Experts in Computer Vision, Deep Learning, and AI
CVPR is the largest computer vision event, attracting students, academics, and industry researchers from around the world. Kitware has an extensive history of participating at CVPR as a leader in the computer vision community. Our computer vision team is dedicated to finding innovative solutions to difficult data analysis and understanding problems using robust R&D techniques and Kitware’s open source platforms.
We look forward to meeting with attendees and other exhibitors during the conference. If you are attending, be sure to visit our booth #1522 for demos and to learn more about Kitware. In addition to being an exhibitor, Kitware is a Silver sponsor of CVPR 2022. We are pleased to have four papers in the main conference and two papers in associated workshops.
Have a challenging project? We can help!
Events
Revisiting Near/Remote Sensing with Geospatial Attention
Authors: Scott Workman (DZYNE Technologies), M. Usman Rafique (Kitware), Hunter Blanton (University of Kentucky), Nathan Jacobs (University of Kentucky)

We introduce a novel neural network architecture that uses geospatial attention in the setting of near/remote sensing. Our approach operates on an overhead image and a set of nearby ground-level panoramas, enabling optimal feature extraction for a query location (square) from each ground-level image (circle) in a manner that is “geometry-aware.”
Poster Session: Machine Learning
This work addresses the task of overhead image segmentation when auxiliary ground-level images are available. Performing joint inference over near/remote sensing can yield significant accuracy improvements. Extending this line of work, we introduce the concept of geospatial attention, a geometry-aware attention mechanism that explicitly considers the geospatial relationship between the pixels in a ground-level image and a geographic location. We propose an approach for computing geospatial attention that incorporates geometric features and the appearance of the overhead and ground-level imagery. We introduce a novel architecture for near/remote sensing that is based on geospatial attention and demonstrate its use for five segmentation tasks. The results demonstrate that our method significantly outperforms the latest methods that are currently being used. [Link to Paper]
Cascade Transformers for End-to-End Person Search
Authors: Rui Yu (Pennsylvania State University), Dawei Du (Kitware), Rodney LaLonde (Kitware), Daniel Davila (Kitware), Christopher Funk (Kitware), Anthony Hoogs (Kitware), Brian Clipp (Kitware)

Main challenges of person search, e.g., scale variations, pose/viewpoint change, and occlusion. The boxes with the same color represent the same ID. For better viewing, we highlight the small-scale individuals at bottom-right corners.
Poster Session: Recognition: Detection, Categorization, Retrieval
Localizing a target person from a gallery set of scene images can be difficult due to large scale variations, pose/viewpoint changes, and occlusions. In this paper, we propose the Cascade Occluded Attention Transformer (COAT) for end-to-end person search. Our three-stage cascade design focuses on detecting people in the first stage, while later stages simultaneously and progressively refine the representation for person detection and re-identification. At each stage, the occluded attention transformer applies tighter intersection over union thresholds. We calculate each detection’s occluded attention to differentiate a person from other people or the background. Through comprehensive experiments, we demonstrated the benefits of our method by achieving state-of-the-art performance on two benchmark datasets. [Link to Paper]
Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks
Authors: Peri Akiva (Rutgers University), Matthew Purri (Rutgers University), Matthew Leotta (Kitware)

Qualitative results of our Texture Refinement Network (TeRN). It can be seen that similar textured pixels obtain similar feature activation intensity in the refined output. Notice how the building in the second row obtains similar activation throughout the concrete building pixel locations compared to the raw features output. Best viewed in zoom and color.
