Faster rendering of large number of actors in VTK with WebGPU

As introduced in our previous blog post, we have recently introduced an experimental WebGPU backend in VTK that can be compiled to the web assembly (wasm32) architecture. In this blog post, we will be providing an informal comparison between the OpenGL/WebGL backend available in VTK/vtk-js and the experimental WebGPU C++ rendering backend. The information provided here is meant to be a status update on an ongoing technical implementation. The benchmark comparisons may not always be perfectly comparable, and future performance numbers may change significantly.
When new VTK adopters want to render large CAD assemblies in VTK, their first approach is usually to create a unique actor for every part, material, region, and/or mesh. While the idea may seem reasonable, it is not the recommended approach for large-scale applications where maximizing performance is crucial. Each vtkActor incurs a small amount of processing overhead that accumulates through different stages of the rendering process. For example, it is not a recommended approach if there are a thousand or more actors.
- Every vtkActor has a transformation matrix that describes orientation, position, and scale relative to a scene. These matrices are sent to the GPU as uniform variables which does not scale very well for larger scenes due to the cumulative overhead of a single glUniformMatrix4fv function. On top of that, VTK checks if a program uses a uniform before setting the uniform. Such state queries force OpenGL drivers to finish pending operations and should ideally be used only for debugging purposes. This can easily be alleviated using Uniform Buffer Objects (UBOs) in WebGL2 or OpenGL. Switching between uniform buffer bindings is typically faster than switching dozens of uniforms in a program.
- Even after all uniforms have coalesced into a single UBO, there is yet another logical block that needs rethinking. In oversimplified terms, VTK desktop OpenGL colors individual cells with a different color by looking up a texture buffer with a cell index. The same method is used to obtain cell normals in the shader program. Whereas, in VTK WebGL2 (both vtk.js and VTK.wasm), the cell colors and cell normals are duplicated for every cell vertex, because there is no support for texture buffers and geometry shaders in WebGL2. As a result, VTK WebGL2 has more memory needs and introduces extra overhead in data transfers to the GPU.
- Even after both the above problems are solved, VTK frequently queries the driver for OpenGL state, which forces OpenGL drivers to flush all operations. Moreover, all data uploads in the current VTK OpenGL/WebGL2 rendering framework are synchronized. Both these actions quickly get expensive in browsers because the GPU process and UI thread are now interlocked with each other. This is visualized in the VTK.wasm OpenGL and the vtk.js WebGL2 performance snapshots discussed towards the end of this blog.
It is important to understand that the VTK rendering model (actors, renderers and render window) has a unique separation of responsibilities, and combining them appropriately to meet workflow demands can make significant differences in the usability of an application. Generally, creating a large number of actors is discouraged – instead, we suggest developers either use vtkCompositePolyDataMapper in C++ or append many meshes into a single mesh using the AppendPolyData filter in vtk.js and render with a single actor. For example, this is the approach adopted in 3D Slicer where VTK Widgets have been re-designed from the ground up to allow handling multiple thousands of objects.
Nonetheless, the benchmark applications described in this post follow the traditional approach with the VTK rendering model in both VTK C++ and vtk.js. These benchmarks involve rendering a large number of separate objects using different actors, therefore pushing the VTK framework to its limits in several ways. Simply processing a large number of objects carries its own overhead, as each instantiated object introduces memory and procedural overhead. In addition, each actor also has its own transform; and every mesh has separate point normals and cell colors. These are uploaded separately as vertex attributes to the GPU.
Setup
For the purposes of this benchmark comparison, we have written a simple web application that compares the different rendering backends. The application can be accessed by visiting kitware.github.io/vtk-wasm-demos and the source code is available at github.com/Kitware/vtk-wasm-demos.
Once you visit the webpage, there are a few applications listed. Click on any of them and you’ll be taken to the vtk.wasm or vtk.js application.
After you open one of the “Many Objects” applications, you’ll notice a UI panel on the top right. These options adjust various parameters like the number of cones in each direction, spacing between the cones, and animation of the camera.
Screenshot of the control panel found in each benchmarking application.
In the top left corner, you’ll find an FPS counter.
