Deploying detection models on the edge for Marine Beacon
This blog describes the workflow in which Kitware is involved in the European project Marine Beacon and the tools developed for the consortium of researchers to deploy embedded AI models for active fishery monitoring, aiming to reduce bycatch.
It will go through the web platform, enabling the upload and sharing of annotated data and models between the partners, as well as the steps to deploy the trained models on the embedded platform for live monitoring during fishery operations.
Real-time AI monitoring of fisheries bycatch
Fishery bycatch, the incidental capture of non-target species, is one of the most significant challenges facing marine conservation and sustainable fishing today. While industrial fishing targets specific high-value species, the reality of the ocean is that many creatures share the same habitat, leading to unintended and often devastating consequences.
To reduce the impact of bycatch on the decline of marine biodiversity, the Marine Beacon project funded by the European Union (🇪🇺 HORIZON-CL6-2023-BIODIV-01-1) aims to produce the knowledge and tools to effectively reduce subsequent mortality of Endangered, Threatened and Protected species (ETPs) within European waters and beyond. To that end, the project is split into 9 work packages, and Kitware is part of WP5 aiming at developing next-generation monitoring of PETS bycatch using AI and molecular approaches. More details on each of them here.
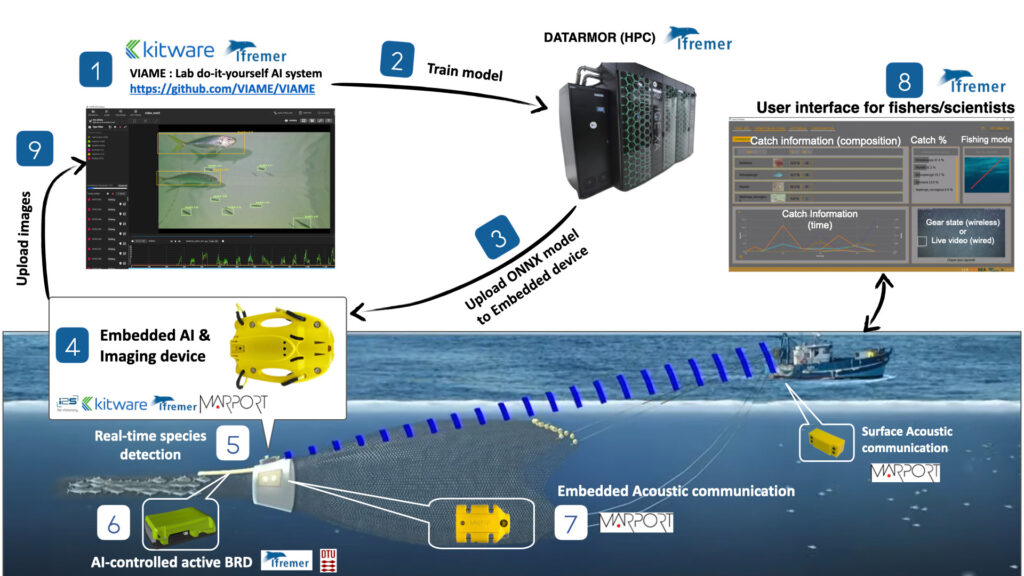
This post explores our recent developments in this collaborative project led by Ifremer, alongside Marport and I2S. We will describe the workflow that has been developed to enable model training on common datasets and model transfer to an embedded platform for live inference during fishing operations.
Next generation monitoring of PETS bycatch through AI approaches
In this work package, one of the main goals is to develop a prototype hardware for underwater monitoring using AI and imagery, along with the toolchain required for the creation of custom AI models to deploy on that hardware.