Poster Session: Motion, Tracking, Registration, Vision & X, and Theory
Self-supervised learning aims to learn image feature representations without using manually annotated labels, and is often a precursor step to obtaining initial network weights that ultimately contribute to faster convergence and superior performance of downstream tasks. While self-supervision reduces the domain gap between supervised and unsupervised learning without using labels, it still requires a strong inductive bias to downstream tasks for effective transfer learning. In this work, we present our material- and texture-based self-supervision method named MATTER (MATerial and TExture Representation Learning), which is inspired by classical material and texture methods. Material and texture can effectively describe any surface, including its tactile properties, color, and specularity. By extension, effective representation of material and texture can describe other semantic classes strongly associated with said material and texture. MATTER leverages multi-temporal, spatially aligned remote sensing imagery over unchanged regions to achieve consistency of material and texture representation. We show that our self-supervision pretraining method allows for up to 24.22% and 6.33% performance increase in unsupervised and fine-tuned setups, and up to 76% faster convergence on change detection, land cover classification, and semantic segmentation tasks. [Link to Paper]
Deep Decomposition for Stochastic Normal-Abnormal Transport
Authors: Peirong Liu (Department of Computer Science, University of North Carolina at Chapel Hill), Yueh Lee (Department of Radiology, University of North Carolina at Chapel Hill), Stephen Aylward (Kitware), Marc Niethammer (Department of Computer Science, University of North Carolina at Chapel Hill)
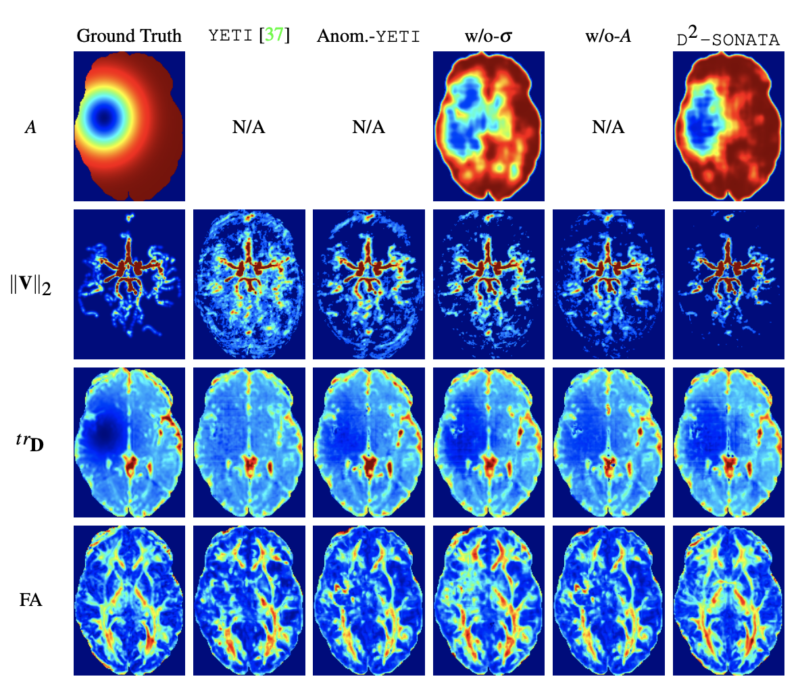
Reconstruction comparisons of one slice from a test case for 3D (ab-)normal brain advection-diffusion dataset. (∥V∥2 shown in maximum intensity projection)
In this paper, we discuss our development of a machine learning model built upon a stochastic advection-diffusion equation, which predicts the velocity and diffusion fields that drive 2D/3D image time-series of transport. We incorporated a model of transport atypicality, which isolates abnormal differences between expected normal transport behavior and the observed transport. In a medical context, a normal-abnormal decomposition can be used (e.g. to quantify pathologies). Our model also identifies the advection and diffusion contributions from the transport time-series and simultaneously predicts an anomaly value field to provide a decomposition into normal and abnormal advection and diffusion behavior. To achieve improved estimation performance for the velocity and diffusion-tensor fields underlying the advection-diffusion process and for the estimation of the anomaly fields, we create a 2D/3D anomaly-encoded advection-diffusion simulator, which allows for supervised learning. We further apply our model on a brain perfusion dataset from ischemic stroke patients via transfer learning. Extensive comparisons demonstrate that our model successfully distinguishes stroke lesions (abnormal) from normal brain regions, while reconstructing the underlying velocity and diffusion tensor fields. [Link to Paper]
Doppelgänger Saliency: Towards More Ethical Person Re-Identification
Authors: Brandon RichardWebster (Kitware), Brian Hu (Kitware), Keith Fieldhouse (Kitware), Anthony Hoogs (Kitware)
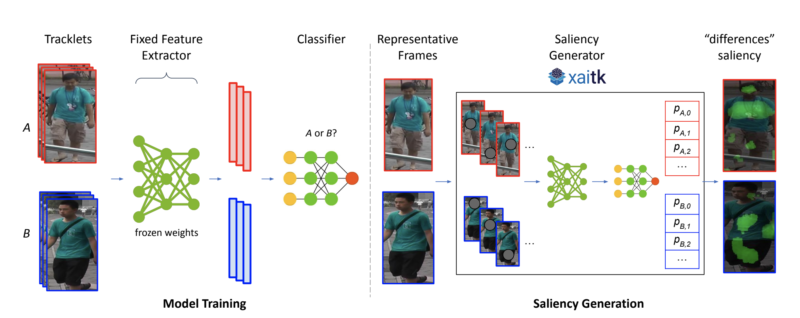
Model training and saliency generation. (Left) Tracklets A and B are used as input to a fixed feature extractor to generate chip-level features. A binary classifier is trained on these features to predict the probability of a chip belonging to tracklet A or B. (Right) A representative chip from each tracklet is fed into the saliency generator provided by the Explainable AI Toolkit (XAITK), which outputs the final “differences” saliency. At a high-level, the saliency generator masks out regions of the input image and inputs those masked images into the trained model and classifier. The computed output probabilities are then weighted-averaged to identify salient regions in each chip that represent the strongest visual differences between the two identities (shown overlaid as green regions).
