
THE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR)
Hosted by the IEEE Computer Society and the Computer Vision Foundation
June 19-24, 2022 at the Ernest N. Moral Convention Center in New Orleans, Louisiana
CVPR is the largest annual computer vision event, attracting students, academics, and industry researchers from around the world. CVPR covers a wide range of topics related to computer vision and machine learning, including object detection, image segmentation, 3D reconstruction, video analysis, and deep learning. Kitware has an extensive history of participating at CVPR as a leader in the computer vision community. Our computer vision team is dedicated to finding innovative solutions to difficult data analysis and understanding problems using robust R&D techniques and Kitware’s open source platforms. We are looking forward to meeting with attendees and other exhibitors during the conference. If you are attending, be sure to visit our booth #1522 for demos and to learn more about Kitware. If you would like to schedule time with us during the conference or set up a meeting for a later date, please email our team at computervision@kitware.com.
Kitware’s Activities and Involvement at CVPR 2022
In addition to being an exhibitor, Kitware is a Silver sponsor of CVPR 2022. We are pleased to have the following five papers in the main conference and two papers in associated workshops.
Revisiting Near/Remote Sensing with Geospatial Attention
Tuesday, June 21 from 10 AM – 12:30 PM | Poster Session: Machine Learning
Authors: Scott Workman (DZYNE Technologies), M. Usman Rafique (Kitware), Hunter Blanton (University of Kentucky), Nathan Jacobs (University of Kentucky)
This work addresses the task of overhead image segmentation when auxiliary ground-level images are available. Performing joint inference over near/remote sensing can yield significant accuracy improvements. Extending this line of work, we introduce the concept of geospatial attention, a geometry-aware attention mechanism that explicitly considers the geospatial relationship between the pixels in a ground-level image and a geographic location. We propose an approach for computing geospatial attention that incorporates geometric features and the appearance of the overhead and ground-level imagery. We introduce a novel architecture for near/remote sensing that is based on geospatial attention and demonstrate its use for five segmentation tasks. The results demonstrate that our method significantly outperforms the latest methods that are currently being used.

Cascade Transformers for End-to-End Person Search
Wednesday, June 22 from 10 AM – 12:30 PM | Poster Session: Recognition: Detection, Categorization, Retrieval
Authors: Rui Yu (Pennsylvania State University), Dawei Du (Kitware), Rodney LaLonde (Kitware), Daniel Davila (Kitware), Christopher Funk (Kitware), Anthony Hoogs (Kitware), Brian Clipp (Kitware)
Localizing a target person from a gallery set of scene images can be difficult due to large-scale variations, pose/viewpoint changes, and occlusions. In this paper, we propose the Cascade Occluded Attention Transformer (COAT) for end-to-end person search. Our three-stage cascade design focuses on detecting people in the first stage, while later stages simultaneously and progressively refine the representation for person detection and re-identification. At each stage, the occluded attention transformer applies tighter intersection over union thresholds. We calculate each detection’s occluded attention to differentiate a person from other people or the background. Through comprehensive experiments, we demonstrated the benefits of our method by achieving state-of-the-art performance on two benchmark datasets.

Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks
Wednesday, June 22 from 1:30 – 3 PM | Poster Session: Motion, Tracking, Registration, Vision & X, and Theory
Authors: Peri Akiva (Rutgers University), Matthew Purri (Rutgers University), Matthew Leotta (Kitware)
Self-supervised learning aims to learn image feature representations without using manually annotated labels and is often a precursor step to obtaining initial network weights that ultimately contribute to faster convergence and superior performance of downstream tasks. While self-supervision reduces the domain gap between supervised and unsupervised learning without using labels, it still requires a strong inductive bias to downstream tasks for effective transfer learning. In this work, we present our material- and texture-based self-supervision method named MATTER (MATerial and TExture Representation Learning), which is inspired by classical material and texture methods. Material and texture can effectively describe any surface, including its tactile properties, color, and specularity. By extension, effective representation of material and texture can describe other semantic classes strongly associated with said material and texture. MATTER leverages multi-temporal, spatially aligned remote sensing imagery over unchanged regions to achieve consistency of material and texture representation. We show that our self-supervision pretraining method allows for up to 24.22% and 6.33% performance increase in unsupervised and fine-tuned setups, and up to 76% faster convergence on change detection, land cover classification, and semantic segmentation tasks.

