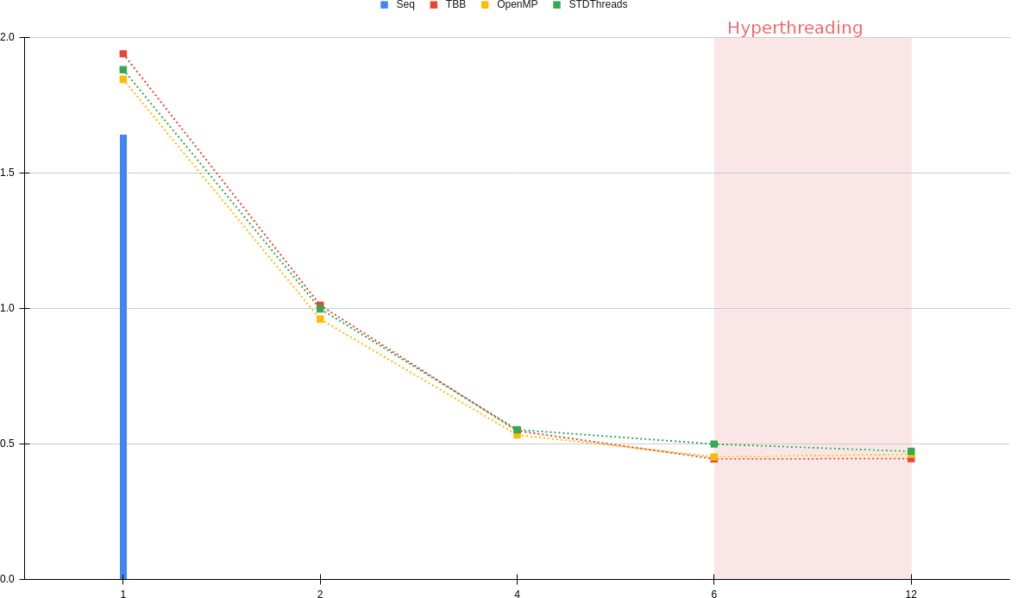
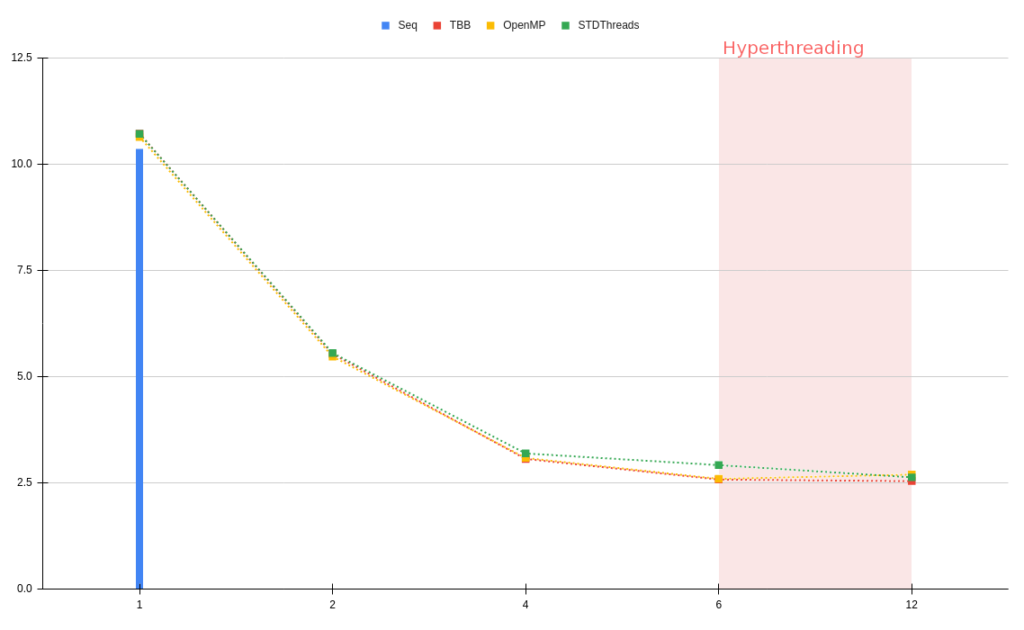
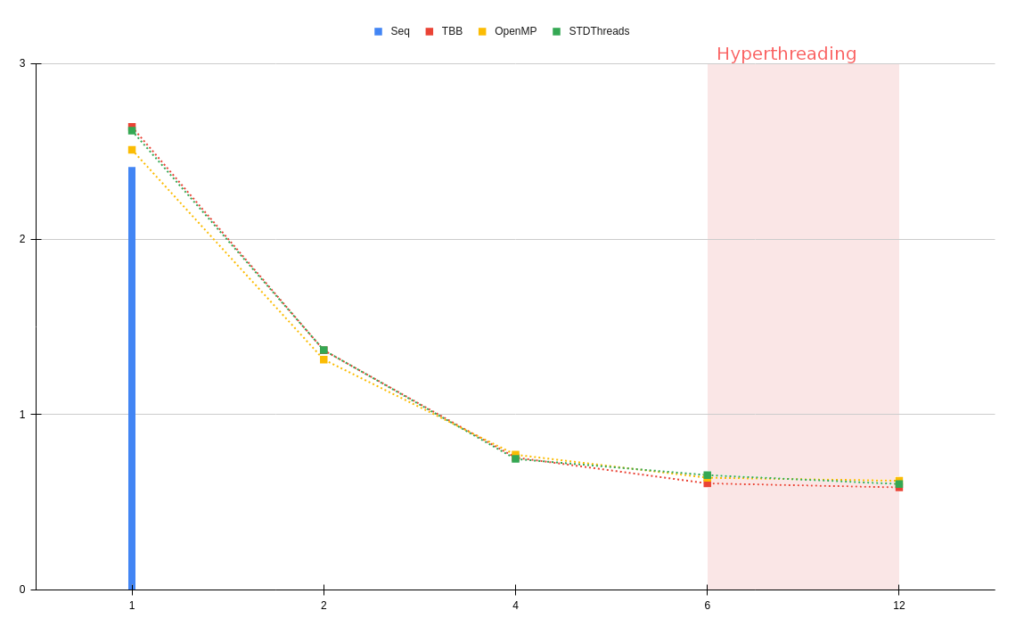
First, we can observe that each threaded backend has a small cost on initialization (compared to a sequential execution), but then, all backends behave the same. We can note that the scaling behaves well, each backend is close to the Ideal curve.
On 2 of the 3 graphs (“Elevation” & “EthaneDiol”) , STDThreads seems to have a small time lag with 6 threads compared to other backends but this delay is catched up with hyperthreads.
In order to complete this research, future tests could be done:
- with a pipeline containing more stressful parallel filters (e.g. with a lot of random memory access, on explicit meshes).
- with more threads: so we can see if the slow down shown with 6 threads for STD thread continues … or not!
Runtime backends
One of the latest features we made on SMP Tools is the ability to compile multiple backends (Sequential, TBB, STDThread, OpenMP) in the same build and select which one to use on runtime.
The VTK_SMP_IMPLEMENTATION_TYPE CMake option still sets which SMP Tools will be implemented by default. The backend can then be changed at runtime with the environment variable VTK_SMP_BACKEND_IN_USE or with SetBackend. If the backend requested is not available the previous one used will remain.
vtkSMPTools::SetBackend("OpenMP");Note that the desired backend must have the corresponding CMake advanced option VTK_SMP_ENABLE_<backend_name> set to ON to be available. Sequential and STDThread backends are activated by default.
What’s next?
VTK SMP Tools are still in evolution, stay tuned for further updates, such as a VTKm backend and the nested parallelism support