Workshop Paper: Fair, Data Efficient And Trusted Computer Vision
Modern surveillance systems have become increasingly dependent on AI to provide actionable information for real-time decision making. A critical question relates to how these systems handle difficult ethical dilemmas, such as the misidentification of similar looking individuals. Potential misidentification can have severe negative consequences, as evidenced by recent headlines of individuals who were wrongly accused of crimes they did not commit based on false matches. A computer vision-based saliency algorithm is proposed to help identify pixel-level differences in pairs of images containing visually similar individuals, which we term “doppelgängers.” The computed saliency maps can alert human users of the presence of doppelgängers and provide important visual evidence to reduce the potential of false matches in these high-stakes situations. We show both qualitative and quantitative saliency results on doppelgängers found in a video-based person reidentification dataset (MARS) using three different state-of-the-art models. Our results suggest that this novel use of visual saliency can improve overall outcomes by helping human users and assuring the ethical and trusted operation of surveillance systems. [Link to Paper]
FishTrack22: An Ensemble Dataset for Automatic Tracking Evaluation
Authors: Matt Dawkins (Kitware), Matthew Lucero (California Department of Fish and Wildlife), Thompson Banez (California Department of Fish and Wildlife), Robin Faillettaz (French Research Institute for Exploitation of the Sea), Matthew Campbell (NOAA), Jack Prior (NOAA), Benjamin Richards (NOAA), Audrey Rollo (NOAA), Aashish Chaudhary (Kitware), Anthony Hoogs (Kitware), Mary Salvi (Kitware), Bryon Lewis (Kitware), Brandon Davis (Kitware), Neal Siekierski (Kitware)
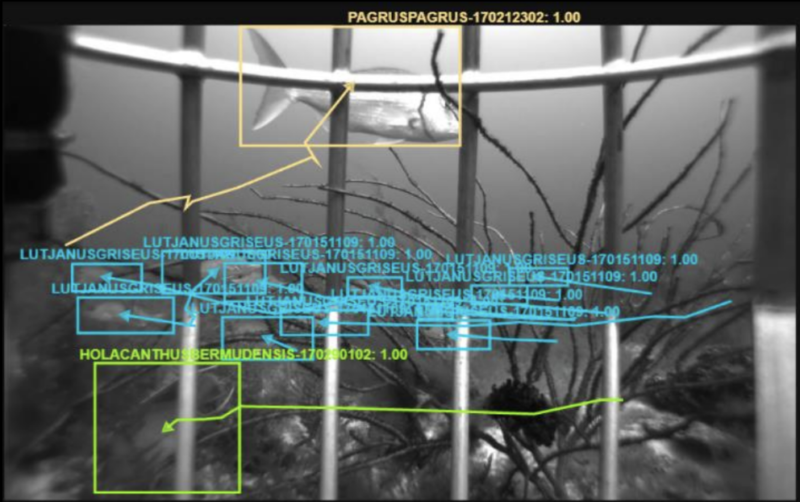
An example of one of the challenges facing underwater data collection, this image shows a high number of overlapping targets
Tracking fish underwater contains a number of unique challenges. The video can contain large schools comprised of many fish, dynamic natural backgrounds, variable target scales, volatile collection conditions, and non-fish moving confusors including debris, marine snow, and other organisms. There is also a lack of public datasets for algorithm evaluation available in this domain. FishTrack22 aims to address these challenges by providing a large quantity of expert-annotated fish groundtruth tracks in imagery and video collected across a range of different backgrounds, locations, collection conditions, and organizations. Approximately 1M bounding boxes across 45K tracks are included in the release of the ensemble, with potential for future growth in later releases.
