Data Annotation & Curation
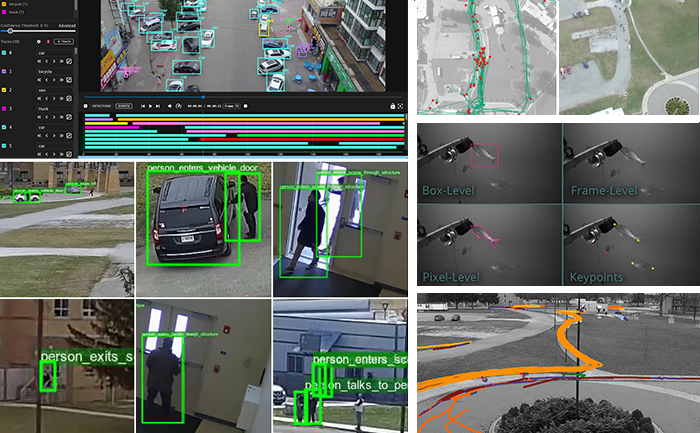
The growth in deep learning has increased the demand for quality, labeled datasets needed to train models and algorithms. The power of these models and algorithms greatly depends on the quality of the training data available. Kitware has developed and cultivated dataset collection, annotation, and curation processes to build powerful capabilities that are unbiased and accurate, and not riddled with errors or false positives. Kitware can collect and source datasets and design custom annotation pipelines. We can annotate image, video, text and other data types using our in-house, professional annotators, some of whom have security clearances, or leverage third-party annotation resources when appropriate. Kitware also performs quality assurance that is driven by rigorous metrics to highlight when returns are diminishing. All of this data is managed by Kitware for continued use to the benefit of our customers, projects, and teams. Data collected or curated by Kitware includes the MEVA activity and MEVID person re-identification datasets, the VIRAT activity dataset, and the DARPA Invisible Headlights off-road autonomous vehicle navigation dataset.
Need expert help with your project? Speak directly with one of our developers.