If you have any questions or suggestions please contact us on the VTK discourse (https://discourse.vtk.org/).
Acknowledgements
This work is funded by an internal innovative effort of Kitware Europe.
Documentation
Parallel Processing with VTK’s SMP Framework Documentation
Great work guys! It is great to see SMP Tools getting this much love.
Very nice!!! I just tested this using vtkGeometryFilter() on a relatively large vtkUnstructuredGrid (tetrahedral cells) and achieved an elapsed time reduction from 9.8 to 1.9 seconds on my laptop with 4 physical cores and 8 threads.
I’ve beens struggling to build vtk with TBB on WIndows with Python bindings, so it was great to find the STDThread option was already available in my vanilla download of 9.1!!!
Note that the comparative performance charts in the this blog don’t display for me….
Doug
The performance comparison benchmark images seem to be broken for me. Any chance they can be reinstated?
The performance charts were lost, I had to re-create them but here we are ! Sorry for the inconvenience.
Thanks for recreating them.
This is a wonderful blog. As far as the testing results, a few comments. 1) Is it possible to share the testing code? (or tell me where it is, it might be good to add to VTK Examples.) 2) If I understand correctly, you are testing a pipeline which consists of a series of filters. Portions of this pipeline are likely serial, which at some point will start to dominate the timing. I’d like to have a better sense of potential serial effects (source code would help see #1). 3) the datasets are small and don’t show the full effect of really large data (and again, with small data the serial portions of the pipeline processing will start dominating the timing). If possible I’d like to be able to run these on 1K^3 or 2K^3 volumes.