Kitware’s Computer Vision Expertise Areas

Generative AI, LLMs, VLMs
Through our extensive experience in AI and our early adoption of deep learning, we have developed state-of-the-art capabilities in many current areas of generative AI including vision-language models (VLMs), retrieval-augmented generation (RAG), unsupervised training of multimodal foundation models, human-aligned reasoning in LLMs, image generation and style transfer, and image/video captioning. Our methods enable powerful, domain-specific applications based on the latest breakthroughs in generative AI, such as sample-efficient methods to adapt LLMs for human-aligned decision-making in the medical triage domain.
Dataset Collection and Annotation
The growth in deep learning has increased the demand for quality, labeled datasets needed to train models and algorithms. The power of these models and algorithms greatly depends on the quality of the training data available. Kitware has developed and cultivated dataset collection, annotation, and curation processes to build powerful capabilities that are unbiased and accurate, and not riddled with errors or false positives. Kitware can collect and source datasets and design custom annotation pipelines. We can annotate image, video, text and other data types using our in-house, professional annotators, some of whom have security clearances, or leverage third-party annotation resources when appropriate. Kitware also performs quality assurance that is driven by rigorous metrics to highlight when returns are diminishing. All of this data is managed by Kitware for continued use to the benefit of our customers, projects, and teams. Data collected or curated by Kitware includes the MEVA activity and MEVID person re-identification datasets, the VIRAT activity dataset, and the DARPA Invisible Headlights off-road autonomous vehicle navigation dataset.
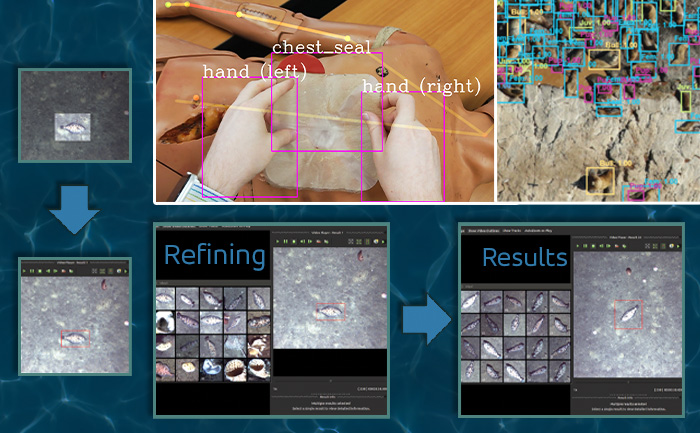
Interactive Artificial Intelligence and Human-Machine Teaming
DIY AI enables end users – analysts, operators, engineers – to rapidly build, test, and deploy novel AI solutions without having expertise in machine learning or even computer programming. Using Kitware’s interactive DIY AI toolkits, you can easily and efficiently train object classifiers using interactive query refinement, without drawing any bounding boxes. You are able to interactively improve existing capabilities to work optimally on your data for tasks such as object tracking, object detection, and event detection. Our toolkits also allow you to perform customized, highly specific searches of large image and video archives powered by cutting-edge AI methods. Currently, our DIY AI toolkits, such as VIAME, are used by scientists to analyze environmental images and video. Our defense-related versions are being used to address multiple domains and are provided with unlimited rights to the government. These toolkits enable long-term operational capabilities even as methods and technology evolve over time.
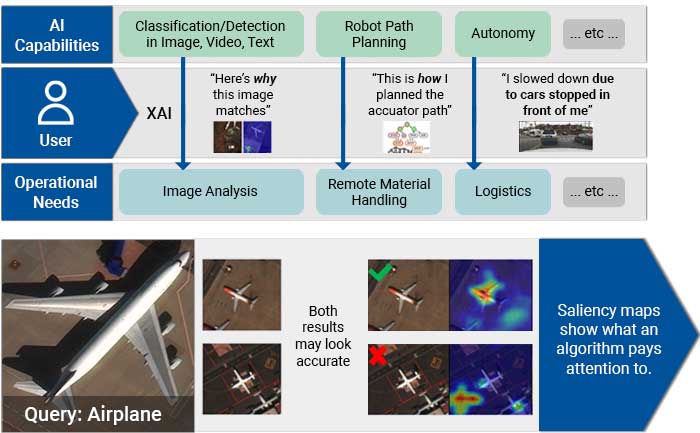
Responsible and Explainable AI
Integrating AI via human-machine teaming can greatly improve capabilities and competence as long as the team has a solid foundation of trust. To trust your AI partner, you must understand how the technology makes decisions and feel confident in those decisions. Kitware has developed powerful tools, such as the Explainable AI Toolkit (XAITK), to explore, quantify, and monitor the behavior of deep learning systems. Our team is also making deep neural networks more robust when faced with previously-unknown conditions, by leveraging AI test and evaluation (T&E) tools such as the Natural Robustness Toolkit (NRTK). In addition, our team is stepping outside of classic AI systems to address domain independent novelty identification, characterization, and adaptation to be able to acknowledge the introduction of unknowns. We also value the need to understand the ethical concerns, impacts, and risks of using AI. That’s why Kitware is developing methods to understand, formulate and test ethical reasoning algorithms for semi-autonomous applications. Kitware is proud to be part of the AISIC, a U.S. Department of Commerce Consortium dedicated to advancing the development and deployment of safe, trustworthy AI.