Screenshot of the FPS display found in each benchmarking application.
Benchmarks
We ran all four benchmarks on three different machines. Here are the system details.
- Linux, NVIDIA RTX A2000 Laptop GPU
- macOS, Apple Mac Mini M1
- Windows, Intel Iris Plus Graphics
At the time of writing this blog, WebGPU is fairly new so we recommend these browsers
- Linux: Google Chrome Stable 113+
- macOS: Google Chrome Stable 112+
- Windows: Microsoft Edge Stable 113+ or Google Chrome Stable 112+
Special instructions for Linux
Please note that at the time of writing the blog, the Vulkan GPU interop for Google Chrome on Linux is a work in progress (crbug/1411745), so it may not work on your machine. As a workaround, resort to software-accelerated Vulkan with this command:
google-chrome-stable --enable-unsafe-webgpu --enable-features=Vulkan,VulkanFromANGLE --use-angle=swiftshader
The implementation differences between the WebGPU backends of vtk.wasm and vtk.js are responsible for the differences in performance. Both backends have different approaches for uploading vertex data and rendering actors. In VTK.wasm, the shader programs pull vertex attributes through Shader Storage Buffer Objects (SSBOs) and WebGPU asynchronously uploads the geometry data into those SSBOs. The transformation matrices of all actors are combined and uploaded in a single Uniform Buffer Object (UBO). The actors encode draw commands into a render bundle instead of individual render commands. All the buffer uploads and render bundle executions are managed asynchronously by WebGPU upon submission of work to the command queue. We anticipate that if the vtk.js-WebGPU implementation was updated to use SSBOs, it would achieve framerates similar to those of VTK.wasm-WebGPU.
We could not implement all of these techniques in VTK OpenGL and benefit from those enhancements on web platforms because WebGL2.0 does not support SSBOs, command buffers, and simple asynchronous data management. Indeed, Desktop OpenGL has supported SSBOs since version 4.3. However, WebGL2 is a subset of the OpenGL ES 3.0 specification with a limited feature set. The W3C group planned support for compute shaders and SSBOs in WebGL-next, which was succeeded by WebGPU.

This figure shows a performance snapshot of a single frame with the WebGPU C++ implementation in VTK. The overall time taken to render a single frame is only 1.79ms. We still have a long way to go in optimizing the C++ WebGPU backend. Frustum coverage cullers and bounding box computations could be offloaded into asynchronous compute pipelines on a GPU.
In contrast, the C++ OpenGL implementation in VTK frequently queries the OpenGL state and flushes the OpenGL rendering pipeline, which stalls the GPU process. As a result, the main browser thread and the GPU process execute in lockstep, which is detrimental to performance.
