Accelerating ITK Filters with Halide
ITK is a powerful and versatile library widely used for developing applications that process scientific and medical images. However, as datasets grow larger and algorithms become more complex, developers are constantly looking for new ways to optimize performance. This is where Halide, a high-performance image processing language, comes into play. By leveraging Halide’s unique approach to optimizing image pipelines, we can significantly enhance the performance of ITK operations, making workflows faster and more scalable.
Halide
Halide is a programming language designed for high-performance image and tensor processing tasks, targeting a variety of hardware from multi-threaded and SIMD CPU instructions to GPU platforms like CUDA, Vulkan, and Apple Metal. Halide separates algorithm definitions from execution schedules, allowing the programmer to quickly iterate and optimize performance with guaranteed algorithm correctness.
Halide provides two modes of operation: Just-in-time compilation (JIT) bundles Halide into the application to allow optimizing tasks for whichever hardware is available in the end user’s machine, at the cost of JIT overhead during application startup to determine these optimizations. Ahead-of-time compilation (AOT) only uses Halide while building the application, and allows tuning the algorithm for the expected platform and data without overhead.
To avoid JIT overhead and reduce the library size, we use AOT mode for the following benchmark.
Gaussian Smoothing
In this blog post, we will demonstrate how integrating Halide with ITK can lead to substantial improvements in processing speed, enabling developers and researchers to handle more data and run complex algorithms in less time without sacrificing quality.
In particular, we will examine the gaussian smoothing on 3D medical images: a common denoising task for ITK pipelines. ITK provides this functionality in the filter itk::DiscreteGaussianImageFilter, and already provides a GPU-accelerated implementation itk::GPUDiscreteGaussianImageFilter. There is an alternative implementation itk::RecursiveGaussianImageFilter which uses a fundamentally different algorithm for the same effect. We validate our Halide implementation against these implementations to ensure drop-in compatibility without loss of accuracy.
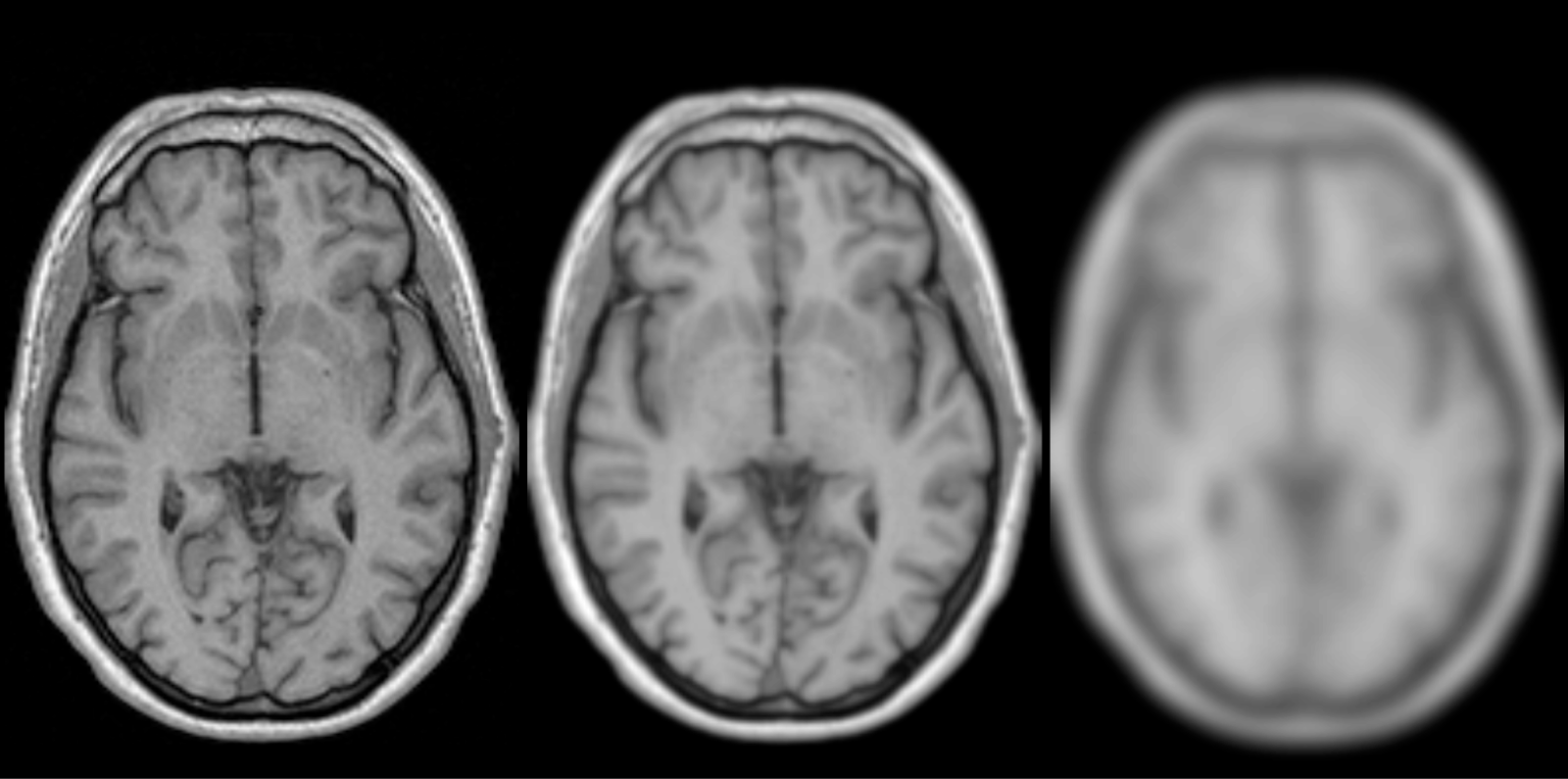
The new Halide-accelerated filters itk::HalideDiscreteGaussianImageFilter and itk::HalideGPUDiscreteGaussianImageFilter are available in the ITKHalideFilters remote module.