Multimedia Integrity Assurance
In the age of disinformation, it has become critical to validate the integrity and veracity of images, video, audio, and text sources. For instance, as photo-manipulation and photo-generation techniques are evolving rapidly, we continuously develop algorithms to detect, attribute, and characterize disinformation that can operate at scale on large data archives. These advanced AI algorithms allow us to detect inserted, removed, or altered objects, distinguish deep fakes from real images or videos, and identify deleted or inserted frames in videos in a way that exceeds human performance. We continue to extend this work through multiple government programs to detect manipulations in falsified media exploiting text, audio, images, and video.
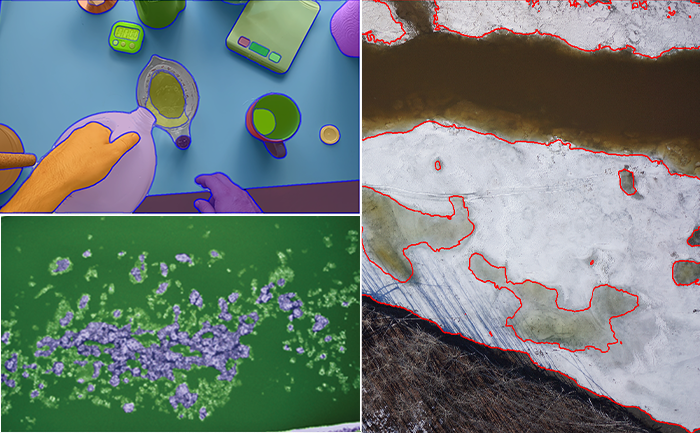
Semantic Segmentation
Kitware’s knowledge-driven scene understanding capabilities use deep learning techniques to accurately segment scenes into object types. In video, our unique approach defines objects by behavior, rather than appearance, so we can identify areas with similar behaviors. Through observing mover activity, our capabilities can segment a scene into functional object categories that may not be distinguishable by appearance alone. These capabilities are unsupervised so they automatically learn new functional categories without any manual annotations. Semantic scene understanding improves downstream capabilities such as threat detection, anomaly detection, change detection, 3D reconstruction, and more.

Super Resolution and Enhancement
Images and videos often come with unintended degradation – lens blur, sensor noise, environmental haze, compression artifacts, etc., or sometimes the relevant details are just beyond the resolution of the imagery. Kitware’s super-resolution techniques enhance single or multiple images to produce higher-resolution, improved images. We use novel methods to compensate for widely spaced views and illumination changes in overhead imagery, particulates and light attenuation in underwater imagery, and other challenges in a variety of domains. Our experience includes both powerful generative AI methods and simpler data-driven methods that avoid hallucination. The resulting higher-quality images enhance detail, enable advanced exploitation, and improve downstream automated analytics, such as object detection and classification.

Object Detection and Classification
Our video object detection and tracking tools are the culmination of years of continuous government investment. Deployed operationally in various domains, our mature suite of trackers can identify and track moving objects in many types of intelligence, surveillance, and reconnaissance data (ISR), including video from ground cameras, aerial platforms, underwater vehicles, robots, and satellites. These tools are able to perform in challenging settings and address difficult factors, such as low contrast, low resolution, moving cameras, occlusions, shadows, and high traffic density, through multi-frame track initialization, track linking, reverse-time tracking, recurrent neural networks, and other techniques. Our trackers can perform difficult tasks including ground camera tracking in congested scenes, real-time multi-target tracking in full-field WAMI and OPIR, and tracking people in far-field, non-cooperative scenarios.