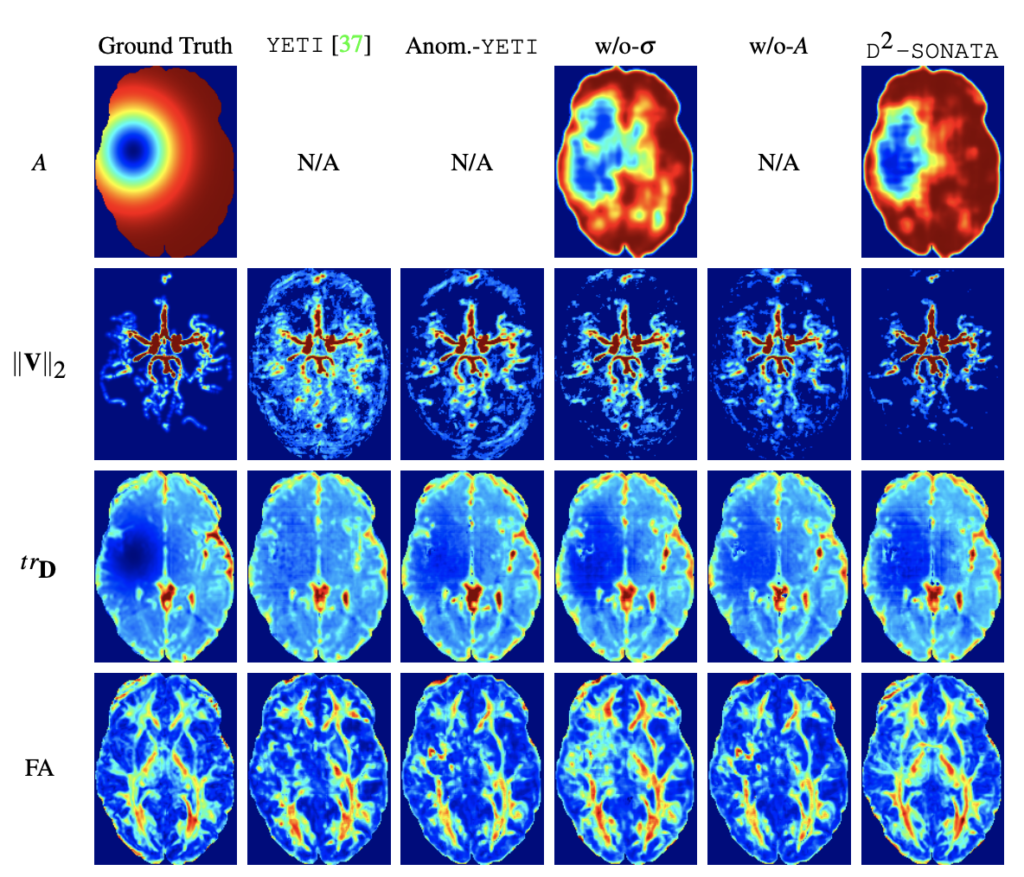
Deep Decomposition for Stochastic Normal-Abnormal Transport
Friday, June 24 from 1:30 – 3 PM | Poster Session: Biometrics, Face & Gestures, and Medical Image Analysis
Authors: Peirong Liu (Department of Computer Science, University of North Carolina at Chapel Hill), Yueh Lee (Department of Radiology, University of North Carolina at Chapel Hill), Stephen Aylward (Kitware), Marc Niethammer (Department of Computer Science, University of North Carolina at Chapel Hill)
In this paper, we discuss our development of a machine learning model built upon a stochastic advection-diffusion equation, which predicts the velocity and diffusion fields that drive 2D/3D image time-series of transport. We incorporated a model of transport atypicality, which isolates abnormal differences between expected normal transport behavior and the observed transport. In a medical context, a normal-abnormal decomposition can be used (e.g. to quantify pathologies). Our model also identifies the advection and diffusion contributions from the transport time-series and simultaneously predicts an anomaly value field to provide a decomposition into normal and abnormal advection and diffusion behavior. To achieve improved estimation performance for the velocity and diffusion-tensor fields underlying the advection-diffusion process and for the estimation of the anomaly fields, we create a 2D/3D anomaly-encoded advection-diffusion simulator, which allows for supervised learning. We further apply our model on a brain perfusion dataset from ischemic stroke patients via transfer learning. Extensive comparisons demonstrate that our model successfully distinguishes stroke lesions (abnormal) from normal brain regions, while reconstructing the underlying velocity and diffusion tensor fields.
