Advanced Computer Vision Solutions for Mission-Critical Challenges
Partner with Kitware to create cutting-edge algorithms and software for automated image, video, and text analysis. Our solutions harness the power of generative AI and machine learning to address the most challenging problems in converting data into actionable information.


Computer Vision Innovation Across Domains and Modalities
Kitware delivers advanced computer vision capabilities that address mission-critical challenges across land, sea, air, and space. We help organizations extract and fuse actionable intelligence from complex, multimodal data—including imagery, full-motion video, multispectral and hyperspectral sensors, LiDAR, metadata, and even text. Our work spans operational deployments and forward-leaning R&D efforts that advance AI/ML and computer vision using robust, affordable, and open source-based solutions. Whether you’re seeking a field-tested system or a research collaborator, Kitware provides the technical depth and domain expertise to help you succeed.





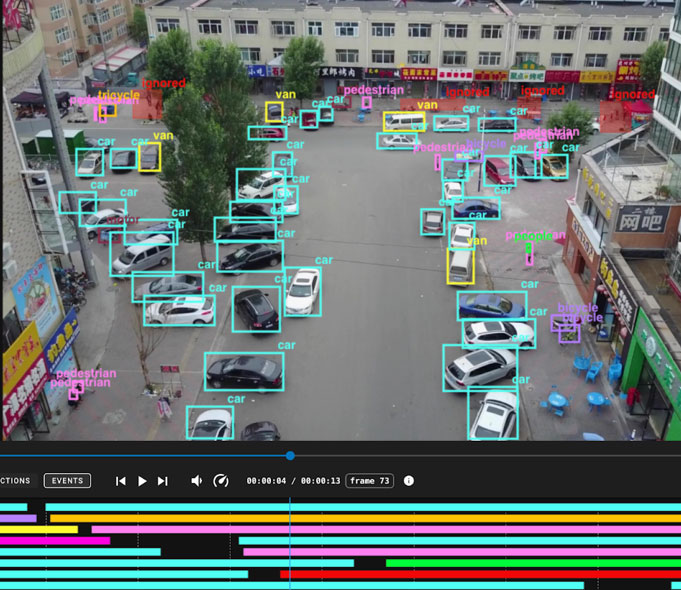
Featured Projects



Solutions We Deliver

Research and Development

Custom Software Solutions

Data Management and Annotation Solutions

Collaboration and Technical Expertise
Explore How We Work with Our Customers
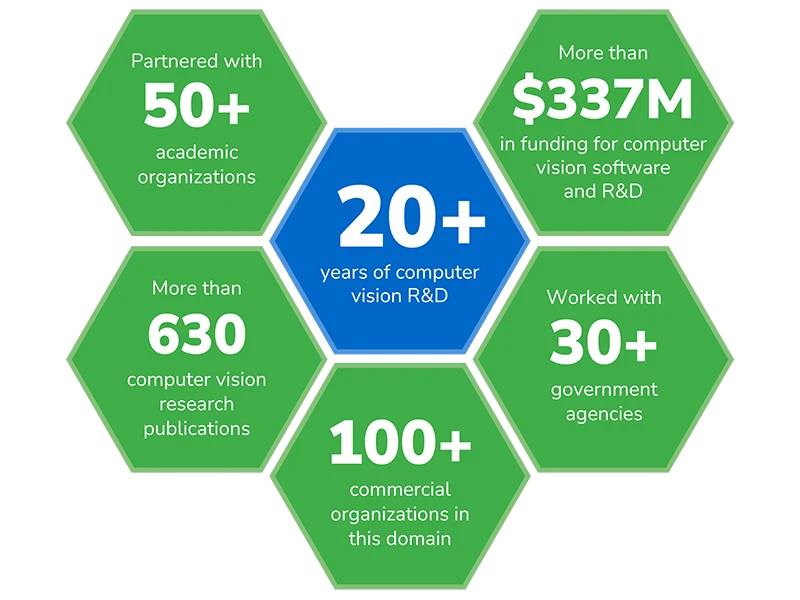
Why Kitware
Kitware is a trusted R&D partner with a 25-year track record of delivering high-impact computer vision solutions to government agencies and research institutions. We bring deep technical expertise, transparency, and long-term support to every collaboration—working as an extension of your team to design and deliver sustainable, mission-ready systems. Our open source-first approach eliminates licensing fees and promotes flexibility, while our proven software engineering practices ensure security, performance, and maintainability across environments.
Open Source Platforms for Computer Vision
Our solutions are built on proven, open source platforms trusted by the DoD and intelligence communities:

Kitware’s Video and Image Exploitation and Retrieval framework, designed for complex computer vision pipelines.

A powerful open source toolkit for video and image analytics, enabling advanced detection and classification.

The eXplainable AI Toolkit provides tools and interfaces to evaluate, visualize, and explain AI decision-making, enhancing trust and accountability in machine learning systems.
Connect with our computer vision experts to discuss your program’s needs and challenges.