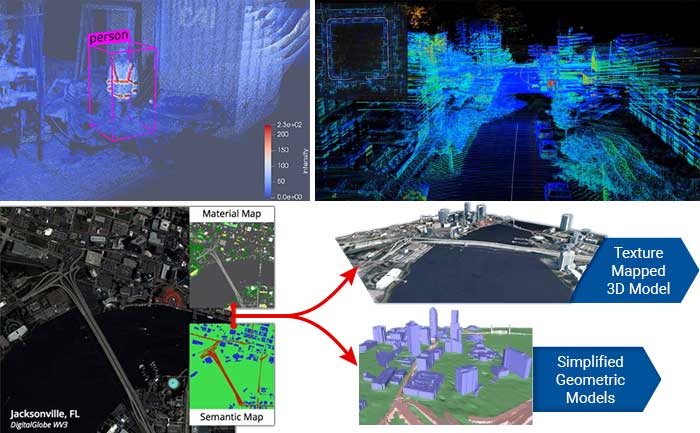
3D Reconstruction, Point Clouds, and Odometry
Kitware’s algorithms can extract 3D point clouds and surface meshes from video or images, without metadata or calibration information, or exploiting it when available. Operating on these 3D datasets or others from LiDAR and other depth sensors, our methods estimate scene semantics and 3D reconstruction jointly to maximize the accuracy of object classification, visual odometry, and 3D shape. Our open source 3D reconstruction toolkit, TeleSculptor, is continuously evolving to incorporate advancements to automatically analyze, visualize, and make measurements from images and video. LiDARView, another open source toolkit developed specifically for LiDAR data, performs 3D point cloud visualization and analysis in order to fuse data, techniques, and algorithms to produce SLAM and other capabilities.

Cyber-Physical Systems
The physical environment presents a unique, ever-changing set of challenges to any sensing and analytics system. Kitware has designed and constructed state-of-the-art cyber-physical systems that perform onboard, autonomous processing to gather data and extract critical information. Computer vision and deep learning technology allow our sensing and analytics systems to overcome the challenges of a complex, dynamic environment. They are customized to solve real-world problems in aerial, ground, and underwater scenarios. These capabilities have been field-tested and proven successful in programs funded by R&D organizations such as DARPA, AFRL, and NOAA.

Complex Activity, Event, and Threat Detection
Kitware’s tools detect high-value events, behaviors, and anomalies by analyzing low-level actions and events in complex environments. Using data from sUAS, fixed security cameras, WAMI, FMV, MTI, and various sensing modalities such as acoustic, Electro-Optical (EO), and Infrared (IR), our algorithms recognize actions like picking up objects, vehicles starting/stopping, and complex interactions such as vehicle transfers. We leverage both traditional computer vision deep learning models and Vision-Language Models (VLMs) for enhanced scene understanding and context-aware activity recognition. For sUAS, our tools provide precise tracking and activity analysis, while for fixed security cameras, they monitor and alert on unauthorized access, loitering, and other suspicious behaviors. Efficient data search capabilities support rapid identification of threats in massive video streams, even with detection errors or missing data. This ensures reliable activity recognition across a variety of operational settings, from large areas to high-traffic zones.
Computational Imaging
The success or failure of computer vision algorithms is often determined upstream, when images are captured with poor exposure or insufficient resolution that can negatively impact downstream detection, tracking, or recognition. Recognizing that an increasing share of imagery is consumed exclusively by software and may never be presented visually to a human viewer, computational imaging approaches co-optimize sensing and exploitation algorithms to achieve more efficient, effective outcomes than are possible with traditional cameras. Conceptually, this means thinking of the sensor as capturing a data structure from which downstream algorithms can extract meaningful information. Kitware’s customers in this growing area of emphasis include IARPA, AFRL, and MDA, for whom we’re mitigating atmospheric turbulence and performing recognition on unresolved targets for applications such as biometrics and missile detection.
Generative AI, LLMs, VLMs
Through our extensive experience in AI and our early adoption of deep learning, we have developed state-of-the-art capabilities in many current areas of generative AI including vision-language models (VLMs), retrieval-augmented generation (RAG), unsupervised training of multimodal foundation models, human-aligned reasoning in LLMs, image generation and style transfer, and image/video captioning. Our methods enable powerful, domain-specific applications based on the latest breakthroughs in generative AI, such as sample-efficient methods to adapt LLMs for human-aligned decision-making in the medical triage domain.
Dataset Collection and Annotation
The growth in deep learning has increased the demand for quality, labeled datasets needed to train models and algorithms. The power of these models and algorithms greatly depends on the quality of the training data available. Kitware has developed and cultivated dataset collection, annotation, and curation processes to build powerful capabilities that are unbiased and accurate, and not riddled with errors or false positives. Kitware can collect and source datasets and design custom annotation pipelines. We can annotate image, video, text and other data types using our in-house, professional annotators, some of whom have security clearances, or leverage third-party annotation resources when appropriate. Kitware also performs quality assurance that is driven by rigorous metrics to highlight when returns are diminishing. All of this data is managed by Kitware for continued use to the benefit of our customers, projects, and teams. Data collected or curated by Kitware includes the MEVA activity and MEVID person re-identification datasets, the VIRAT activity dataset, and the DARPA Invisible Headlights off-road autonomous vehicle navigation dataset.