Results
The processing speed of the discrete gaussian filters depends only on the kernel radius (the strength of the blurring effect). In denoinsing contexts, the radius is typically kept small. In this domain of small radius, the new Halide CPU schedule handily outperforms all other implementations tested. To benchmark this, we show the processing speed for each implementation as kernel radius increases from left to right.
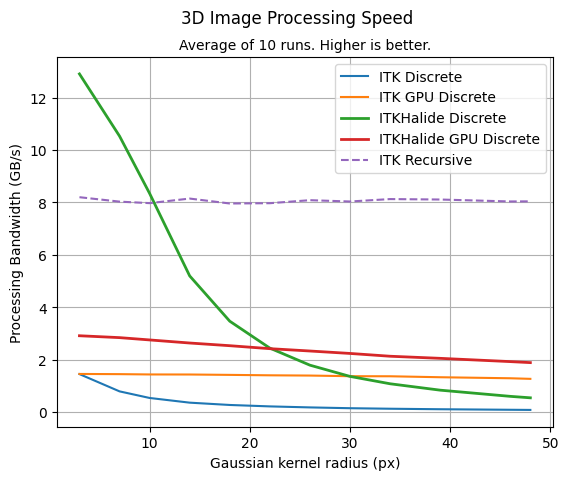
Processing speed is computed by timing each filter on a 500x500x500 pixel floating-point grayscale image. The CPU implementations run on an Intel i9-14900k, and GPU implementations run on an Nvidia RTX 4090.
The four discrete implementations fundamentally use the same algorithm, and the time required to process a given pixel is determined by the kernel radius. Halide enables massive speed-up with SIMD instructions for this task. At kernel size 10, the Halide CPU schedule outperforms the ITK Discrete implementation by 15x!
The recursive implementation is algorithmically different; its processing speed is independent of the radius, so it performs best in the domain of very large kernel sizes. However, in the much more common case of a small kernel, the Halide CPU schedule outperforms even the recursive implementation by up to 50% at kernel radius 3.
There is a trade-off for GPU acceleration: processing speed is limited by data transmission and slower clock speed on the GPU. A given platform has some break-even point where the massive parallelism in the GPU outweighs these costs. On the platform used for this benchmark, the Halide CPU schedule outperforms the GPU schedule up to kernel radius 22, and outperforms the ITK GPU implementation all the way to kernel radius 30! Past this point, the Halide GPU schedule outperforms the ITK GPU implementation by about 50%.
Key Insights
Halide enables development of drop-in replacement filters, accelerating complex ITK pipelines on both CPU and GPU. We can optimize resource usage by leveraging domain and platform knowledge. In some cases, Halide can help achieve this on CPU alone, eliminating the need for GPU altogether. Otherwise, Halide can help enable GPU acceleration that outperforms algorithmically similar alternatives.
In this demonstration, we used a filter with several existing implementations as a reference point. However, many pipelines lack such preexisting GPU implementations or alternative algorithms. For these, Halide offers a streamlined path to GPU and SIMD acceleration.
Future Work
In this preliminary work, our focus was solely on optimizing processing speed for a single task. Future efforts could extend to other performance metrics, such as memory usage or platform cost reduction. For instance, reducing GPU usage may help lower cloud infrastructure costs.
This benchmark was also limited to a single platform: Intel with Nvidia. Examining other hardware vendors could enable Halide schedules tailored to specific platforms. For example, Apple Silicon’s unified memory architecture offers potential benefits for GPU acceleration, while AMD processors provide unique multithreading and SIMD capabilities.