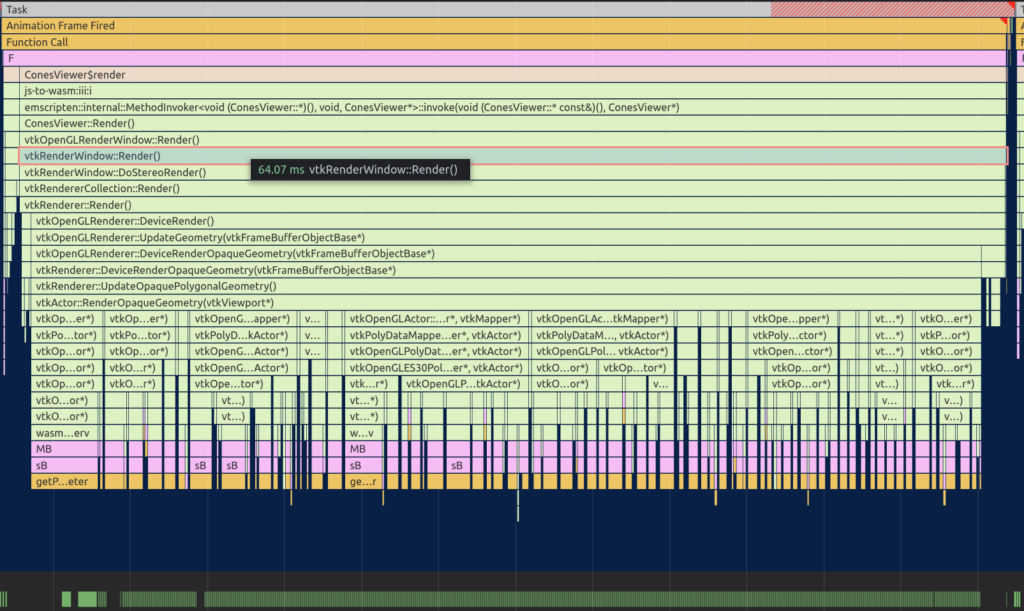
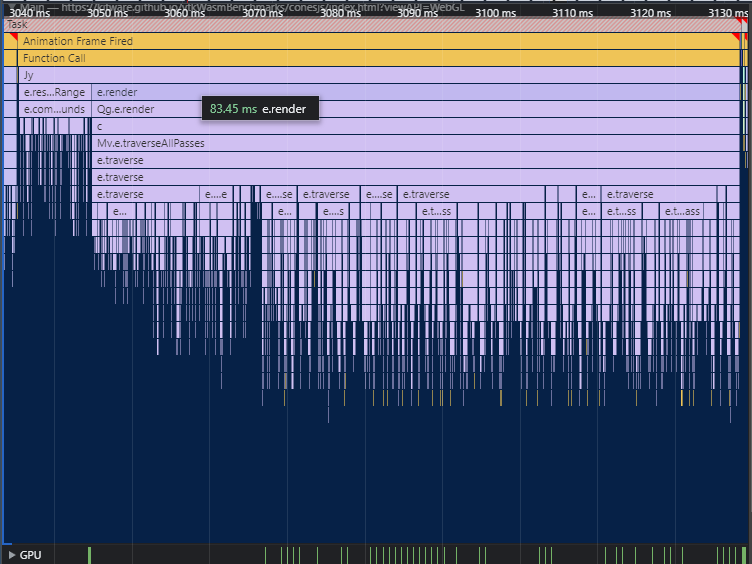
In vtk.js, using the webgl2 implementation for 1000 actors, the application appears to be CPU bound – more time is spent executing javascript code to figure out rendering requirements than actually rendering the datasets. In this flamegraph, notice the duration of purple blocks against the green blocks in the GPU timeline.
Conclusion
At this early point in the project, our WebGPU C++ implementation in VTK performs very well compared to our OpenGL implementations in VTK C++ and vtk.js. Moreover, even with an integrated graphics card on Windows, the WebGPU backend is able to keep up with a large number of meshes. While the comparisons between OpenGL and WebGPU are not apples-to-apples, it is clear that early implementations are looking good. We are encouraged by the results and are enthusiastically pushing forward the implementation. If you’re interested in collaborating with Kitware, whether it’s for support or the implementation of new features in VTK, we invite you to contact us or visit our commercial projects webpage.
Future work
The VTK C++ WebGPU shader inputs have partial correspondence with the VTK data model. Currently, geometry primitives (triangles, line segments, and points) are generated from the VTK connectivity and offset arrays outside the shaders in C++, making it CPU-bound. This incurs additional costs for dynamic rendering, typical in post-processing visualizations. We plan to align the shader inputs completely with the VTK data model by offloading the primitive generation and frustum cullers into asynchronous GPU compute pipelines. Additionally, there are memory constraints on WebAssembly and JavaScript applications when they are run in select browsers, and we are exploring the interplay between those memory constraints and what can be achieved using WebGPU and dedicated GPU memory.
Partnering with Kitware
Kitware is dedicated to advancing cutting-edge scientific computing and visualization technologies. Our team is composed of computer scientists, software engineers, and scientific computing experts. They have the knowledge and expertise to support your pursuit of visualizing large-scale scientific and engineering datasets on a variety of platforms. Whether you’re a research center, university, or commercial company, partnering with Kitware will ensure you effectively leverage this technology.
Please write more of these, they’re really insightful and exciting. Congrats and can’t wait to see this work converge as VTK transitions to a highly performant state-of-the-art rendering backend.
Absolutely insightful, this is what real engineering decision makers are looking for. Keep it up.