Interactive Artificial Intelligence and Human-Machine Teaming
DIY AI enables end users – analysts, operators, engineers – to rapidly build, test, and deploy novel AI solutions without having expertise in machine learning or even computer programming. Using Kitware’s interactive DIY AI toolkits, you can easily and efficiently train object classifiers using interactive query refinement, without drawing any bounding boxes. You are able to interactively improve existing capabilities to work optimally on your data for tasks such as object tracking, object detection, and event detection. Our toolkits also allow you to perform customized, highly specific searches of large image and video archives powered by cutting-edge AI methods. Currently, our DIY AI toolkits, such as VIAME, are used by scientists to analyze environmental images and video. Our defense-related versions are being used to address multiple domains and are provided with unlimited rights to the government. These toolkits enable long-term operational capabilities even as methods and technology evolve over time.
Responsible and Explainable AI
Integrating AI via human-machine teaming can greatly improve capabilities and competence as long as the team has a solid foundation of trust. To trust your AI partner, you must understand how the technology makes decisions and feel confident in those decisions. Kitware has developed powerful tools, such as the Explainable AI Toolkit (XAITK), to explore, quantify, and monitor the behavior of deep learning systems. Our team is also making deep neural networks more robust when faced with previously-unknown conditions, by leveraging AI test and evaluation (T&E) tools such as the Natural Robustness Toolkit (NRTK). In addition, our team is stepping outside of classic AI systems to address domain independent novelty identification, characterization, and adaptation to be able to acknowledge the introduction of unknowns. We also value the need to understand the ethical concerns, impacts, and risks of using AI. That’s why Kitware is developing methods to understand, formulate and test ethical reasoning algorithms for semi-autonomous applications. Kitware is proud to be part of the AISIC, a U.S. Department of Commerce Consortium dedicated to advancing the development and deployment of safe, trustworthy AI.
Multimedia Integrity Assurance
In the age of disinformation, it has become critical to validate the integrity and veracity of images, video, audio, and text sources. For instance, as photo-manipulation and photo-generation techniques are evolving rapidly, we continuously develop algorithms to detect, attribute, and characterize disinformation that can operate at scale on large data archives. These advanced AI algorithms allow us to detect inserted, removed, or altered objects, distinguish deep fakes from real images or videos, and identify deleted or inserted frames in videos in a way that exceeds human performance. We continue to extend this work through multiple government programs to detect manipulations in falsified media exploiting text, audio, images, and video.
Semantic Segmentation
Kitware’s knowledge-driven scene understanding capabilities use deep learning techniques to accurately segment scenes into object types. In video, our unique approach defines objects by behavior, rather than appearance, so we can identify areas with similar behaviors. Through observing mover activity, our capabilities can segment a scene into functional object categories that may not be distinguishable by appearance alone. These capabilities are unsupervised so they automatically learn new functional categories without any manual annotations. Semantic scene understanding improves downstream capabilities such as threat detection, anomaly detection, change detection, 3D reconstruction, and more.
Super Resolution and Enhancement
Images and videos often come with unintended degradation – lens blur, sensor noise, environmental haze, compression artifacts, etc., or sometimes the relevant details are just beyond the resolution of the imagery. Kitware’s super-resolution techniques enhance single or multiple images to produce higher-resolution, improved images. We use novel methods to compensate for widely spaced views and illumination changes in overhead imagery, particulates and light attenuation in underwater imagery, and other challenges in a variety of domains. Our experience includes both powerful generative AI methods and simpler data-driven methods that avoid hallucination. The resulting higher-quality images enhance detail, enable advanced exploitation, and improve downstream automated analytics, such as object detection and classification.
Object Detection and Classification
Our video object detection and tracking tools are the culmination of years of continuous government investment. Deployed operationally in various domains, our mature suite of trackers can identify and track moving objects in many types of intelligence, surveillance, and reconnaissance data (ISR), including video from ground cameras, aerial platforms, underwater vehicles, robots, and satellites. These tools are able to perform in challenging settings and address difficult factors, such as low contrast, low resolution, moving cameras, occlusions, shadows, and high traffic density, through multi-frame track initialization, track linking, reverse-time tracking, recurrent neural networks, and other techniques. Our trackers can perform difficult tasks including ground camera tracking in congested scenes, real-time multi-target tracking in full-field WAMI and OPIR, and tracking people in far-field, non-cooperative scenarios.