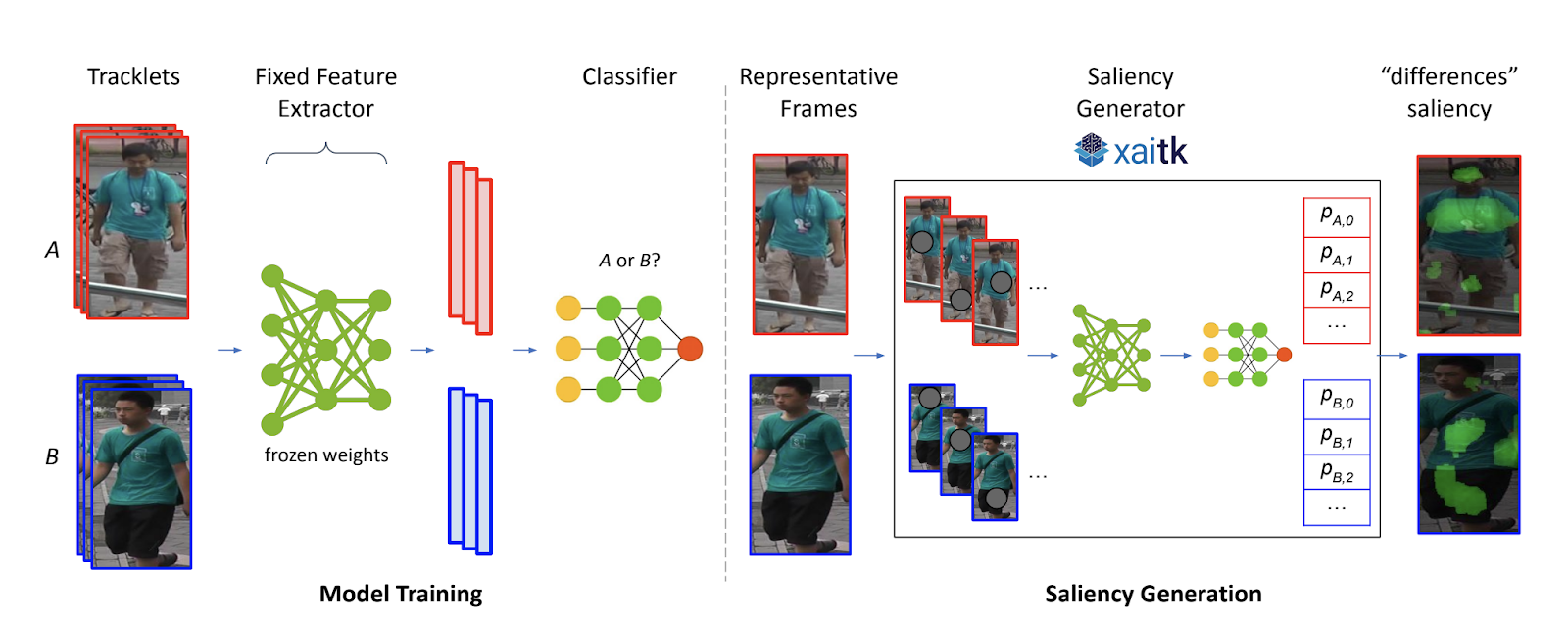
Doppelganger Saliency: Towards More Ethical Person Re-Identification
Monday, June 20, All day | Workshop Paper: Fair, Data Efficient And Trusted Computer Vision
Authors: Brandon RichardWebster (Kitware), Brian Hu (Kitware), Keith Fieldhouse (Kitware), Anthony Hoogs (Kitware)
Modern surveillance systems have become increasingly dependent on AI to provide actionable information for real-time decision-making. A critical question relates to how these systems handle difficult ethical dilemmas, such as the misidentification of similar-looking individuals. Potential misidentification can have severe negative consequences, as evidenced by recent headlines of individuals who were wrongly accused of crimes they did not commit based on false matches. A computer vision-based saliency algorithm is proposed to help identify pixel-level differences in pairs of images containing visually similar individuals, which we term “doppelgangers.” The computed saliency maps can alert human users of the presence of doppelgangers and provide important visual evidence to reduce the potential of false matches in these high-stakes situations. We show both qualitative and quantitative saliency results on doppelgangers found in a video-based person reidentification dataset (MARS) using three different state-of-the-art models. Our results suggest that this novel use of visual saliency can improve overall outcomes by helping human users and assuring the ethical and trusted operation of surveillance systems.