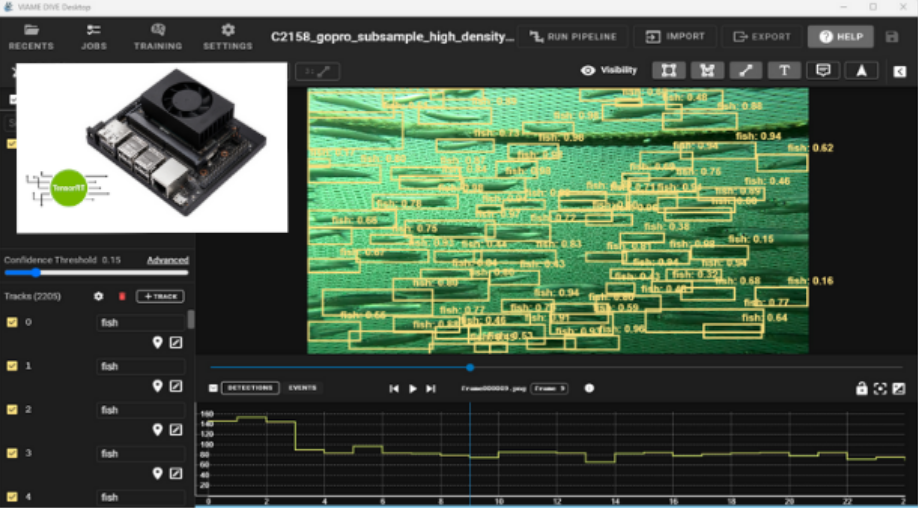
The Marine Beacon project is divided into several tasks, and our focus was on monitoring PETS bycatches using AI detection models. To this end, an underwater camera was built by the partners of the project (Figure 2) powered by an NVIDIA jetson NX board, on which we deployed a computer vision pipeline to detect underwater species on the embedded device.
Real-time object detection literature review
Object detection is a core computer vision task that involves localizing and categorizing objects within a data source, in this instance, an underwater camera. Almost all state-of-the-art detectors follow a three-part architecture:
- The Backbone: A deep neural network that extracts features (edges, textures, shapes) from the raw pixels.
- The Neck: That combines features from different scales. It is crucial for detecting both a giant whale and a tiny shrimp in the same frame.
- The Head: Spits out the final bounding box coordinates and the probability scores for each class.
Most of the attention was on improving feature extraction or the backbone architecture for these models. For over a decade, Convolutional Neural Networks [1, 7] served as the industry standard for image analysis. However, Vision Transformers [2] shifted the paradigm by capturing global context, i.e., understanding how distant pixels relate to one another, albeit at a high computational cost. This efficiency gap was finally bridged by recent innovations such as RF-DETR [3], which uses neural architecture search to bring Transformer-level precision to real-time applications. While Transformers have pushed the boundaries of global context, the YOLO (You Only Look Once) architecture [4, 5] family remains the gold standard for balancing accuracy with the extreme low-latency requirements of maritime edge devices. YOLOv9, in particular, offers compelling advantages through its Programmable Gradient Information: an auxiliary supervision branch used during training to combat information loss.
For more insight into the advancements in deep learning for object detection (one/two stage, anchor-free, multi-resolution, context and attention), we refer readers to the Zou et al. survey [6].
Model development
For our implementation, we utilized the VIAME framework to train both YOLOv4 [4] (yolov4-csp-s-mish architecture) and YOLOv9 [5] (v9-s architecture) models, all pre-trained on COCO [9] and fine-tuned with a fixed net shape input of 640×640, a batch size of 32, and for 100 epochs. Mosaicing data augmentation [4] was used during training to increase the dataset size, which consists of approximately 45K annotated images [8].
Model deployment and real-time inference
To facilitate edge deployment, we utilized the ONNX (Open Neural Network Exchange) interoperable format. While ONNX supports diverse hardware backends (e.g., Intel OpenVino, Mac MPS), we optimized specifically for NVIDIA TensorRT to leverage the integrated Volta GPU on our Jetson Xavier NX board (Figure 4).