3D Reconstruction, Point Clouds, and Odometry
Kitware’s algorithms can extract 3D point clouds and surface meshes from video or images, without metadata or calibration information, or exploiting it when available. Operating on these 3D datasets or others from LiDAR and other depth sensors, our methods estimate scene semantics and 3D reconstruction jointly to maximize the accuracy of object classification, visual odometry, and 3D shape. Our open source 3D reconstruction toolkit, TeleSculptor, is continuously evolving to incorporate advancements to automatically analyze, visualize, and make measurements from images and video. LiDARView, another open source toolkit developed specifically for LiDAR data, performs 3D point cloud visualization and analysis in order to fuse data, techniques, and algorithms to produce SLAM and other capabilities.
Cyber-Physical Systems
The physical environment presents a unique, ever-changing set of challenges to any sensing and analytics system. Kitware has designed and constructed state-of-the-art cyber-physical systems that perform onboard, autonomous processing to gather data and extract critical information. Computer vision and deep learning technology allow our sensing and analytics systems to overcome the challenges of a complex, dynamic environment. They are customized to solve real-world problems in aerial, ground, and underwater scenarios. These capabilities have been field-tested and proven successful in programs funded by R&D organizations such as DARPA, AFRL, and NOAA.
Complex Activity, Event, and Threat Detection
Kitware’s tools detect high-value events, behaviors, and anomalies by analyzing low-level actions and events in complex environments. Using data from sUAS, fixed security cameras, WAMI, FMV, MTI, and various sensing modalities such as acoustic, Electro-Optical (EO), and Infrared (IR), our algorithms recognize actions like picking up objects, vehicles starting/stopping, and complex interactions such as vehicle transfers. We leverage both traditional computer vision deep learning models and Vision-Language Models (VLMs) for enhanced scene understanding and context-aware activity recognition. For sUAS, our tools provide precise tracking and activity analysis, while for fixed security cameras, they monitor and alert on unauthorized access, loitering, and other suspicious behaviors. Efficient data search capabilities support rapid identification of threats in massive video streams, even with detection errors or missing data. This ensures reliable activity recognition across a variety of operational settings, from large areas to high-traffic zones.
Computational Imaging
The success or failure of computer vision algorithms is often determined upstream, when images are captured with poor exposure or insufficient resolution that can negatively impact downstream detection, tracking, or recognition. Recognizing that an increasing share of imagery is consumed exclusively by software and may never be presented visually to a human viewer, computational imaging approaches co-optimize sensing and exploitation algorithms to achieve more efficient, effective outcomes than are possible with traditional cameras. Conceptually, this means thinking of the sensor as capturing a data structure from which downstream algorithms can extract meaningful information. Kitware’s customers in this growing area of emphasis include IARPA, AFRL, and MDA, for whom we’re mitigating atmospheric turbulence and performing recognition on unresolved targets for applications such as biometrics and missile detection.
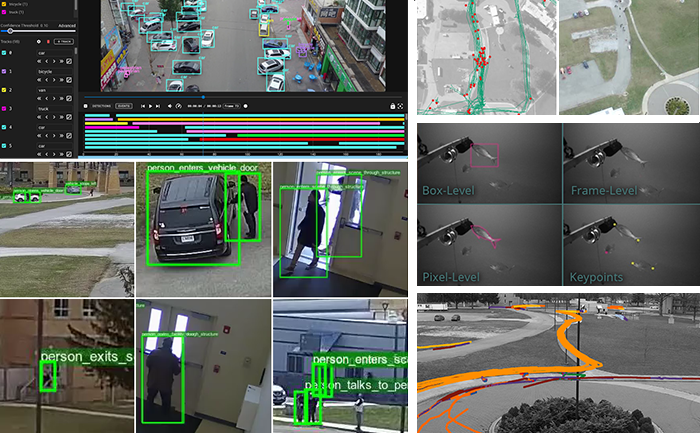
Kitware’s Automated Image and Video Analysis Platforms




Kitware is hiring!
You can help us solve our customers’ challenging problems. In joining our computer vision team, you will apply AI and deep learning to discover cutting-edge solutions. You will also find yourself surrounded by passionate people who are industry experts. Learn more about what it’s like to work at Kitware, see our open positions, and apply today.