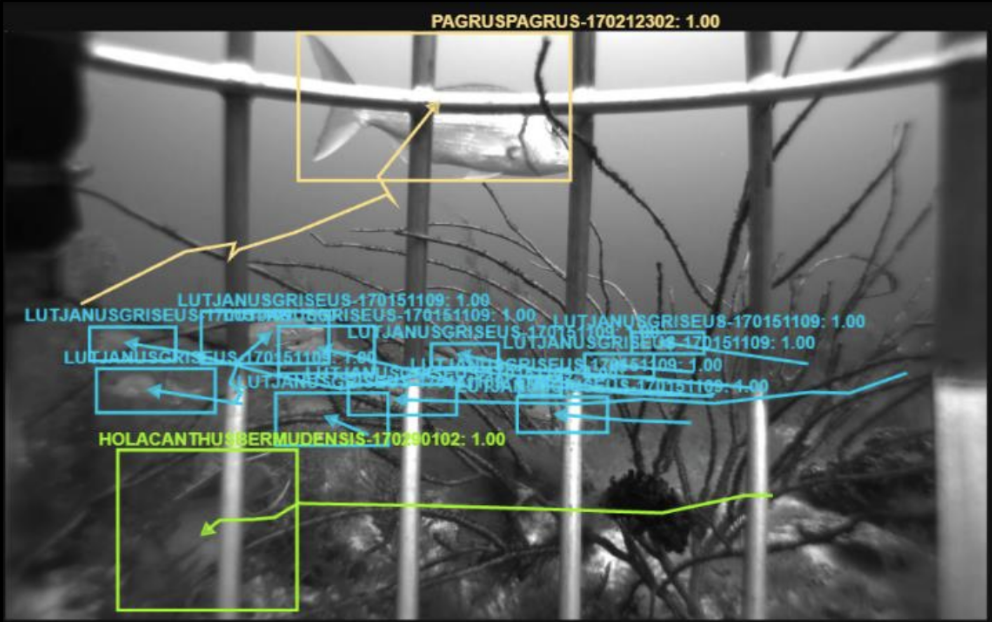
FishTrack22: An Ensemble Dataset for Automatic Tracking Evaluation
TBD | Workshop Paper
Authors: Matt Dawkins (Kitware), Matthew Lucero (California Department of Fish and Wildlife), Thompson Banez (California Department of Fish and Wildlife), Robin Faillettaz (French Research Institute for Exploitation of the Sea), Matthew Campbell (NOAA), Jack Prior (NOAA), Benjamin Richards (NOAA), Audrey Rollo (NOAA), Aashish Chaudhary (Kitware), Anthony Hoogs (Kitware), Mary Salvi (Kitware), Bryon Lewis (Kitware), Brandon Davis (Kitware), Neall Siekierski (Kitware)
Tracking fish underwater contains a number of unique challenges. The video can contain large schools comprised of many fish, dynamic natural backgrounds, variable target scales, volatile collection conditions, and non-fish moving confusors including debris, marine snow, and other organisms. There is also a lack of public datasets for algorithm evaluation available in this domain. FishTrack22 aims to address these challenges by providing a large quantity of expert-annotated fish ground truth tracks in imagery and video collected across a range of different backgrounds, locations, collection conditions, and organizations. Approximately 1M bounding boxes across 45K tracks are included in the release of the ensemble, with potential for future growth in later releases.
Kitware’s Computer Vision Work
Kitware is a leader in AI, machine learning, and computer vision. We have expertise in familiar areas, such as 3D reconstruction, complex activity detection, object detection and tracking, as well as emerging areas, such as explainable and ethical AI, interactive do-it-yourself AI, and cyber-physical systems. Kitware’s Computer Vision Team also develops robust lidar technology solutions for autonomy, driver assistance, mapping, and more. Our open source application, LidarView, performs real-time visualization and processing of live captured 3D lidar data. To learn more about Kitware’s computer vision work, you can email us at computervision@kitware.com.
Kitware is Hiring!
We deliver innovative solutions to our customers through custom software. At Kitware, you’ll apply cutting-edge R&D and the latest machine learning and AI methods to solve the world’s biggest challenges. But it doesn’t end there; Kitware invests in your career and empowers your passion. And did we mention that Kitware is 100% employee-owned? If you are interested in employment opportunities on the computer vision team, visit kitware.com/careers.
Physical Event
Ernest N. Moral Convention Center
Ernest N. Moral Convention Center
900 Convention Center Blvd, New Orleans, LA 70130
Virtual Location