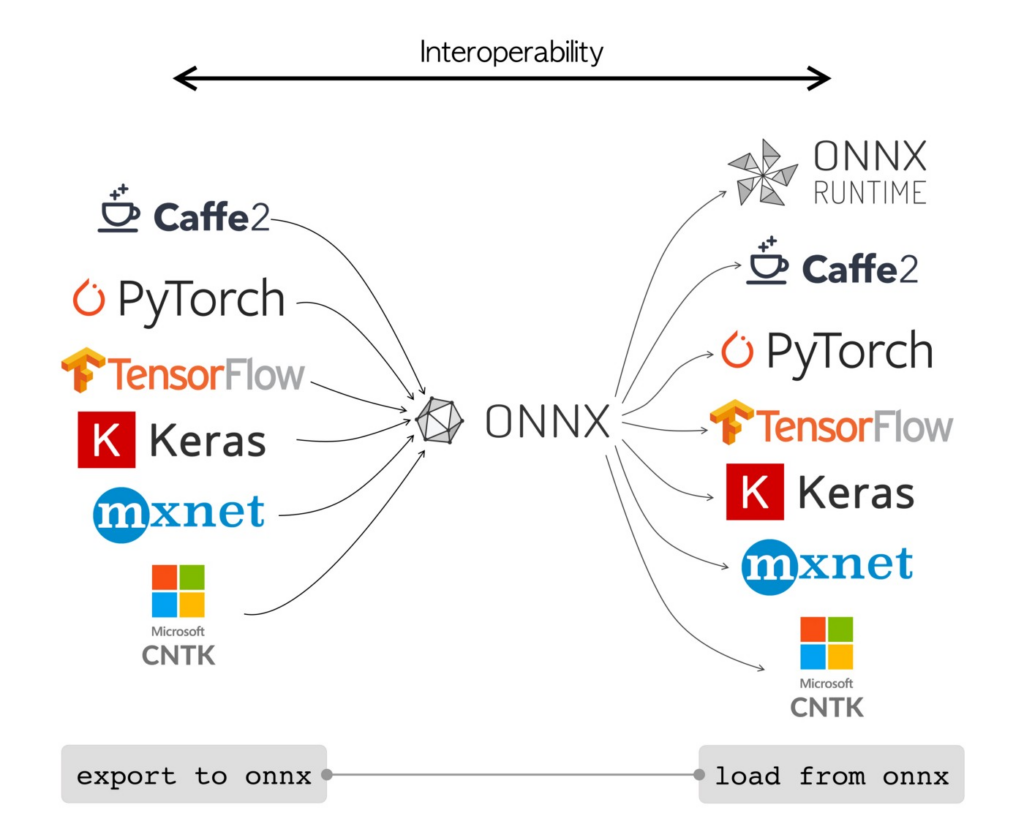

We integrated several ONNX exporters into VIAME to support various YOLO software backends, including Darknet and YOLO-mit. Our export pipeline follows a four-step process:
1. Load the architecture from a configuration file
2. Convert it to a PyTorch model
3. Export via the native PyTorch ONNX utility
4. (Optionally) Validate inference using the onnxruntime Python API.
For real-time production use, we developed a custom C++ computer vision pipeline that loads directly with the VIAME-exported ONNX files. To maximize hardware efficiency, all pre and post-processing functions are executed via OpenCV-CUDA. The Jetson’s unified memory enables a seamless transition between CPU and GPU memory spaces, significantly reducing memory overhead.
Built on the open source TensorRT C++ API library, the software features dynamic and YAML-configurable processing functions (including bounding box parsing) to help future model integrations.
This allows for a seamless deployment of a model trained in VIAME to an embedded edge device.
Results
VIAME-DIVE instance
DIVE is a free and open source annotation and analysis platform for web and desktop built by Kitware, allowing users to share datasets with others.
An instance of the platform has been deployed on IFREMER’s HPC (Datarmor) to host and share FAIR annotated images of species from various data collection campaigns to promote the exchange of such data (i.e., the core data currently limiting the detection of PETS) among Marine Beacon stakeholders.
In order to foster the sharing, we have put in place a system that allows users to preview the shareable data from other users and ask to have access to the data, in exchange for other datasets shared in the opposite direction. To that end, a custom version of DIVE has been developed. Most notably, a data exchange mechanism has been implemented, allowing users to mark some of their data as “available to exchange”. Other users can then see a preview of the “exchangeable” data and then request an exchange.
