Understanding AI with Saliency Maps

Research in artificial intelligence has seen significant progress over the past few years, spurring the increasing adoption of AI models in many real-world applications. Despite the success of these AI models, their “black box” nature and lack of interpretability present a serious barrier to users, especially in domains with critical, high-stakes decisions such as healthcare, criminal justice, and autonomous driving.
Making AI “Explainable”
Kitware was thrilled to be involved in DARPA’s Explainable Artificial Intelligence (XAI) program and led the creation of the resulting Explainable AI Toolkit (XAITK). The XAITK contains a variety of tools and resources that help users, developers, and researchers understand complex AI models. As a result, the XAITK has the potential to help human users better understand, appropriately trust, and effectively manage AI models. As part of this effort, we developed an open source python package within XAITK called xaitk-saliency. This package provides a modular and extensible framework for invoking a class of XAI algorithms known as saliency maps. Saliency maps are heat maps that highlight features in the input to an AI model that were significant in the AI model’s output predictions. Figure 1 shows an AI model pipeline, where xaitk-saliency algorithms can provide a form of XAI, and Figure 2 shows example saliency maps.
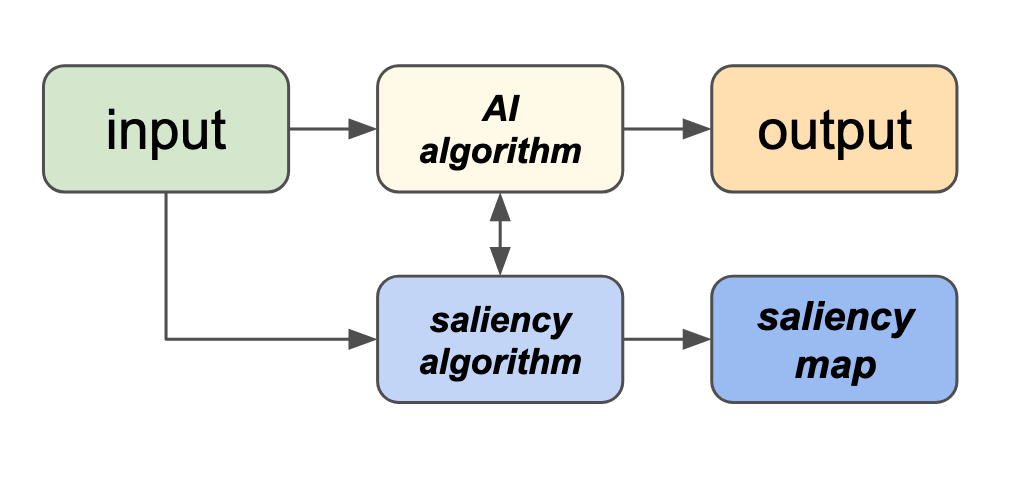
Figure 1: An AI model pipeline typically involves an algorithm that transforms input data into output predictions. When augmented with a saliency algorithm, a visual explanation in the form of a saliency map is also produced, which can provide a user additional insight into how the algorithm generated its output.

Figure 2: Example saliency maps for comparing object detection models. We computed object-specific saliency maps for two different models trained on the VisDrone aerial dataset (Zhu et al. 2021a). The TPH-YOLOv5 model (Zhu et al. 2021b) is shown in the top row and the CenterNet model (Zhou et al. 2019) is shown in the bottom row. (A) Both models produce similar high-confidence detections (shown with red bounding boxes). (B) Despite having similar detections, the saliency maps corresponding to these detections reveal subtle differences in the input features used by the two models, e.g. TPH-YOLOv5 (top) focuses on the head and feet of pedestrians, while CenterNet (bottom) focuses on the torso.
Kitware Wins Honorable Mention Award for the xaitk-saliency package
Pytorch’s Annual Hackathon 2021
Seeing is Believing: How Saliency Maps Work
Saliency maps are a form of visual explanation that indicate which input features were used by an AI model to generate its output decisions. While visual saliency maps do not provide a complete explanation of an AI model, they can provide insight into whether the model was considering something that semantically aligns, or does not align, with our human precepts for the task at hand. This may lead to indications that a model has not been trained sufficiently, has been subject to data poisoning (a form of back-door attack), or has learned to consider a spurious feature of the input that subject matter experts would not consider semantically related to the model’s output.
By observing saliency maps, we can characterize that model’s prediction behavior to understand how different conditions affect the model’s performance. Such characterization is crucial when there is intent to deploy models into critical operations or when comparing multiple models along dimensions other than simple performance.
Explainable AI as a Step Towards Ethical AI
If you are looking to take steps towards adopting more ethical AI practices, an easy way to achieve this is to start using explainable AI methodologies. For example, saliency maps can be applied to the U.S. Department of Defense’s Ethical AI Principles of being equitable and reliable. Saliency maps enable feedback in applications through explainability to minimize unintended bias (equitable) and establish an understanding of when an AI system can be trusted (reliable).
You can apply this technology to real-world scenarios, such as distinguishing between visually similar individuals in a person re-identification setting (see our CVPR ‘22 workshop paper). In our work, we used xaitk-saliency to compute saliency maps that can help users identify subtle visual differences between people, reducing the potential of false matches. With modern surveillance systems becoming increasingly dependent on artificial intelligence, it’s critical that these systems are equipped to handle difficult ethical dilemmas.
How to Incorporate Saliency Maps into Your AI Algorithms
xaitk-saliency is open source and is a valuable tool for data scientists, application developers, and integration engineers. The current saliency map algorithms cover multiple image understanding tasks, including image classification, object detection, and image retrieval. Visit the website to download the toolkit and access helpful resources. You can also contact our AI team for professional support to ensure you’re using the toolkit effectively and to help integrate it into your existing technologies. Explainability is a critical component of our ongoing ethical AI work, so Kitware has the resources and knowledge to help you pursue the ethical and responsible development of AI. Contact us for more information.
This material is based upon work supported by the United States Air Force and DARPA under Cooperative Agreement number FA875021C0130. The views, opinions, and/or findings expressed are those of the author(s) and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.