Here’s a demonstration of that principle:
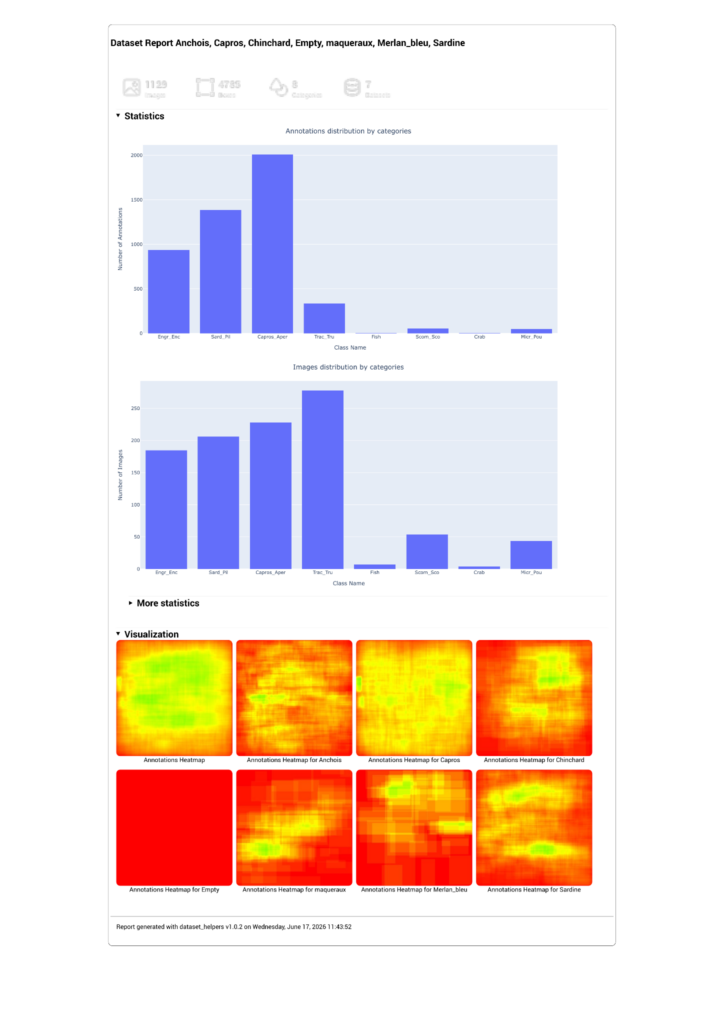
This instance of DIVE can also generate automatic annotation reports on annotated datasets/inference results. These reports (Figure 6) allow users to quickly get an overview of the classes present in the annotations as well as a rough idea of the positioning of the annotations in them over the dataset through a heatmap.
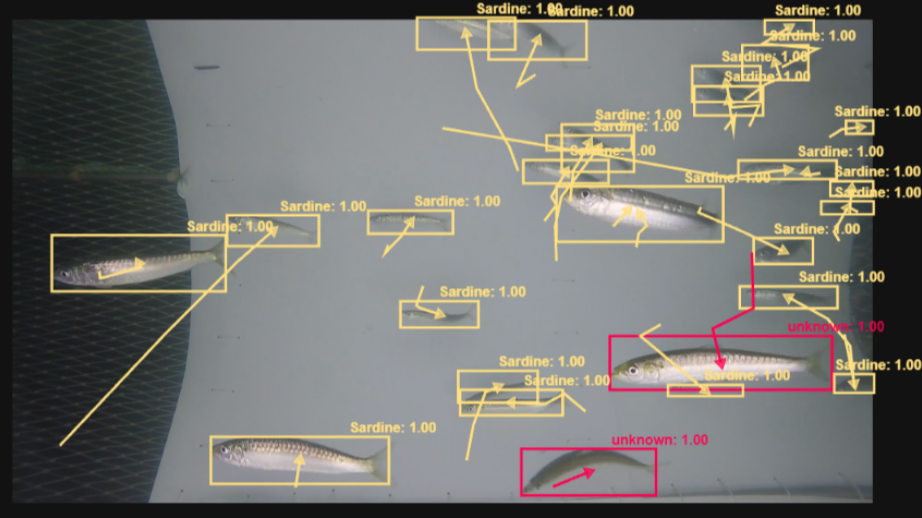
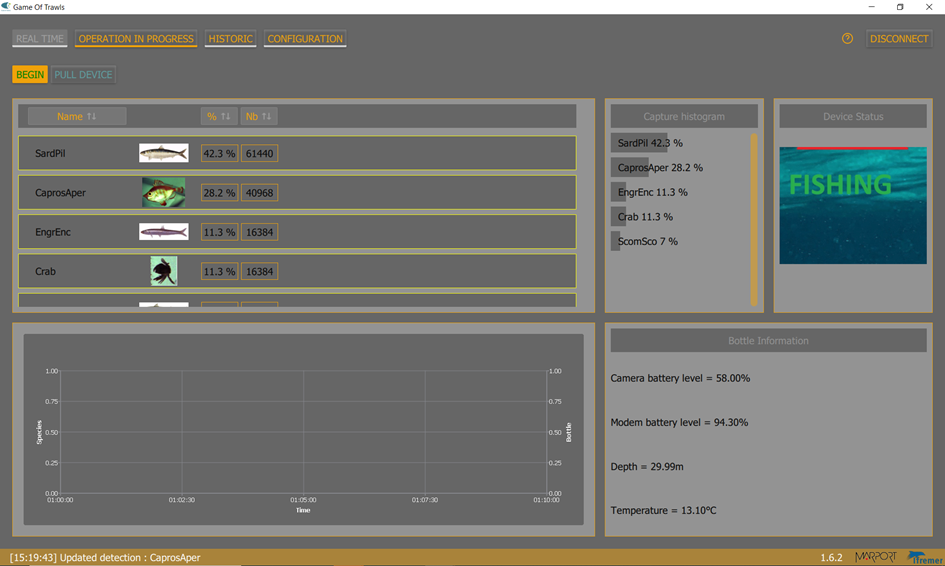
YOLOv9 inference
Video data was captured during a scientific campaign at sea in 2025 in the Bay of Biscay, near Lorient (France). Below is a sample video with predictions for multiple fish species, such as anchovies (class ‘EngEnc’) and boar-fish (class ‘CaprosAper’). We achieved real-time detection on the embedded module.
Games Of Trawls UI
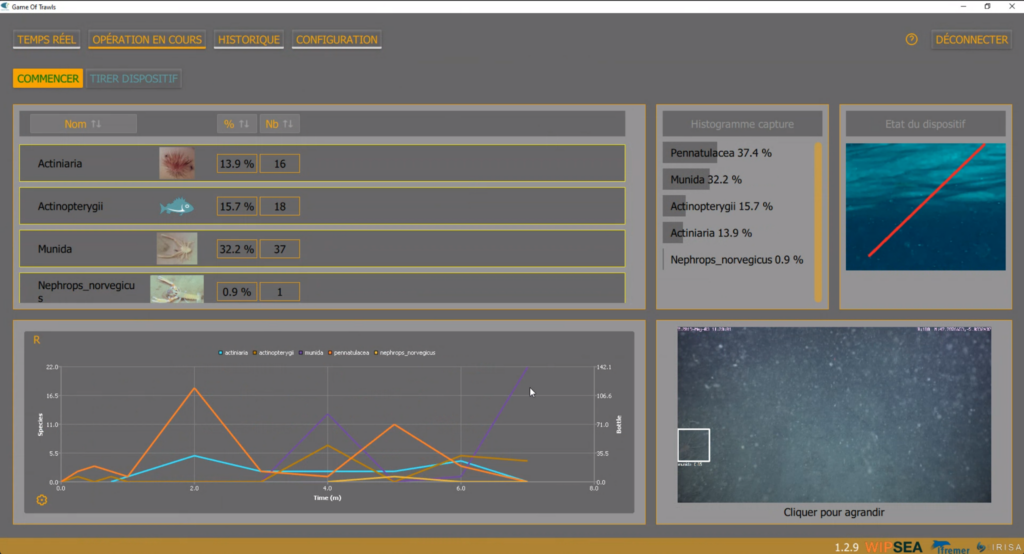
The detections are served to the Games Of Trawls server and UI (initially developed by Wipsea for Ifremer, and extended by all cited partners), which allows for interaction with the net opening control, video streaming, and other camera controls (Figure 7).
Contact
Are you interested in deploying your own deep learning models to the edge or host such a platform on your end?
Contact us if you have an application in mind that we could help you build!
Check also our other topics: the applications of DIVE:
Acknowledgments
We would like to extend our gratitude to Ifremer for their overall commitment to Open Science. We also want to give a special shout-out to the author of the original TensorRT C++ API library cyrusbehr, whose work accelerated our development process.
This work was funded by the Marine Beacon European project, as part of the Horizon 2030 program, and co-developed by Ifremer, I2S, and Marport.





References
[1] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012).
[2] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[3] Robinson, Isaac, et al. “RF-DETR: neural architecture search for real-time detection transformers.” arXiv preprint arXiv:2511.09554 (2025).
[4] Bochkovskiy, Alexey, Chien-Yao Wang, and Hong-Yuan Mark Liao. “Yolov4: Optimal speed and accuracy of object detection.” arXiv preprint arXiv:2004.10934 (2020).
[5] Wang, Chien-Yao, I-Hau Yeh, and Hong-Yuan Mark Liao. “Yolov9: Learning what you want to learn using programmable gradient information.” European conference on computer vision. Cham: Springer Nature Switzerland, 2024.
[6] Zou, Zhengxia, et al. “Object detection in 20 years: A survey.” Proceedings of the IEEE 111.3 (2023): 257-276.
[7] Howard, Andrew, et al. “Searching for mobilenetv3.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
[8] Dawkins, Matthew, et al. “Fishtrack23: An ensemble underwater dataset for multi-object tracking.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.
[9] Lin, Tsung-Yi, et al. “Microsoft coco: Common objects in context.” European conference on computer vision. Cham: Springer International Publishing, 2014.